 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Bayesian Optimization
Jun 09, 2020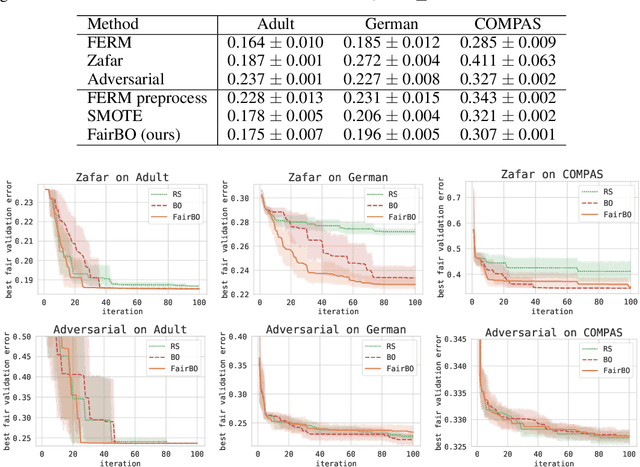
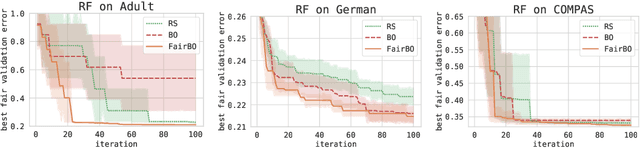

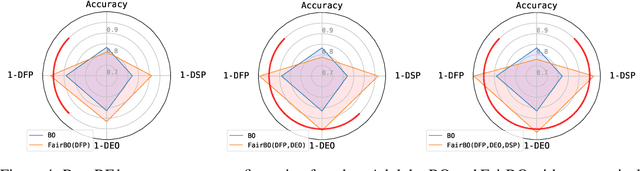
Given the increasing importance of machine learning (ML) in our lives, algorithmic fairness techniques have been proposed to mitigate biases that can be amplified by ML. Commonly, these specialized techniques apply to a single family of ML models and a specific definition of fairness, limiting their effectiveness in practice. We introduce a general constrained Bayesian optimization (BO) framework to optimize the performance of any ML model while enforcing one or multiple fairness constraints. BO is a global optimization method that has been successfully applied to automatically tune the hyperparameters of ML models. We apply BO with fairness constraints to a range of popular models, including random forests, gradient boosting, and neural networks, showing that we can obtain accurate and fair solutions by acting solely on the hyperparameters. We also show empirically that our approach is competitive with specialized techniques that explicitly enforce fairness constraints during training, and outperforms preprocessing methods that learn unbiased representations of the input data. Moreover, our method can be used in synergy with such specialized fairness techniques to tune their hyperparameters. Finally, we study the relationship between hyperparameters and fairness of the generated model. We observe a correlation between regularization and unbiased models, explaining why acting on the hyperparameters leads to ML models that generalize well and are fair.
