 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCueCAn: Cue Driven Contextual Attention For Identifying Missing Traffic Signs on Unconstrained Roads
Mar 05, 2023Unconstrained Asian roads often involve poor infrastructure, affecting overall road safety. Missing traffic signs are a regular part of such roads. Missing or non-existing object detection has been studied for locating missing curbs and estimating reasonable regions for pedestrians on road scene images. Such methods involve analyzing task-specific single object cues. In this paper, we present the first and most challenging video dataset for missing objects, with multiple types of traffic signs for which the cues are visible without the signs in the scenes. We refer to it as the Missing Traffic Signs Video Dataset (MTSVD). MTSVD is challenging compared to the previous works in two aspects i) The traffic signs are generally not present in the vicinity of their cues, ii) The traffic signs cues are diverse and unique. Also, MTSVD is the first publicly available missing object dataset. To train the models for identifying missing signs, we complement our dataset with 10K traffic sign tracks, with 40 percent of the traffic signs having cues visible in the scenes. For identifying missing signs, we propose the Cue-driven Contextual Attention units (CueCAn), which we incorporate in our model encoder. We first train the encoder to classify the presence of traffic sign cues and then train the entire segmentation model end-to-end to localize missing traffic signs. Quantitative and qualitative analysis shows that CueCAn significantly improves the performance of base models.
MNL-Bandit in non-stationary environments
Mar 04, 2023In this paper, we study the MNL-Bandit problem in a non-stationary environment and present an algorithm with worst-case dynamic regret of $\tilde{O}\left( \min \left\{ \sqrt{NTL}\;,\; N^{\frac{1}{3}}(\Delta_{\infty}^{K})^{\frac{1}{3}} T^{\frac{2}{3}} + \sqrt{NT}\right\}\right)$. Here $N$ is the number of arms, $L$ is the number of switches and $\Delta_{\infty}^K$ is a variation measure of the unknown parameters. We also show that our algorithm is near-optimal (up to logarithmic factors). Our algorithm builds upon the epoch-based algorithm for stationary MNL-Bandit in Agrawal et al. 2016. However, non-stationarity poses several challenges and we introduce new techniques and ideas to address these. In particular, we give a tight characterization for the bias introduced in the estimators due to non stationarity and derive new concentration bounds.
Multicalibrated Regression for Downstream Fairness
Sep 15, 2022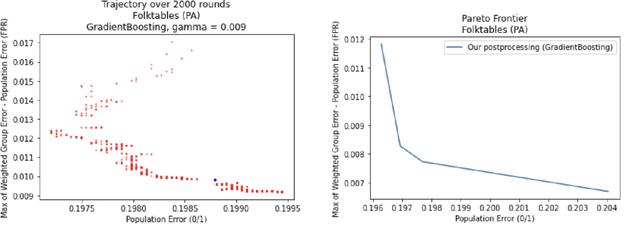
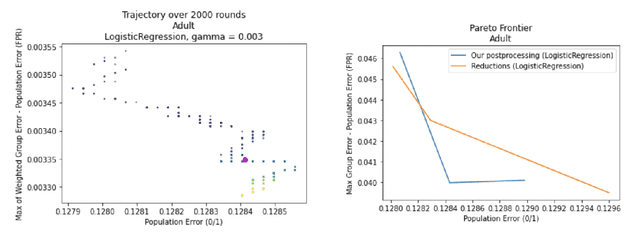
We show how to take a regression function $\hat{f}$ that is appropriately ``multicalibrated'' and efficiently post-process it into an approximately error minimizing classifier satisfying a large variety of fairness constraints. The post-processing requires no labeled data, and only a modest amount of unlabeled data and computation. The computational and sample complexity requirements of computing $\hat f$ are comparable to the requirements for solving a single fair learning task optimally, but it can in fact be used to solve many different downstream fairness-constrained learning problems efficiently. Our post-processing method easily handles intersecting groups, generalizing prior work on post-processing regression functions to satisfy fairness constraints that only applied to disjoint groups. Our work extends recent work showing that multicalibrated regression functions are ``omnipredictors'' (i.e. can be post-processed to optimally solve unconstrained ERM problems) to constrained optimization.
