 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresenting and Reasoning with Multi-Stakeholder Qualitative Preference Queries
Jul 30, 2023



Many decision-making scenarios, e.g., public policy, healthcare, business, and disaster response, require accommodating the preferences of multiple stakeholders. We offer the first formal treatment of reasoning with multi-stakeholder qualitative preferences in a setting where stakeholders express their preferences in a qualitative preference language, e.g., CP-net, CI-net, TCP-net, CP-Theory. We introduce a query language for expressing queries against such preferences over sets of outcomes that satisfy specified criteria, e.g., $\mlangpref{\psi_1}{\psi_2}{A}$ (read loosely as the set of outcomes satisfying $\psi_1$ that are preferred over outcomes satisfying $\psi_2$ by a set of stakeholders $A$). Motivated by practical application scenarios, we introduce and analyze several alternative semantics for such queries, and examine their interrelationships. We provide a provably correct algorithm for answering multi-stakeholder qualitative preference queries using model checking in alternation-free $\mu$-calculus. We present experimental results that demonstrate the feasibility of our approach.
Forecasting User Interests Through Topic Tag Predictions in Online Health Communities
Nov 05, 2022The increasing reliance on online communities for healthcare information by patients and caregivers has led to the increase in the spread of misinformation, or subjective, anecdotal and inaccurate or non-specific recommendations, which, if acted on, could cause serious harm to the patients. Hence, there is an urgent need to connect users with accurate and tailored health information in a timely manner to prevent such harm. This paper proposes an innovative approach to suggesting reliable information to participants in online communities as they move through different stages in their disease or treatment. We hypothesize that patients with similar histories of disease progression or course of treatment would have similar information needs at comparable stages. Specifically, we pose the problem of predicting topic tags or keywords that describe the future information needs of users based on their profiles, traces of their online interactions within the community (past posts, replies) and the profiles and traces of online interactions of other users with similar profiles and similar traces of past interaction with the target users. The result is a variant of the collaborative information filtering or recommendation system tailored to the needs of users of online health communities. We report results of our experiments on an expert curated data set which demonstrate the superiority of the proposed approach over the state of the art baselines with respect to accurate and timely prediction of topic tags (and hence information sources of interest).
Zooming Into the Darknet: Characterizing Internet Background Radiation and its Structural Changes
Aug 05, 2021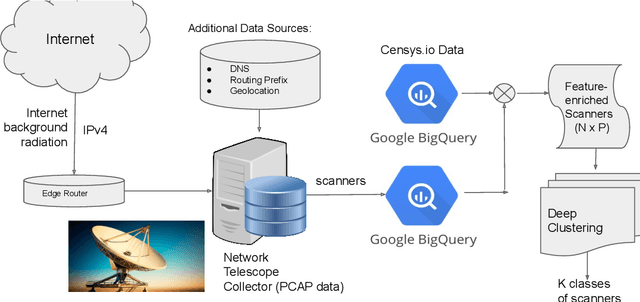

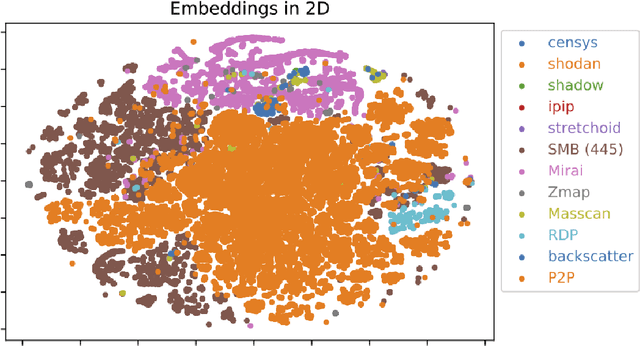

Network telescopes or "Darknets" provide a unique window into Internet-wide malicious activities associated with malware propagation, denial of service attacks, scanning performed for network reconnaissance, and others. Analyses of the resulting data can provide actionable insights to security analysts that can be used to prevent or mitigate cyber-threats. Large Darknets, however, observe millions of nefarious events on a daily basis which makes the transformation of the captured information into meaningful insights challenging. We present a novel framework for characterizing Darknet behavior and its temporal evolution aiming to address this challenge. The proposed framework: (i) Extracts a high dimensional representation of Darknet events composed of features distilled from Darknet data and other external sources; (ii) Learns, in an unsupervised fashion, an information-preserving low-dimensional representation of these events (using deep representation learning) that is amenable to clustering; (iv) Performs clustering of the scanner data in the resulting representation space and provides interpretable insights using optimal decision trees; and (v) Utilizes the clustering outcomes as "signatures" that can be used to detect structural changes in the Darknet activities. We evaluate the proposed system on a large operational Network Telescope and demonstrate its ability to detect real-world, high-impact cybersecurity incidents.
