 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward A Logical Theory Of Fairness and Bias
Jun 08, 2023Fairness in machine learning is of considerable interest in recent years owing to the propensity of algorithms trained on historical data to amplify and perpetuate historical biases. In this paper, we argue for a formal reconstruction of fairness definitions, not so much to replace existing definitions but to ground their application in an epistemic setting and allow for rich environmental modelling. Consequently we look into three notions: fairness through unawareness, demographic parity and counterfactual fairness, and formalise these in the epistemic situation calculus.
Statistical relational learning and neuro-symbolic AI: what does first-order logic offer?
Jun 08, 2023In this paper, our aim is to briefly survey and articulate the logical and philosophical foundations of using (first-order) logic to represent (probabilistic) knowledge in a non-technical fashion. Our motivation is three fold. First, for machine learning researchers unaware of why the research community cares about relational representations, this article can serve as a gentle introduction. Second, for logical experts who are newcomers to the learning area, such an article can help in navigating the differences between finite vs infinite, and subjective probabilities vs random-world semantics. Finally, for researchers from statistical relational learning and neuro-symbolic AI, who are usually embedded in finite worlds with subjective probabilities, appreciating what infinite domains and random-world semantics brings to the table is of utmost theoretical import.
Synthesising Recursive Functions for First-Order Model Counting: Challenges, Progress, and Conjectures
Jun 07, 2023First-order model counting (FOMC) is a computational problem that asks to count the models of a sentence in finite-domain first-order logic. In this paper, we argue that the capabilities of FOMC algorithms to date are limited by their inability to express many types of recursive computations. To enable such computations, we relax the restrictions that typically accompany domain recursion and generalise the circuits used to express a solution to an FOMC problem to directed graphs that may contain cycles. To this end, we adapt the most well-established (weighted) FOMC algorithm ForcLift to work with such graphs and introduce new compilation rules that can create cycle-inducing edges that encode recursive function calls. These improvements allow the algorithm to find efficient solutions to counting problems that were previously beyond its reach, including those that cannot be solved efficiently by any other exact FOMC algorithm. We end with a few conjectures on what classes of instances could be domain-liftable as a result.
Why not both? Complementing explanations with uncertainty, and the role of self-confidence in Human-AI collaboration
Apr 27, 2023AI and ML models have already found many applications in critical domains, such as healthcare and criminal justice. However, fully automating such high-stakes applications can raise ethical or fairness concerns. Instead, in such cases, humans should be assisted by automated systems so that the two parties reach a joint decision, stemming out of their interaction. In this work we conduct an empirical study to identify how uncertainty estimates and model explanations affect users' reliance, understanding, and trust towards a model, looking for potential benefits of bringing the two together. Moreover, we seek to assess how users' behaviour is affected by their own self-confidence in their abilities to perform a certain task, while we also discuss how the latter may distort the outcome of an analysis based on agreement and switching percentages.
Using Abstraction for Interpretable Robot Programs in Stochastic Domains
Jul 26, 2022A robot's actions are inherently stochastic, as its sensors are noisy and its actions do not always have the intended effects. For this reason, the agent language Golog has been extended to models with degrees of belief and stochastic actions. While this allows more precise robot models, the resulting programs are much harder to comprehend, because they need to deal with the noise, e.g., by looping until some desired state has been reached with certainty, and because the resulting action traces consist of a large number of actions cluttered with sensor noise. To alleviate these issues, we propose to use abstraction. We define a high-level and nonstochastic model of the robot and then map the high-level model into the lower-level stochastic model. The resulting programs are much easier to understand, often do not require belief operators or loops, and produce much shorter action traces.