Practical Adversarial Multivalid Conformal Prediction
Jun 02, 2022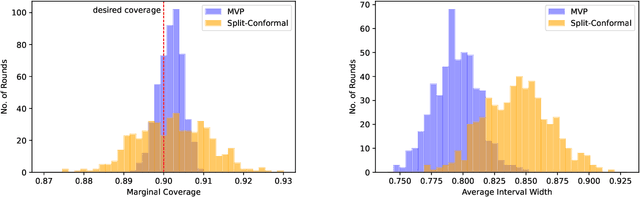
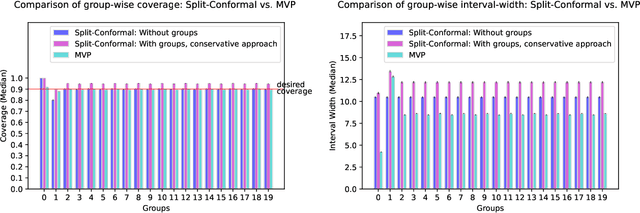
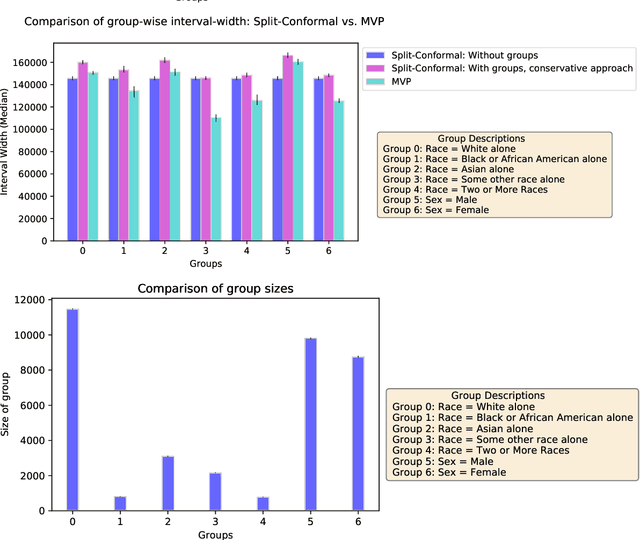
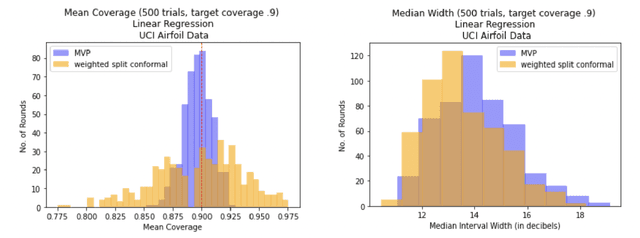
We give a simple, generic conformal prediction method for sequential prediction that achieves target empirical coverage guarantees against adversarially chosen data. It is computationally lightweight -- comparable to split conformal prediction -- but does not require having a held-out validation set, and so all data can be used for training models from which to derive a conformal score. It gives stronger than marginal coverage guarantees in two ways. First, it gives threshold calibrated prediction sets that have correct empirical coverage even conditional on the threshold used to form the prediction set from the conformal score. Second, the user can specify an arbitrary collection of subsets of the feature space -- possibly intersecting -- and the coverage guarantees also hold conditional on membership in each of these subsets. We call our algorithm MVP, short for MultiValid Prediction. We give both theory and an extensive set of empirical evaluations.
