 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilWhisper: Efficient Distillation of Multi-task Speech Models via Language-Specific Experts
Nov 02, 2023



Whisper is a multitask and multilingual speech model covering 99 languages. It yields commendable automatic speech recognition (ASR) results in a subset of its covered languages, but the model still under-performs on a non-negligible number of under-represented languages, a problem exacerbated in smaller model versions. In this work, we propose DistilWhisper, an approach able to bridge the performance gap in ASR for these languages while retaining the advantages of multitask and multilingual capabilities. Our approach involves two key strategies: lightweight modular ASR fine-tuning of whisper-small using language-specific experts, and knowledge distillation from whisper-large-v2. This dual approach allows us to effectively boost ASR performance while keeping the robustness inherited from the multitask and multilingual pre-training. Results demonstrate that our approach is more effective than standard fine-tuning or LoRA adapters, boosting performance in the targeted languages for both in- and out-of-domain test sets, while introducing only a negligible parameter overhead at inference.
Empirical study of pretrained multilingual language models for zero-shot cross-lingual generation
Oct 15, 2023



Zero-shot cross-lingual generation assumes finetuning the multilingual pretrained language model (mPLM) on a generation task in one language and then using it to make predictions for this task in other languages. Previous works notice a frequent problem of generation in a wrong language and propose approaches to address it, usually using mT5 as a backbone model. In this work, we test alternative mPLMs, such as mBART and NLLB, considering full finetuning and parameter-efficient finetuning with adapters. We find that mBART with adapters performs similarly to mT5 of the same size, and NLLB can be competitive in some cases. We also underline the importance of tuning learning rate used for finetuning, which helps to alleviate the problem of generation in the wrong language.
Long-Tail Theory under Gaussian Mixtures
Jul 24, 2023



We suggest a simple Gaussian mixture model for data generation that complies with Feldman's long tail theory (2020). We demonstrate that a linear classifier cannot decrease the generalization error below a certain level in the proposed model, whereas a nonlinear classifier with a memorization capacity can. This confirms that for long-tailed distributions, rare training examples must be considered for optimal generalization to new data. Finally, we show that the performance gap between linear and nonlinear models can be lessened as the tail becomes shorter in the subpopulation frequency distribution, as confirmed by experiments on synthetic and real data.
BLOOM+1: Adding Language Support to BLOOM for Zero-Shot Prompting
Dec 19, 2022



The BLOOM model is a large open-source multilingual language model capable of zero-shot learning, but its pretraining was limited to 46 languages. To improve its zero-shot performance on unseen languages, it is desirable to adapt BLOOM, but previous works have only explored adapting small language models. In this work, we apply existing language adaptation strategies to BLOOM and benchmark its zero-shot prompting performance on eight new languages. We find language adaptation to be effective at improving zero-shot performance in new languages. Surprisingly, adapter-based finetuning is more effective than continued pretraining for large models. In addition, we discover that prompting performance is not significantly affected by language specifics, such as the writing system. It is primarily determined by the size of the language adaptation data. We also add new languages to BLOOMZ, which is a multitask finetuned version of BLOOM capable of following task instructions zero-shot. We find including a new language in the multitask fine-tuning mixture to be the most effective method to teach BLOOMZ a new language. We conclude that with sufficient training data language adaptation can generalize well to diverse languages. Our code is available at \url{https://github.com/bigscience-workshop/multilingual-modeling/}.
Memory-efficient NLLB-200: Language-specific Expert Pruning of a Massively Multilingual Machine Translation Model
Dec 19, 2022Compared to conventional bilingual translation systems, massively multilingual machine translation is appealing because a single model can translate into multiple languages and benefit from knowledge transfer for low resource languages. On the other hand, massively multilingual models suffer from the curse of multilinguality, unless scaling their size massively, which increases their training and inference costs. Sparse Mixture-of-Experts models are a way to drastically increase model capacity without the need for a proportional amount of computing. The recently released NLLB-200 is an example of such a model. It covers 202 languages but requires at least four 32GB GPUs just for inference. In this work, we propose a pruning method that allows the removal of up to 80\% of experts with a negligible loss in translation quality, which makes it feasible to run the model on a single 32GB GPU. Further analysis suggests that our pruning metrics allow to identify language-specific experts and prune non-relevant experts for a given language pair.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
What Do Compressed Multilingual Machine Translation Models Forget?