Cost-aware Bayesian Optimization
Mar 22, 2020
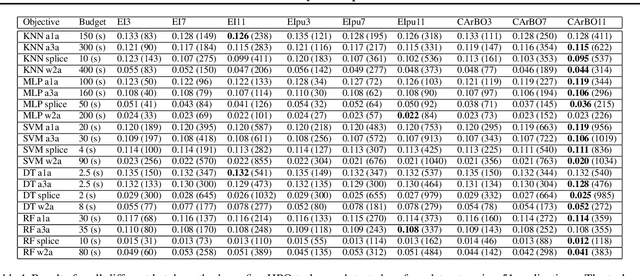
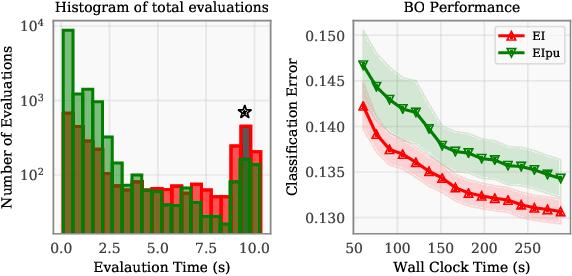
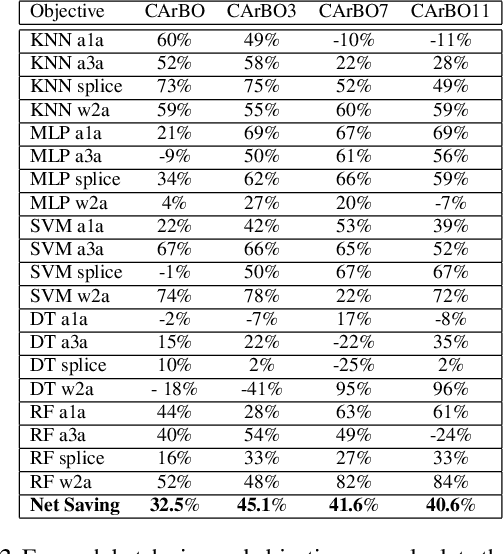
Bayesian optimization (BO) is a class of global optimization algorithms, suitable for minimizing an expensive objective function in as few function evaluations as possible. While BO budgets are typically given in iterations, this implicitly measures convergence in terms of iteration count and assumes each evaluation has identical cost. In practice, evaluation costs may vary in different regions of the search space. For example, the cost of neural network training increases quadratically with layer size, which is a typical hyperparameter. Cost-aware BO measures convergence with alternative cost metrics such as time, energy, or money, for which vanilla BO methods are unsuited. We introduce Cost Apportioned BO (CArBO), which attempts to minimize an objective function in as little cost as possible. CArBO combines a cost-effective initial design with a cost-cooled optimization phase which depreciates a learned cost model as iterations proceed. On a set of 20 black-box function optimization problems we show that, given the same cost budget, CArBO finds significantly better hyperparameter configurations than competing methods.
Constrained Bayesian Optimization with Max-Value Entropy Search
Oct 15, 2019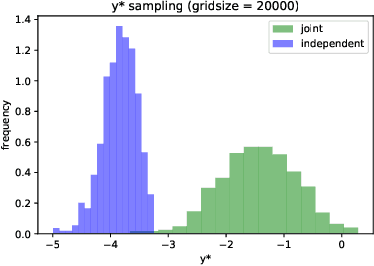
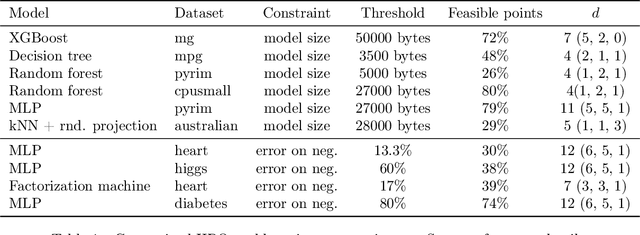
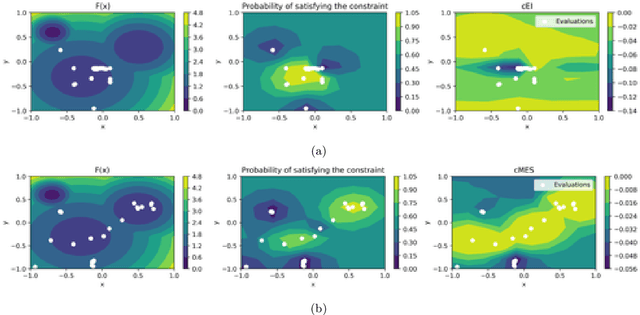
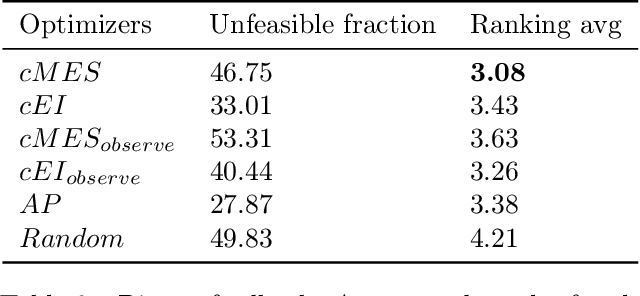
Bayesian optimization (BO) is a model-based approach to sequentially optimize expensive black-box functions, such as the validation error of a deep neural network with respect to its hyperparameters. In many real-world scenarios, the optimization is further subject to a priori unknown constraints. For example, training a deep network configuration may fail with an out-of-memory error when the model is too large. In this work, we focus on a general formulation of Gaussian process-based BO with continuous or binary constraints. We propose constrained Max-value Entropy Search (cMES), a novel information theoretic-based acquisition function implementing this formulation. We also revisit the validity of the factorized approximation adopted for rapid computation of the MES acquisition function, showing empirically that this leads to inaccurate results. On an extensive set of real-world constrained hyperparameter optimization problems we show that cMES compares favourably to prior work, while being simpler to implement and faster than other constrained extensions of Entropy Search.