Explainable Multivariate Time Series Classification: A Deep Neural Network Which Learns To Attend To Important Variables As Well As Informative Time Intervals
Nov 23, 2020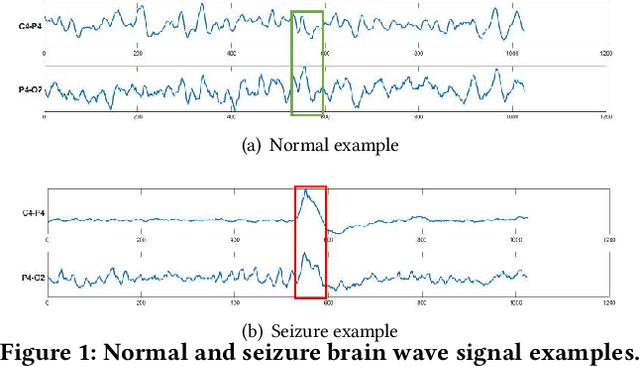

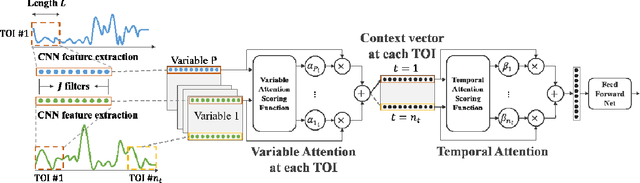

Time series data is prevalent in a wide variety of real-world applications and it calls for trustworthy and explainable models for people to understand and fully trust decisions made by AI solutions. We consider the problem of building explainable classifiers from multi-variate time series data. A key criterion to understand such predictive models involves elucidating and quantifying the contribution of time varying input variables to the classification. Hence, we introduce a novel, modular, convolution-based feature extraction and attention mechanism that simultaneously identifies the variables as well as time intervals which determine the classifier output. We present results of extensive experiments with several benchmark data sets that show that the proposed method outperforms the state-of-the-art baseline methods on multi-variate time series classification task. The results of our case studies demonstrate that the variables and time intervals identified by the proposed method make sense relative to available domain knowledge.