May 22, 2022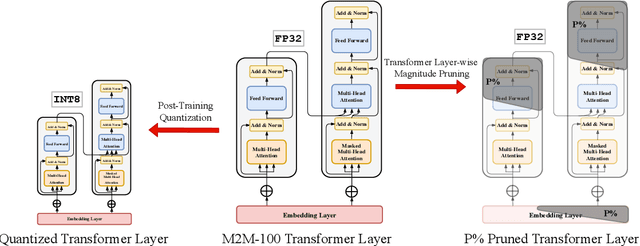

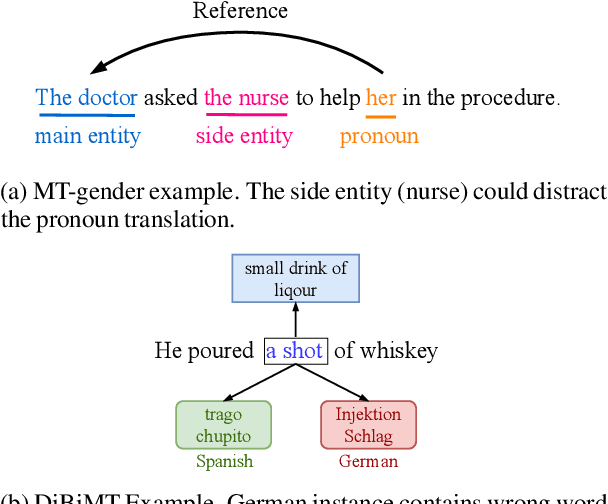
Recently, very large pre-trained models achieve state-of-the-art results in various natural language processing (NLP) tasks, but their size makes it more challenging to apply them in resource-constrained environments. Compression techniques allow to drastically reduce the size of the model and therefore its inference time with negligible impact on top-tier metrics. However, the general performance hides a drastic performance drop on under-represented features, which could result in the amplification of biases encoded by the model. In this work, we analyze the impacts of compression methods on Multilingual Neural Machine Translation models (MNMT) for various language groups and semantic features by extensive analysis of compressed models on different NMT benchmarks, e.g. FLORES-101, MT-Gender, and DiBiMT. Our experiments show that the performance of under-represented languages drops significantly, while the average BLEU metric slightly decreases. Interestingly, the removal of noisy memorization with the compression leads to a significant improvement for some medium-resource languages. Finally, we demonstrate that the compression amplifies intrinsic gender and semantic biases, even in high-resource languages.
DaLC: Domain Adaptation Learning Curve Prediction for Neural Machine Translation
Apr 20, 2022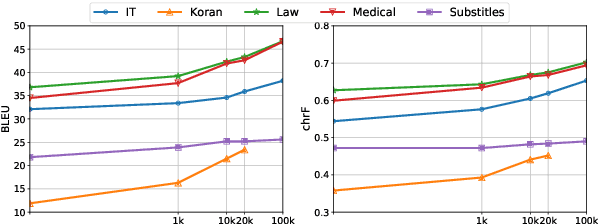
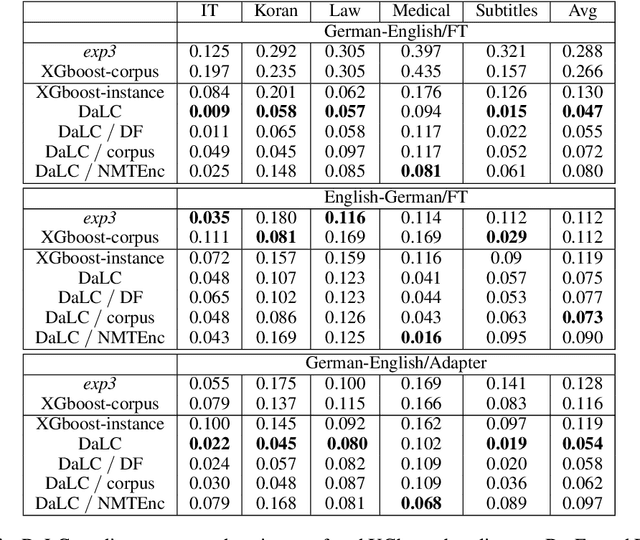
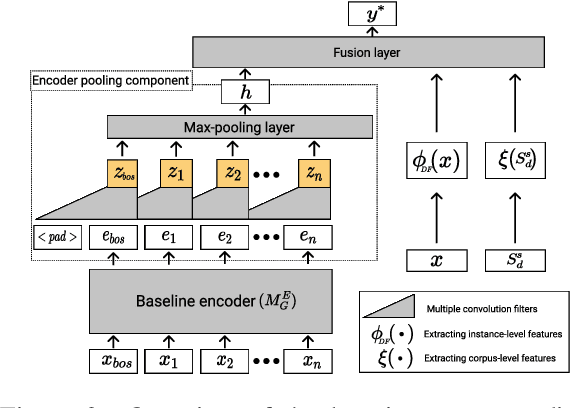
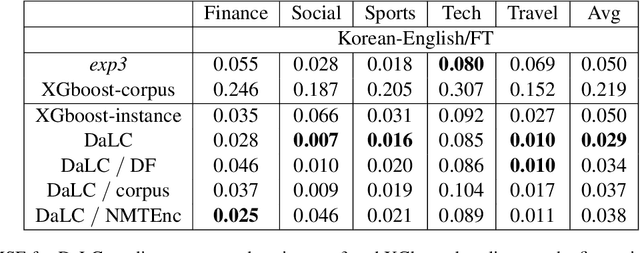