Abstracting Noisy Robot Programs
Apr 07, 2022
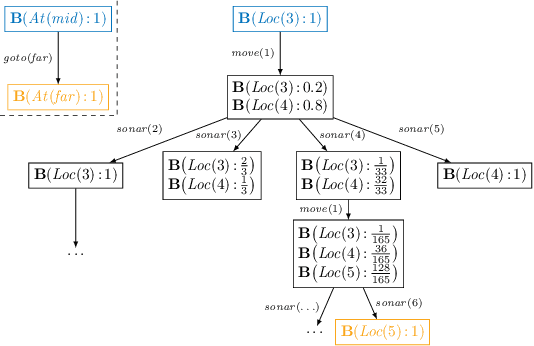
Abstraction is a commonly used process to represent some low-level system by a more coarse specification with the goal to omit unnecessary details while preserving important aspects. While recent work on abstraction in the situation calculus has focused on non-probabilistic domains, we describe an approach to abstraction of probabilistic and dynamic systems. Based on a variant of the situation calculus with probabilistic belief, we define a notion of bisimulation that allows to abstract a detailed probabilistic basic action theory with noisy actuators and sensors by a possibly deterministic basic action theory. By doing so, we obtain abstract Golog programs that omit unnecessary details and which can be translated back to a detailed program for actual execution. This simplifies the implementation of noisy robot programs, opens up the possibility of using deterministic reasoning methods (e.g., planning) on probabilistic problems, and provides domain descriptions that are more easily understandable and explainable.
Explainability in Machine Learning: a Pedagogical Perspective
Feb 21, 2022Given the importance of integrating of explainability into machine learning, at present, there are a lack of pedagogical resources exploring this. Specifically, we have found a need for resources in explaining how one can teach the advantages of explainability in machine learning. Often pedagogical approaches in the field of machine learning focus on getting students prepared to apply various models in the real world setting, but much less attention is given to teaching students the various techniques one could employ to explain a model's decision-making process. Furthermore, explainability can benefit from a narrative structure that aids one in understanding which techniques are governed by which questions about the data. We provide a pedagogical perspective on how to structure the learning process to better impart knowledge to students and researchers in machine learning, when and how to implement various explainability techniques as well as how to interpret the results. We discuss a system of teaching explainability in machine learning, by exploring the advantages and disadvantages of various opaque and transparent machine learning models, as well as when to utilize specific explainability techniques and the various frameworks used to structure the tools for explainability. Among discussing concrete assignments, we will also discuss ways to structure potential assignments to best help students learn to use explainability as a tool alongside any given machine learning application. Data science professionals completing the course will have a birds-eye view of a rapidly developing area and will be confident to deploy machine learning more widely. A preliminary analysis on the effectiveness of a recently delivered course following the structure presented here is included as evidence supporting our pedagogical approach.
Vision Checklist: Towards Testable Error Analysis of Image Models to Help System Designers Interrogate Model Capabilities
Jan 31, 2022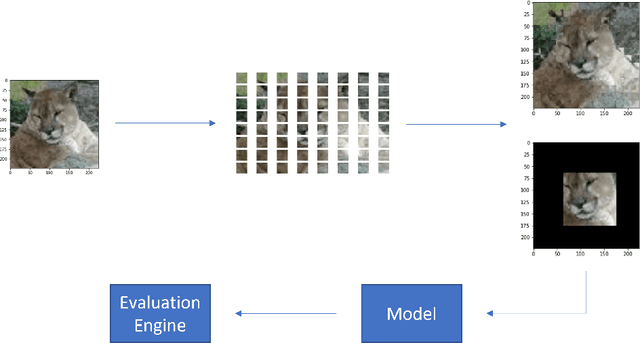



Using large pre-trained models for image recognition tasks is becoming increasingly common owing to the well acknowledged success of recent models like vision transformers and other CNN-based models like VGG and Resnet. The high accuracy of these models on benchmark tasks has translated into their practical use across many domains including safety-critical applications like autonomous driving and medical diagnostics. Despite their widespread use, image models have been shown to be fragile to changes in the operating environment, bringing their robustness into question. There is an urgent need for methods that systematically characterise and quantify the capabilities of these models to help designers understand and provide guarantees about their safety and robustness. In this paper, we propose Vision Checklist, a framework aimed at interrogating the capabilities of a model in order to produce a report that can be used by a system designer for robustness evaluations. This framework proposes a set of perturbation operations that can be applied on the underlying data to generate test samples of different types. The perturbations reflect potential changes in operating environments, and interrogate various properties ranging from the strictly quantitative to more qualitative. Our framework is evaluated on multiple datasets like Tinyimagenet, CIFAR10, CIFAR100 and Camelyon17 and for models like ViT and Resnet. Our Vision Checklist proposes a specific set of evaluations that can be integrated into the previously proposed concept of a model card. Robustness evaluations like our checklist will be crucial in future safety evaluations of visual perception modules, and be useful for a wide range of stakeholders including designers, deployers, and regulators involved in the certification of these systems. Source code of Vision Checklist would be open for public use.