A Causal Lens for Peeking into Black Box Predictive Models: Predictive Model Interpretation via Causal Attribution
Aug 01, 2020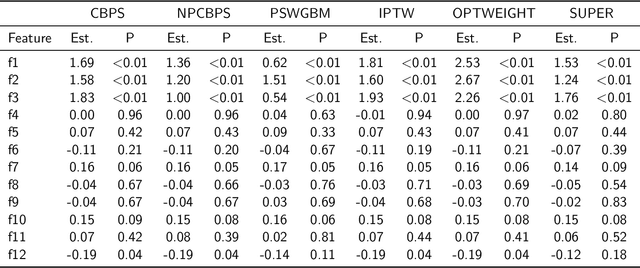
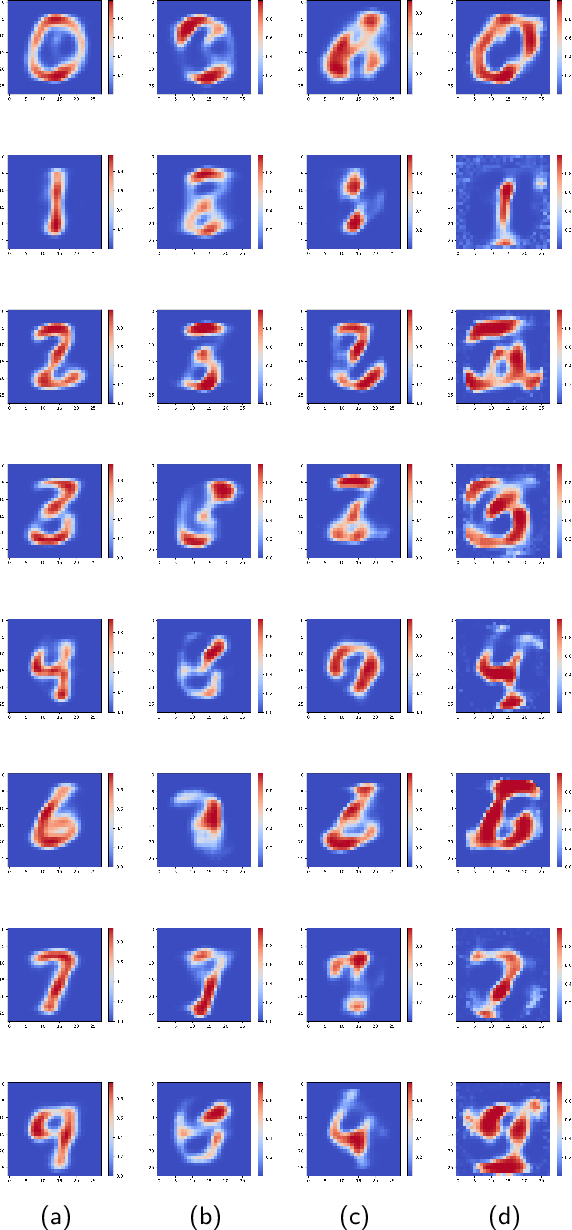
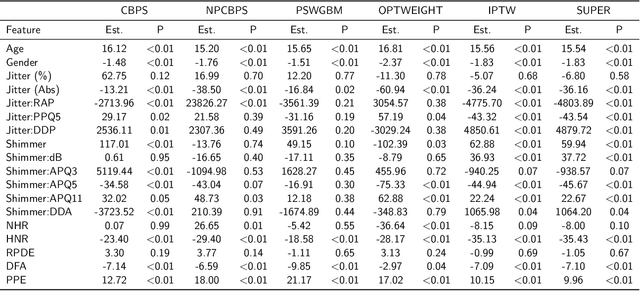
With the increasing adoption of predictive models trained using machine learning across a wide range of high-stakes applications, e.g., health care, security, criminal justice, finance, and education, there is a growing need for effective techniques for explaining such models and their predictions. We aim to address this problem in settings where the predictive model is a black box; That is, we can only observe the response of the model to various inputs, but have no knowledge about the internal structure of the predictive model, its parameters, the objective function, and the algorithm used to optimize the model. We reduce the problem of interpreting a black box predictive model to that of estimating the causal effects of each of the model inputs on the model output, from observations of the model inputs and the corresponding outputs. We estimate the causal effects of model inputs on model output using variants of the Rubin Neyman potential outcomes framework for estimating causal effects from observational data. We show how the resulting causal attribution of responsibility for model output to the different model inputs can be used to interpret the predictive model and to explain its predictions. We present results of experiments that demonstrate the effectiveness of our approach to the interpretation of black box predictive models via causal attribution in the case of deep neural network models trained on one synthetic data set (where the input variables that impact the output variable are known by design) and two real-world data sets: Handwritten digit classification, and Parkinson's disease severity prediction. Because our approach does not require knowledge about the predictive model algorithm and is free of assumptions regarding the black box predictive model except that its input-output responses be observable, it can be applied, in principle, to any black box predictive model.