Domain Adaptation (DA) of Neural Machine Translation (NMT) model often relies on a pre-trained general NMT model which is adapted to the new domain on a sample of in-domain parallel data. Without parallel data, there is no way to estimate the potential benefit of DA, nor the amount of parallel samples it would require. It is however a desirable functionality that could help MT practitioners to make an informed decision before investing resources in dataset creation. We propose a Domain adaptation Learning Curve prediction (DaLC) model that predicts prospective DA performance based on in-domain monolingual samples in the source language. Our model relies on the NMT encoder representations combined with various instance and corpus-level features. We demonstrate that instance-level is better able to distinguish between different domains compared to corpus-level frameworks proposed in previous studies. Finally, we perform in-depth analyses of the results highlighting the limitations of our approach, and provide directions for future research.
Adapting BigScience Multilingual Model to Unseen Languages
Apr 11, 2022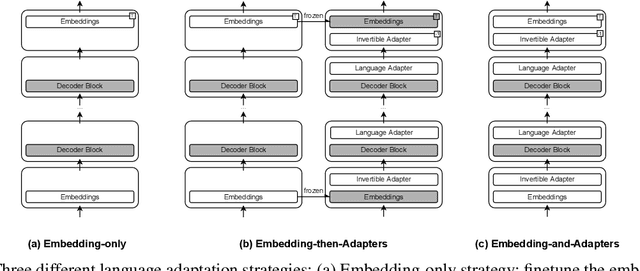

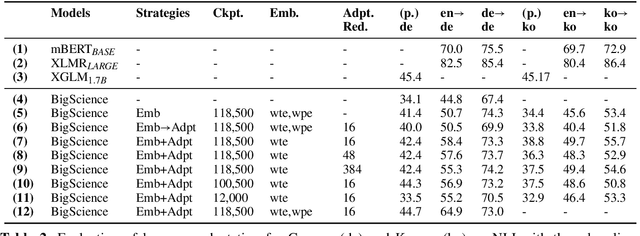
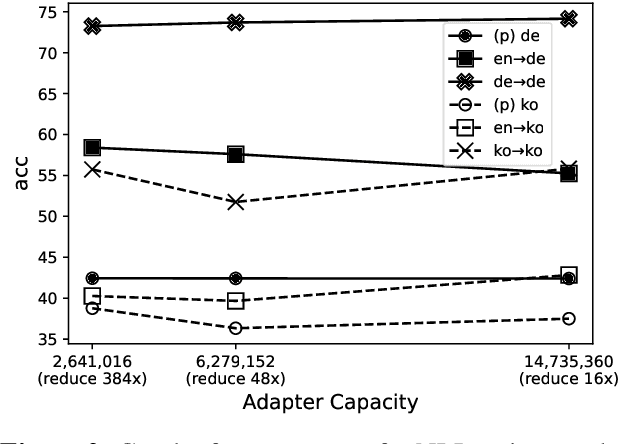
We benchmark different strategies of adding new languages (German and Korean) into the BigScience's pretrained multilingual language model with 1.3 billion parameters that currently supports 13 languages. We investigate the factors that affect the language adaptability of the model and the trade-offs between computational costs and expected performance.