Principled Diverse Counterfactuals in Multilinear Models
Jan 17, 2022


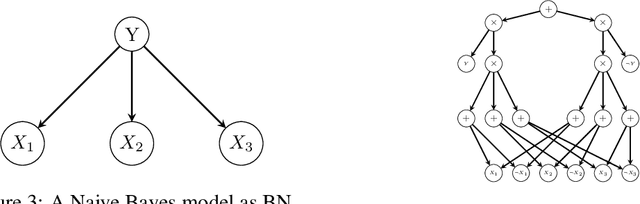
Machine learning (ML) applications have automated numerous real-life tasks, improving both private and public life. However, the black-box nature of many state-of-the-art models poses the challenge of model verification; how can one be sure that the algorithm bases its decisions on the proper criteria, or that it does not discriminate against certain minority groups? In this paper we propose a way to generate diverse counterfactual explanations from multilinear models, a broad class which includes Random Forests, as well as Bayesian Networks.
MultiplexNet: Towards Fully Satisfied Logical Constraints in Neural Networks
Nov 02, 2021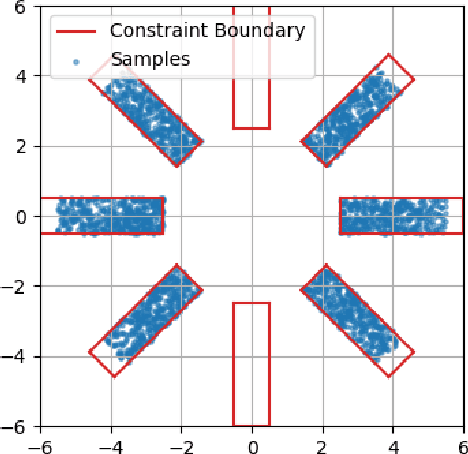
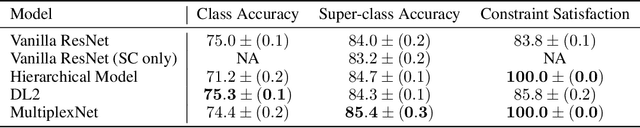
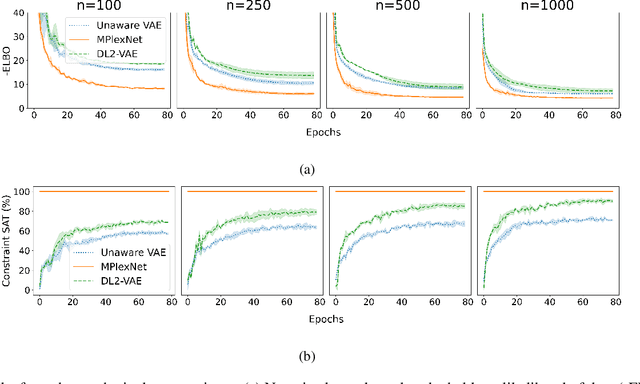

We propose a novel way to incorporate expert knowledge into the training of deep neural networks. Many approaches encode domain constraints directly into the network architecture, requiring non-trivial or domain-specific engineering. In contrast, our approach, called MultiplexNet, represents domain knowledge as a logical formula in disjunctive normal form (DNF) which is easy to encode and to elicit from human experts. It introduces a Categorical latent variable that learns to choose which constraint term optimizes the error function of the network and it compiles the constraints directly into the output of existing learning algorithms. We demonstrate the efficacy of this approach empirically on several classical deep learning tasks, such as density estimation and classification in both supervised and unsupervised settings where prior knowledge about the domains was expressed as logical constraints. Our results show that the MultiplexNet approach learned to approximate unknown distributions well, often requiring fewer data samples than the alternative approaches. In some cases, MultiplexNet finds better solutions than the baselines; or solutions that could not be achieved with the alternative approaches. Our contribution is in encoding domain knowledge in a way that facilitates inference that is shown to be both efficient and general; and critically, our approach guarantees 100% constraint satisfaction in a network's output.