Dynamic Regret Minimization for Control of Non-stationary Linear Dynamical Systems
Nov 06, 2021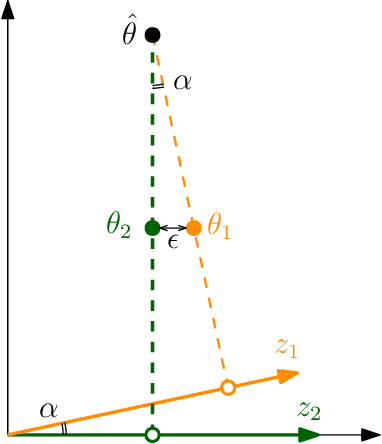
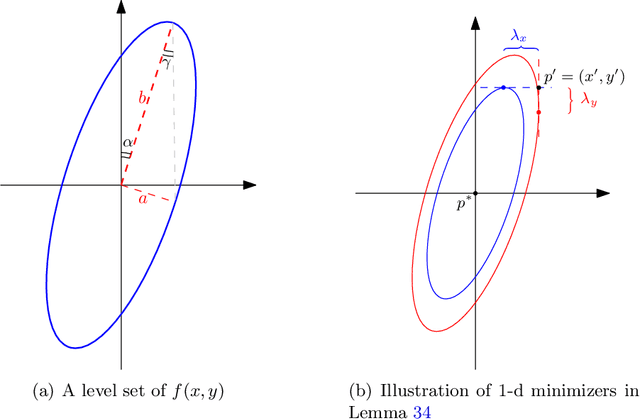
We consider the problem of controlling a Linear Quadratic Regulator (LQR) system over a finite horizon $T$ with fixed and known cost matrices $Q,R$, but unknown and non-stationary dynamics $\{A_t, B_t\}$. The sequence of dynamics matrices can be arbitrary, but with a total variation, $V_T$, assumed to be $o(T)$ and unknown to the controller. Under the assumption that a sequence of stabilizing, but potentially sub-optimal controllers is available for all $t$, we present an algorithm that achieves the optimal dynamic regret of $\tilde{\mathcal{O}}\left(V_T^{2/5}T^{3/5}\right)$. With piece-wise constant dynamics, our algorithm achieves the optimal regret of $\tilde{\mathcal{O}}(\sqrt{ST})$ where $S$ is the number of switches. The crux of our algorithm is an adaptive non-stationarity detection strategy, which builds on an approach recently developed for contextual Multi-armed Bandit problems. We also argue that non-adaptive forgetting (e.g., restarting or using sliding window learning with a static window size) may not be regret optimal for the LQR problem, even when the window size is optimally tuned with the knowledge of $V_T$. The main technical challenge in the analysis of our algorithm is to prove that the ordinary least squares (OLS) estimator has a small bias when the parameter to be estimated is non-stationary. Our analysis also highlights that the key motif driving the regret is that the LQR problem is in spirit a bandit problem with linear feedback and locally quadratic cost. This motif is more universal than the LQR problem itself, and therefore we believe our results should find wider application.
Adaptive Machine Unlearning
Jun 08, 2021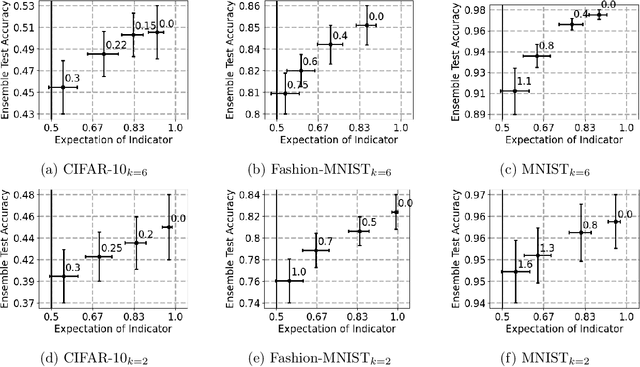
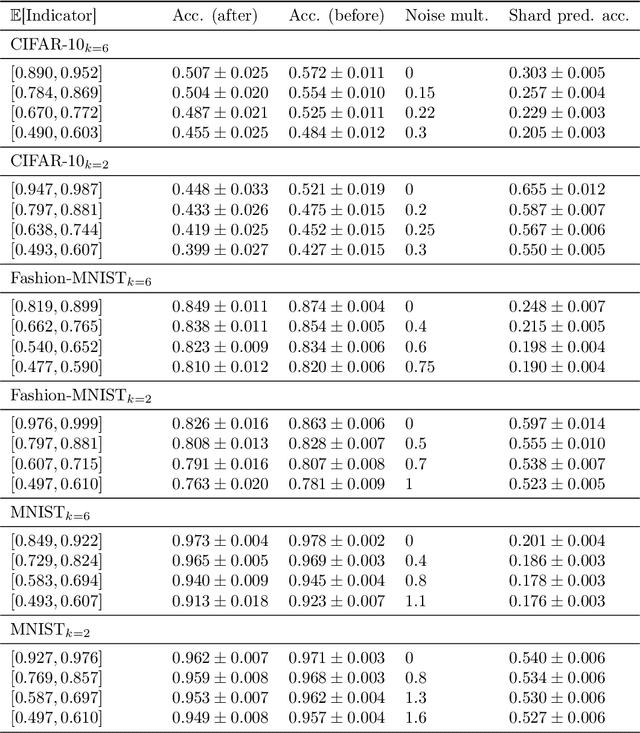
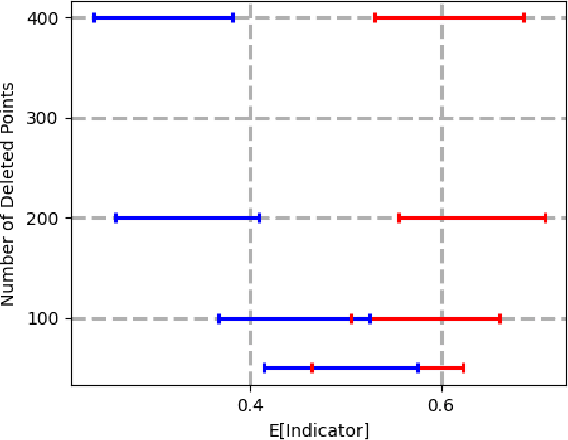
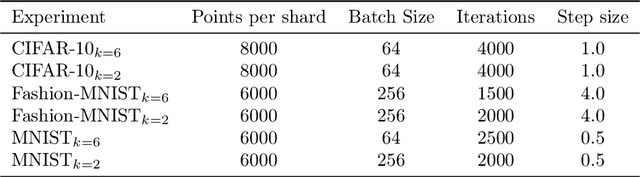
Data deletion algorithms aim to remove the influence of deleted data points from trained models at a cheaper computational cost than fully retraining those models. However, for sequences of deletions, most prior work in the non-convex setting gives valid guarantees only for sequences that are chosen independently of the models that are published. If people choose to delete their data as a function of the published models (because