A Copula approach for hyperparameter transfer learning
Sep 30, 2019
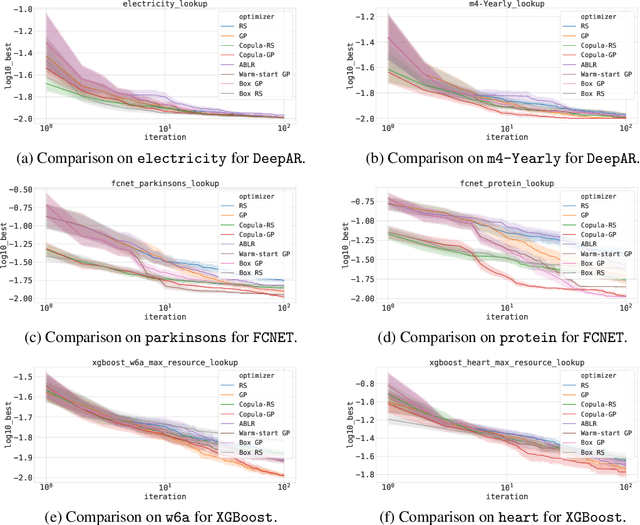
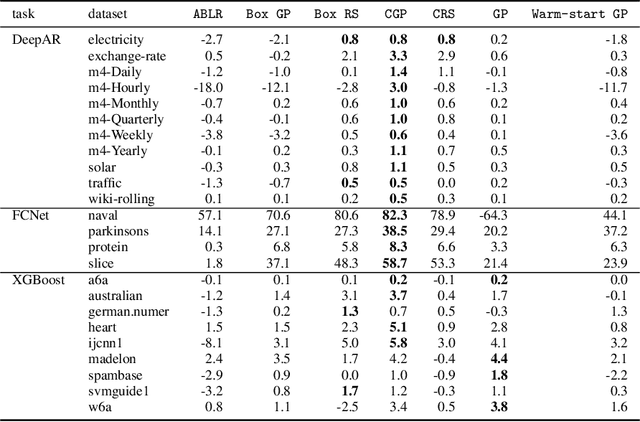
Bayesian optimization (BO) is a popular methodology to tune the hyperparameters of expensive black-box functions. Despite its success, standard BO focuses on a single task at a time and is not designed to leverage information from related functions, such as tuning performance metrics of the same algorithm across multiple datasets. In this work, we introduce a novel approach to achieve transfer learning across different datasets as well as different metrics. The main idea is to regress the mapping from hyperparameter to metric quantiles with a semi-parametric Gaussian Copula distribution, which provides robustness against different scales or outliers that can occur in different tasks. We introduce two methods to leverage this estimation: a Thompson sampling strategy as well as a Gaussian Copula process using such quantile estimate as a prior. We show that these strategies can combine the estimation of multiple metrics such as runtime and accuracy, steering the optimization toward cheaper hyperparameters for the same level of accuracy. Experiments on an extensive set of hyperparameter tuning tasks demonstrate significant improvements over state-of-the-art methods.