Longitudinal Deep Kernel Gaussian Process Regression
Jun 09, 2020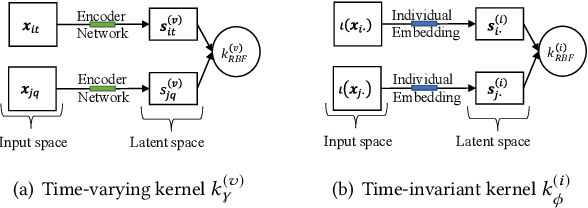
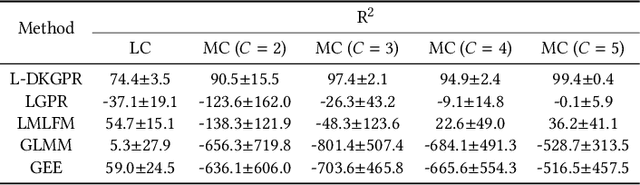
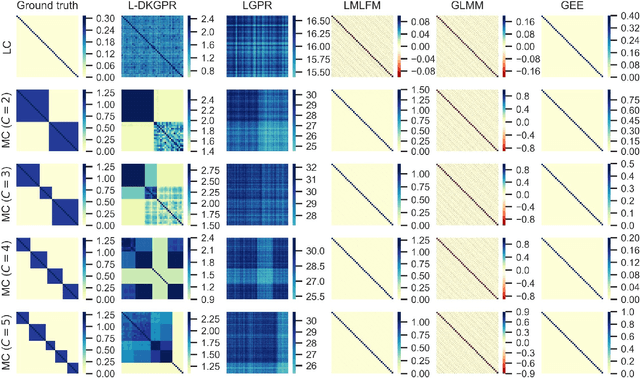

Gaussian processes offer an attractive framework for predictive modeling from longitudinal data, i.e., irregularly sampled, sparse observations from a set of individuals over time. However, such methods have two key shortcomings: (i) They rely on ad hoc heuristics or expensive trial and error to choose the effective kernels, and (ii) They fail to handle multilevel correlation structure in the data. We introduce Longitudinal deep kernel Gaussian process regression (L-DKGPR), which to the best of our knowledge, is the only method to overcome these limitations by fully automating the discovery of complex multilevel correlation structure from longitudinal data. Specifically, L-DKGPR eliminates the need for ad hoc heuristics or trial and error using a novel adaptation of deep kernel learning that combines the expressive power of deep neural networks with the flexibility of non-parametric kernel methods. L-DKGPR effectively learns the multilevel correlation with a novel addictive kernel that simultaneously accommodates both time-varying and the time-invariant effects. We derive an efficient algorithm to train L-DKGPR using latent space inducing points and variational inference. Results of extensive experiments on several benchmark data sets demonstrate that L-DKGPR significantly outperforms the state-of-the-art longitudinal data analysis (LDA) methods.