they don't like what the models reveal about them, for example), then the update sequence is adaptive. In this paper, we give a general reduction from deletion guarantees against adaptive sequences to deletion guarantees against non-adaptive sequences, using differential privacy and its connection to max information. Combined with ideas from prior work which give guarantees for non-adaptive deletion sequences, this leads to extremely flexible algorithms able to handle arbitrary model classes and training methodologies, giving strong provable deletion guarantees for adaptive deletion sequences. We show in theory how prior work for non-convex models fails against adaptive deletion sequences, and use this intuition to design a practical attack against the SISA algorithm of Bourtoule et al. [2021] on CIFAR-10, MNIST, Fashion-MNIST.
Online Multivalid Learning: Means, Moments, and Prediction Intervals
Jan 05, 2021
We present a general, efficient technique for providing contextual predictions that are "multivalid" in various senses, against an online sequence of adversarially chosen examples $(x,y)$. This means that the resulting estimates correctly predict various statistics of the labels $y$ not just marginally -- as averaged over the sequence of examples -- but also conditionally on $x \in G$ for any $G$ belonging to an arbitrary intersecting collection of groups $\mathcal{G}$. We provide three instantiations of this framework. The first is mean prediction, which corresponds to an online algorithm satisfying the notion of multicalibration from Hebert-Johnson et al. The second is variance and higher moment prediction, which corresponds to an online algorithm satisfying the notion of mean-conditioned moment multicalibration from Jung et al. Finally, we define a new notion of prediction interval multivalidity, and give an algorithm for finding prediction intervals which satisfy it. Because our algorithms handle adversarially chosen examples, they can equally well be used to predict statistics of the residuals of arbitrary point prediction methods, giving rise to very general techniques for quantifying the uncertainty of predictions of black box algorithms, even in an online adversarial setting. When instantiated for prediction intervals, this solves a similar problem as conformal prediction, but in an adversarial environment and with multivalidity guarantees stronger than simple marginal coverage guarantees.