Learning search spaces for Bayesian optimization: Another view of hyperparameter transfer learning
Sep 27, 2019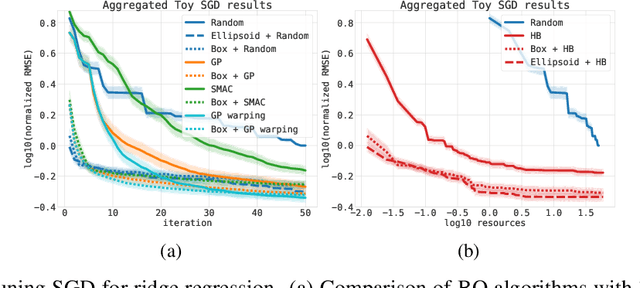
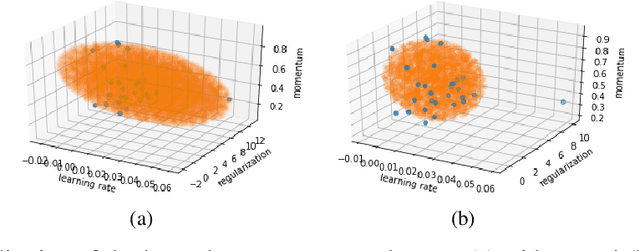
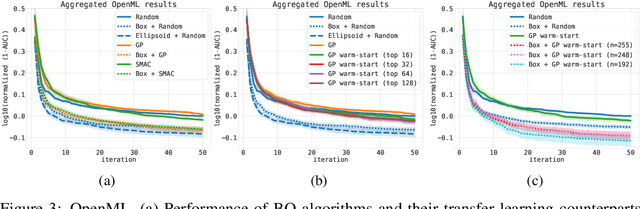
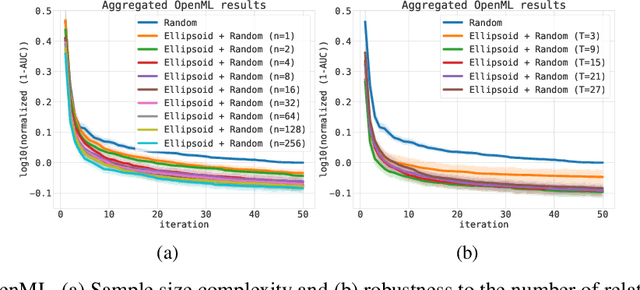
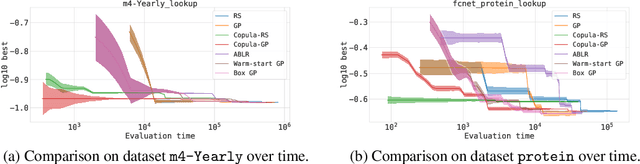
Bayesian optimization (BO) is a successful methodology to optimize black-box functions that are expensive to evaluate. While traditional methods optimize each black-box function in isolation, there has been recent interest in speeding up BO by transferring knowledge across multiple related black-box functions. In this work, we introduce a method to automatically design the BO search space by relying on evaluations of previous black-box functions. We depart from the common practice of defining a set of arbitrary search ranges a priori by considering search space geometries that are learned from historical data. This simple, yet effective strategy can be used to endow many existing BO methods with transfer learning properties. Despite its simplicity, we show that our approach considerably boosts BO by reducing the size of the search space, thus accelerating the optimization of a variety of black-box optimization problems. In particular, the proposed approach combined with random search results in a parameter-free, easy-to-implement, robust hyperparameter optimization strategy. We hope it will constitute a natural baseline for further research attempting to warm-start BO.