Towards Robust Relational Causal Discovery
Dec 05, 2019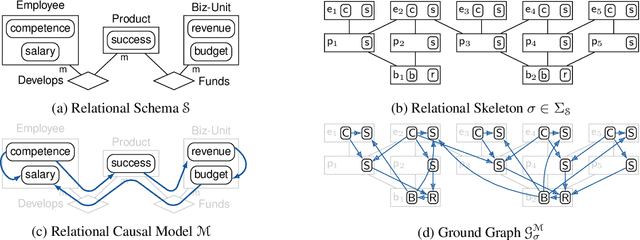
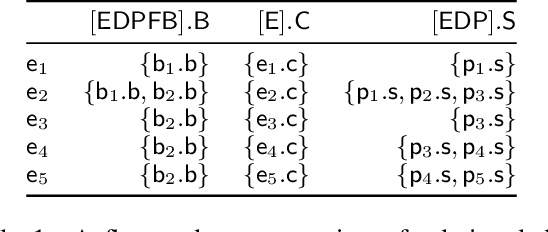

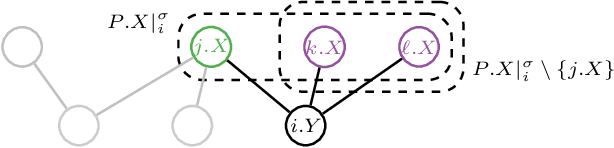
We consider the problem of learning causal relationships from relational data. Existing approaches rely on queries to a relational conditional independence (RCI) oracle to establish and orient causal relations in such a setting. In practice, queries to a RCI oracle have to be replaced by reliable tests for RCI against available data. Relational data present several unique challenges in testing for RCI. We study the conditions under which traditional iid-based conditional independence (CI) tests yield reliable answers to RCI queries against relational data. We show how to conduct CI tests against relational data to robustly recover the underlying relational causal structure. Results of our experiments demonstrate the effectiveness of our proposed approach.
* 14 pages
Algorithmic Bias in Recidivism Prediction: A Causal Perspective
Nov 24, 2019
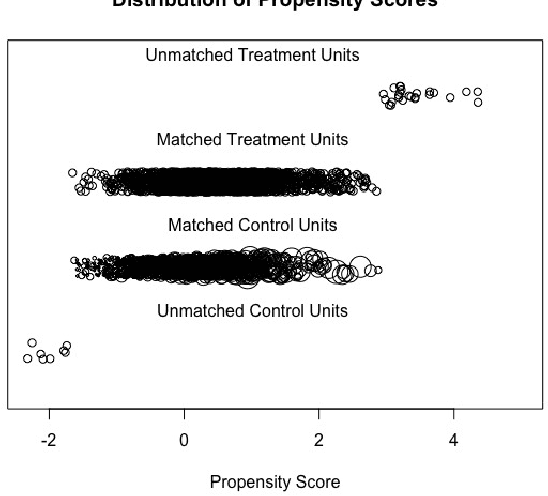
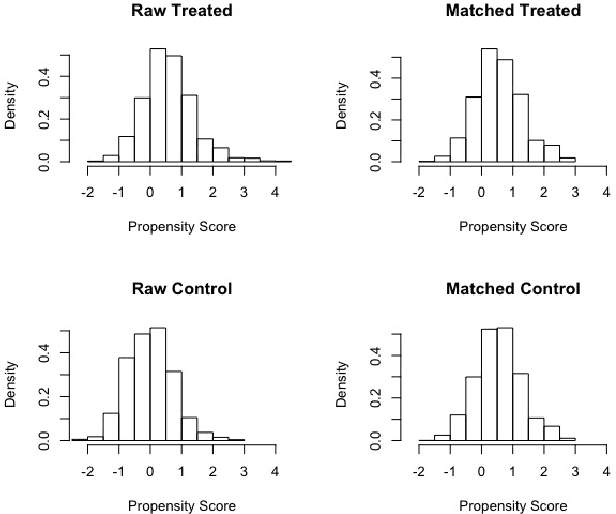
ProPublica's analysis of recidivism predictions produced by Correctional Offender Management Profiling for Alternative Sanctions (COMPAS) software tool for the task, has shown that the predictions were racially biased against African American defendants. We analyze the COMPAS data using a causal reformulation of the underlying algorithmic fairness problem. Specifically, we assess whether COMPAS exhibits racial bias against African American defendants using FACT, a recently introduced causality grounded measure of algorithmic fairness. We use the Neyman-Rubin potential outcomes framework for causal inference from observational data to estimate FACT from COMPAS data. Our analysis offers strong evidence that COMPAS exhibits racial bias against African American defendants. We further show that the FACT estimates from COMPAS data are robust in the presence of unmeasured confounding.