Zero-Shot and Few-Shot Classification of Biomedical Articles in Context of the COVID-19 Pandemic
Jan 11, 2022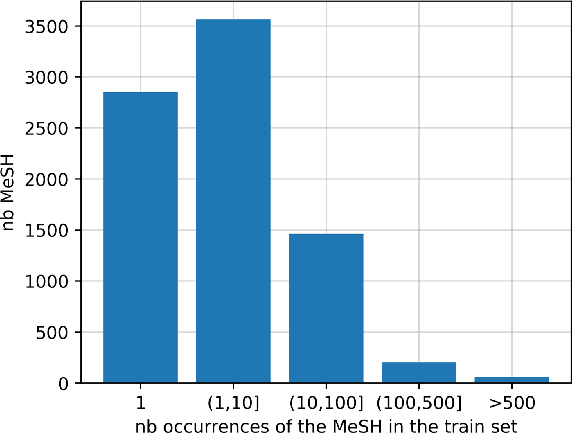
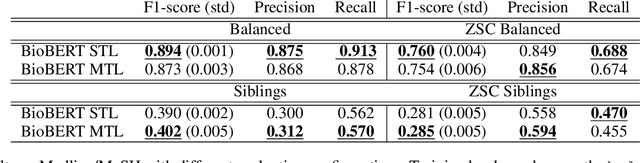
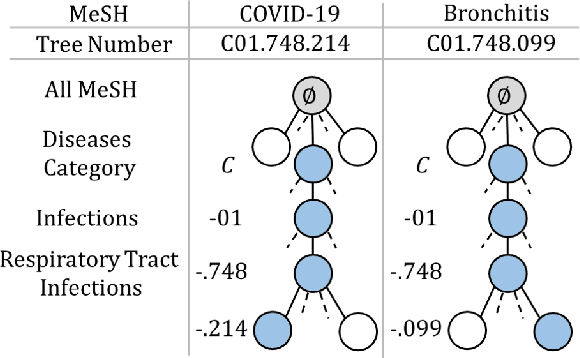
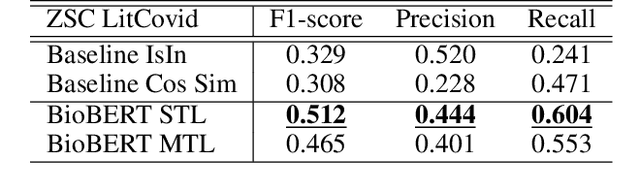
MeSH (Medical Subject Headings) is a large thesaurus created by the National Library of Medicine and used for fine-grained indexing of publications in the biomedical domain. In the context of the COVID-19 pandemic, MeSH descriptors have emerged in relation to articles published on the corresponding topic. Zero-shot classification is an adequate response for timely labeling of the stream of papers with MeSH categories. In this work, we hypothesise that rich semantic information available in MeSH has potential to improve BioBERT representations and make them more suitable for zero-shot/few-shot tasks. We frame the problem as determining if MeSH term definitions, concatenated with paper abstracts are valid instances or not, and leverage multi-task learning to induce the MeSH hierarchy in the representations thanks to a seq2seq task. Results establish a baseline on the MedLine and LitCovid datasets, and probing shows that the resulting representations convey the hierarchical relations present in MeSH.