GASC: Genre-Aware Semantic Change for Ancient Greek
Mar 13, 2019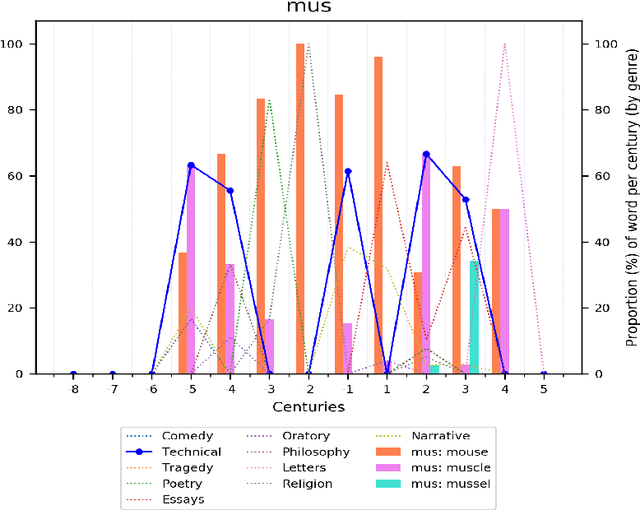

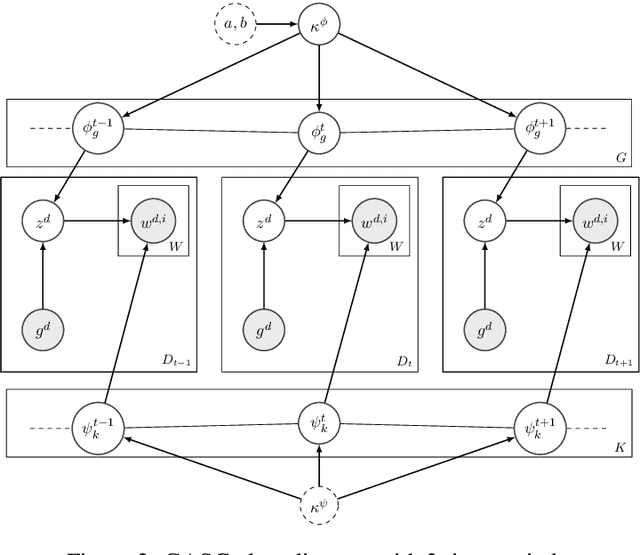
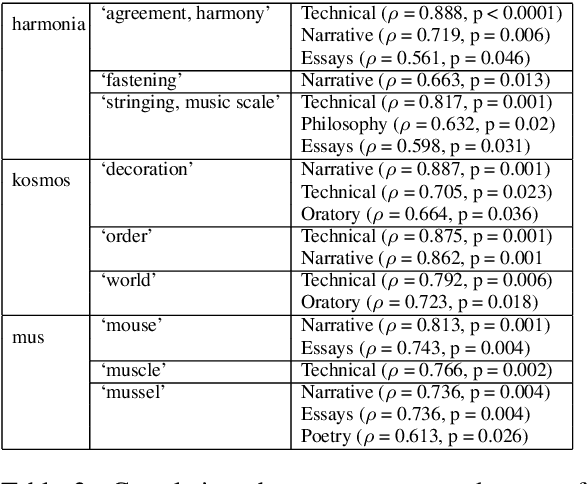
Word meaning changes over time, depending on linguistic and extra-linguistic factors. Associating a word's correct meaning in its historical context is a critical challenge in diachronic research, and is relevant to a range of NLP tasks, including information retrieval and semantic search in historical texts. Bayesian models for semantic change have emerged as a powerful tool to address this challenge, providing explicit and interpretable representations of semantic change phenomena. However, while corpora typically come with rich metadata, existing models are limited by their inability to exploit contextual information (such as text genre) beyond the document time-stamp. This is particularly critical in the case of ancient languages, where lack of data and long diachronic span make it harder to draw a clear distinction between polysemy and semantic change, and current systems perform poorly on these languages. We develop GASC, a dynamic semantic change model that leverages categorical metadata about the texts' genre information to boost inference and uncover the evolution of meanings in Ancient Greek corpora. In a new evaluation framework, we show that our model achieves improved predictive performance compared to the state of the art.