Automated Personalized Feedback Improves Learning Gains in an Intelligent Tutoring System
May 07, 2020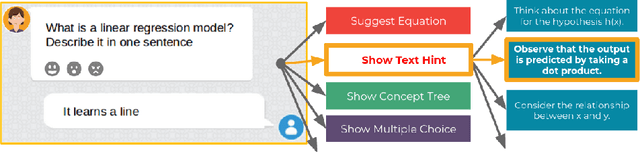

We investigate how automated, data-driven, personalized feedback in a large-scale intelligent tutoring system (ITS) improves student learning outcomes. We propose a machine learning approach to generate personalized feedback, which takes individual needs of students into account. We utilize state-of-the-art machine learning and natural language processing techniques to provide the students with personalized hints, Wikipedia-based explanations, and mathematical hints. Our model is used in Korbit, a large-scale dialogue-based ITS with thousands of students launched in 2019, and we demonstrate that the personalized feedback leads to considerable improvement in student learning outcomes and in the subjective evaluation of the feedback.
A Large-Scale, Open-Domain, Mixed-Interface Dialogue-Based ITS for STEM
May 06, 2020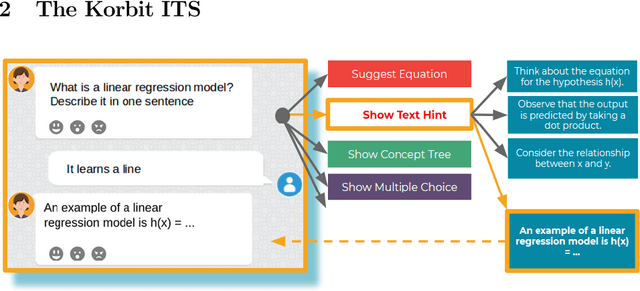
We present Korbit, a large-scale, open-domain, mixed-interface, dialogue-based intelligent tutoring system (ITS). Korbit uses machine learning, natural language processing and reinforcement learning to provide interactive, personalized learning online. Korbit has been designed to easily scale to thousands of subjects, by automating, standardizing and simplifying the content creation process. Unlike other ITS, a teacher can develop new learning modules for Korbit in a matter of hours. To facilitate learning across a widerange of STEM subjects, Korbit uses a mixed-interface, which includes videos, interactive dialogue-based exercises, question-answering, conceptual diagrams, mathematical exercises and gamification elements. Korbit has been built to scale to millions of students, by utilizing a state-of-the-art cloud-based micro-service architecture. Korbit launched its first course in 2019 on machine learning, and since then over 7,000 students have enrolled. Although Korbit was designed to be open-domain and highly scalable, A/B testing experiments with real-world students demonstrate that both student learning outcomes and student motivation are substantially improved compared to typical online courses.
Learning Influence-Receptivity Network Structure with Guarantee
Jun 14, 2018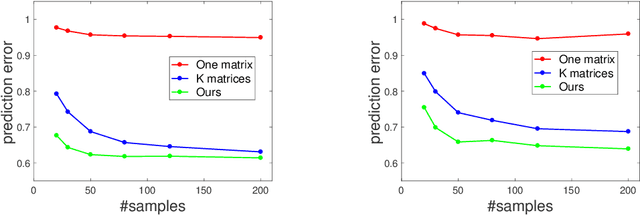
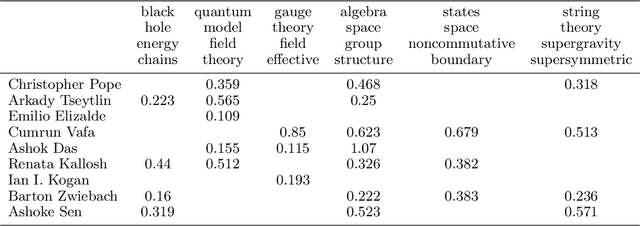


Traditional works on community detection from observations of information cascade assume that a single adjacency matrix parametrizes all the observed cascades. However, in reality the connection structure usually does not stay the same across cascades. For example, different people have different topics of interest, therefore the connection structure would depend on the information/topic content of the cascade. In this paper we consider the case where we observe a sequence of noisy adjacency matrices triggered by information/events with different topic distributions. We propose a novel latent model using the intuition that the connection is more likely to exist between two nodes if they are interested in similar topics, which are common with the information/event. Specifically, we endow each node two node-topic vectors: an influence vector that measures how much influential/authoritative they are on each topic; and a receptivity vector that measures how much receptive/susceptible they are to each topic. We show how these two node-topic structures can be estimated from observed adjacency matrices with theoretical guarantee, in cases where the topic distributions of the information/events are known, as well as when they are unknown. Extensive experiments on synthetic and real data demonstrate the effectiveness of our model.