LMLFM: Longitudinal Multi-Level Factorization Machine
Nov 21, 2019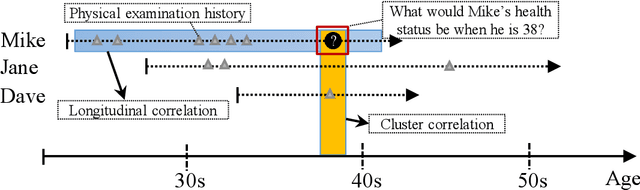

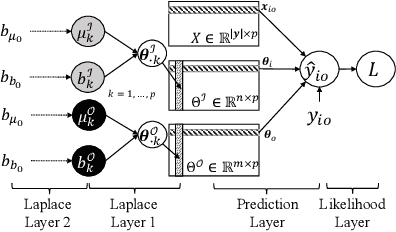
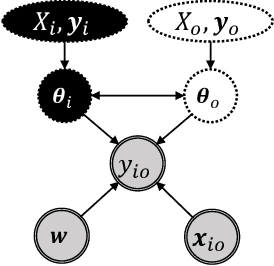
We consider the problem of learning predictive models from longitudinal data, consisting of irregularly repeated, sparse observations from a set of individuals over time. Such data often exhibit {\em longitudinal correlation} (LC) (correlations among observations for each individual over time), {\em cluster correlation} (CC) (correlations among individuals that have similar characteristics), or both. These correlations are often accounted for using {\em mixed effects models} that include {\em fixed effects} and {\em random effects}, where the fixed effects capture the regression parameters that are shared by all individuals, whereas random effects capture those parameters that vary across individuals. However, the current state-of-the-art methods are unable to select the most predictive fixed effects and random effects from a large number of variables, while accounting for complex correlation structure in the data and non-linear interactions among the variables. We propose Longitudinal Multi-Level Factorization Machine (LMLFM), to the best of our knowledge, the first model to address these challenges in learning predictive models from longitudinal data. We establish the convergence properties, and analyze the computational complexity, of LMLFM. We present results of experiments with both simulated and real-world longitudinal data which show that LMLFM outperforms the state-of-the-art methods in terms of predictive accuracy, variable selection ability, and scalability to data with large number of variables. The code and supplemental material is available at \url{https://github.com/junjieliang672/LMLFM}.
The Dynamical Gaussian Process Latent Variable Model in the Longitudinal Scenario
Sep 25, 2019

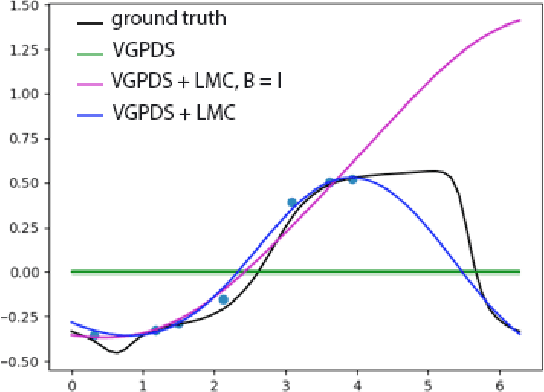
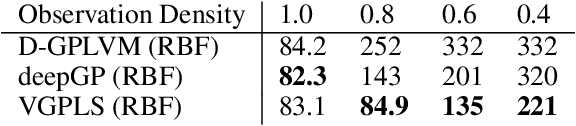
The Dynamical Gaussian Process Latent Variable Models provide an elegant non-parametric framework for learning the low dimensional representations of the high-dimensional time-series. Real world observational studies, however, are often ill-conditioned: the observations can be noisy, not assuming the luxury of relatively complete and equally spaced like those in time series. Such conditions make it difficult to learn reasonable representations in the high dimensional longitudinal data set by way of Gaussian Process Latent Variable Model as well as other dimensionality reduction procedures. In this study, we approach the inference of Gaussian Process Dynamical Systems in Longitudinal scenario by augmenting the bound in the variational approximation to include systematic samples of the unseen observations. We demonstrate the usefulness of this approach on synthetic as well as the human motion capture data set.