A Likelihood-Free Inference Framework for Population Genetic Data using Exchangeable Neural Networks
Nov 06, 2018
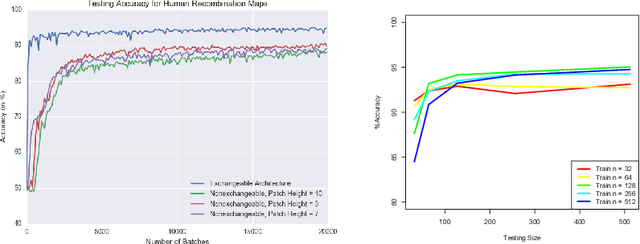
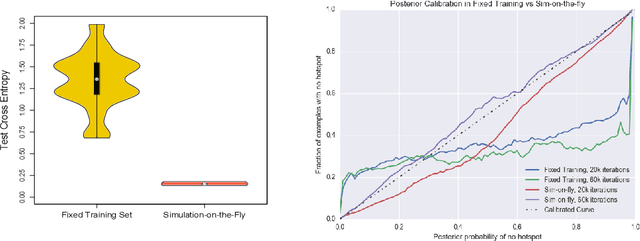
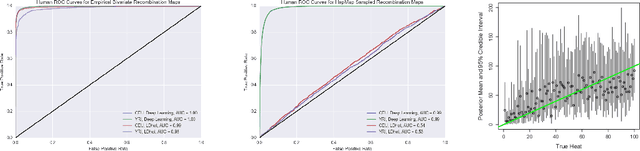
An explosion of high-throughput DNA sequencing in the past decade has led to a surge of interest in population-scale inference with whole-genome data. Recent work in population genetics has centered on designing inference methods for relatively simple model classes, and few scalable general-purpose inference techniques exist for more realistic, complex models. To achieve this, two inferential challenges need to be addressed: (1) population data are exchangeable, calling for methods that efficiently exploit the symmetries of the data, and (2) computing likelihoods is intractable as it requires integrating over a set of correlated, extremely high-dimensional latent variables. These challenges are traditionally tackled by likelihood-free methods that use scientific simulators to generate datasets and reduce them to hand-designed, permutation-invariant summary statistics, often leading to inaccurate inference. In this work, we develop an exchangeable neural network that performs summary statistic-free, likelihood-free inference. Our framework can be applied in a black-box fashion across a variety of simulation-based tasks, both within and outside biology. We demonstrate the power of our approach on the recombination hotspot testing problem, outperforming the state-of-the-art.
Multiple Adaptive Bayesian Linear Regression for Scalable Bayesian Optimization with Warm Start
Dec 08, 2017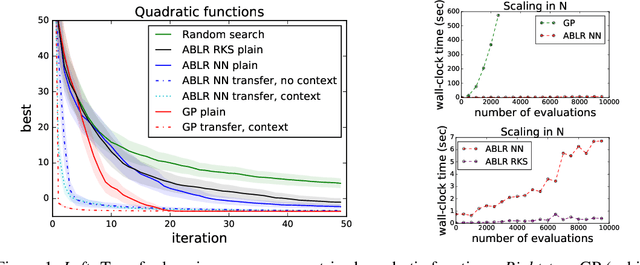
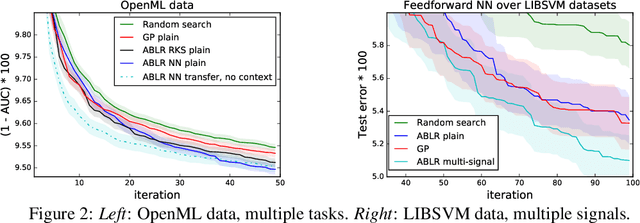
Bayesian optimization (BO) is a model-based approach for gradient-free black-box function optimization. Typically, BO is powered by a Gaussian process (GP), whose algorithmic complexity is cubic in the number of evaluations. Hence, GP-based BO cannot leverage large amounts of past or related function evaluations, for example, to warm start the BO procedure. We develop a multiple adaptive Bayesian linear regression model as a scalable alternative whose complexity is linear in the number of observations. The multiple Bayesian linear regression models are coupled through a shared feedforward neural network, which learns a joint representation and transfers knowledge across machine learning problems.
Poisson Random Fields for Dynamic Feature Models
Nov 22, 2016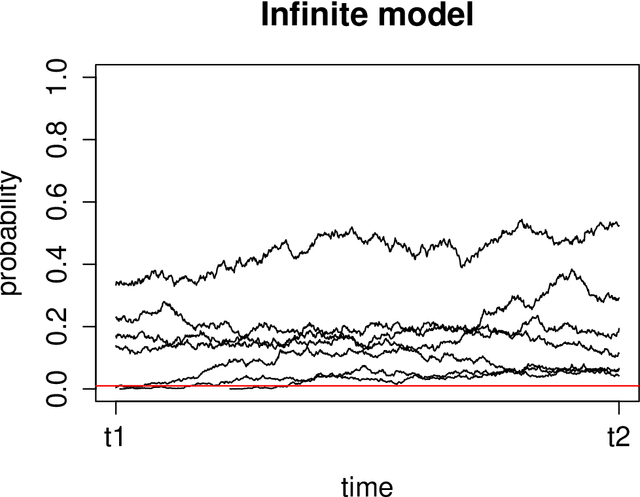

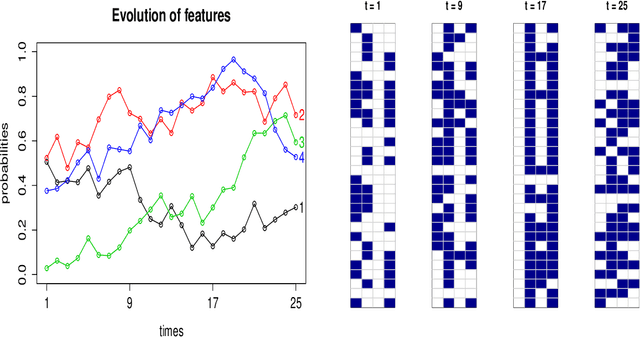
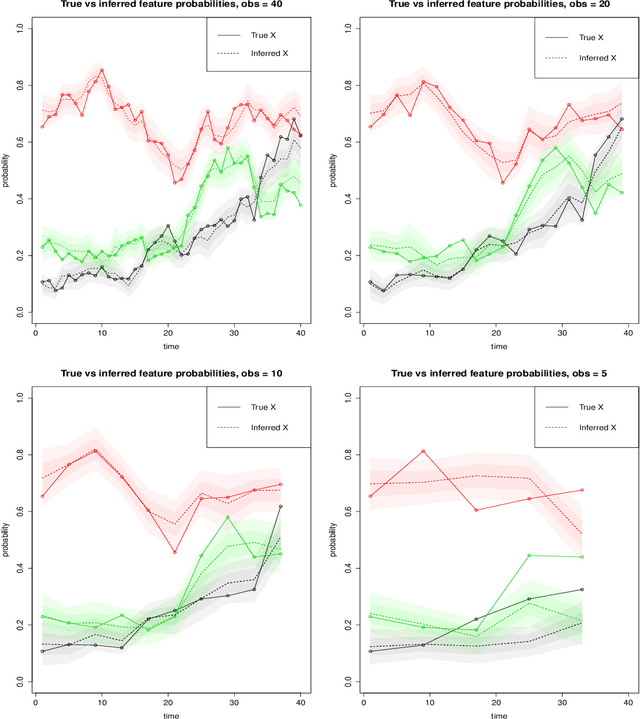
We present the Wright-Fisher Indian buffet process (WF-IBP), a probabilistic model for time-dependent data assumed to have been generated by an unknown number of latent features. This model is suitable as a prior in Bayesian nonparametric feature allocation models in which the features underlying the observed data exhibit a dependency structure over time. More specifically, we establish a new framework for generating dependent Indian buffet processes, where the Poisson random field model from population genetics is used as a way of constructing dependent beta processes. Inference in the model is complex, and we describe a sophisticated Markov Chain Monte Carlo algorithm for exact posterior simulation. We apply our construction to develop a nonparametric focused topic model for collections of time-stamped text documents and test it on the full corpus of NIPS papers published from 1987 to 2015.
Relativistic Monte Carlo
Sep 14, 2016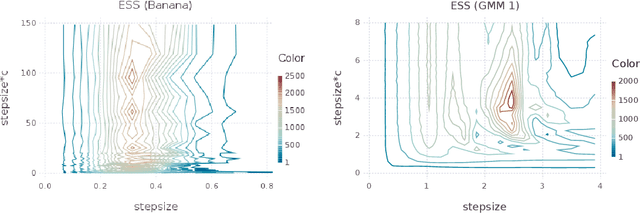
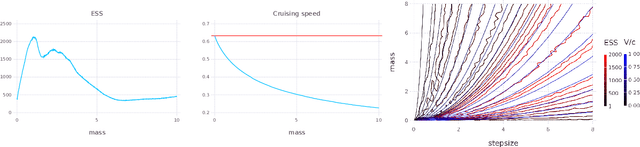
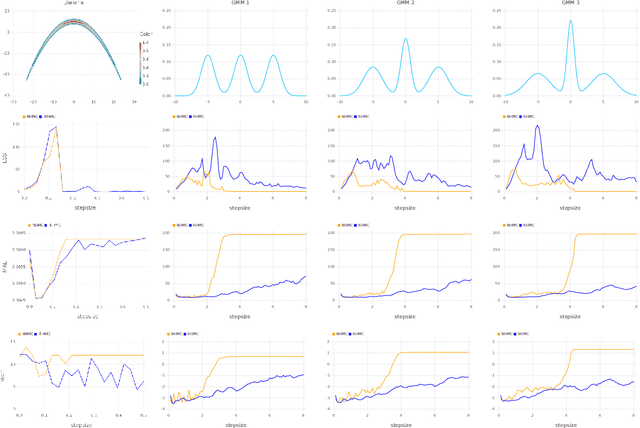
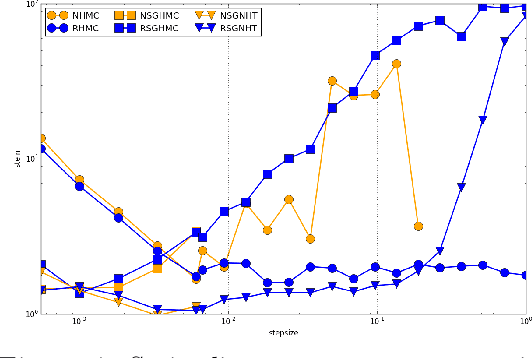
Hamiltonian Monte Carlo (HMC) is a popular Markov chain Monte Carlo (MCMC) algorithm that generates proposals for a Metropolis-Hastings algorithm by simulating the dynamics of a Hamiltonian system. However, HMC is sensitive to large time discretizations and performs poorly if there is a mismatch between the spatial geometry of the target distribution and the scales of the momentum distribution. In particular the mass matrix of HMC is hard to tune well. In order to alleviate these problems we propose relativistic Hamiltonian Monte Carlo, a version of HMC based on relativistic dynamics that introduce a maximum velocity on particles. We also derive stochastic gradient versions of the algorithm and show that the resulting algorithms bear interesting relationships to gradient clipping, RMSprop, Adagrad and Adam, popular optimisation methods in deep learning. Based on this, we develop relativistic stochastic gradient descent by taking the zero-temperature limit of relativistic stochastic gradient Hamiltonian Monte Carlo. In experiments we show that the relativistic algorithms perform better than classical Newtonian variants and Adam.