 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHighlightMe: Detecting Highlights from Human-Centric Videos
Oct 05, 2021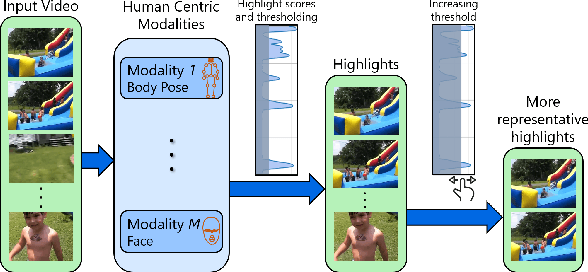
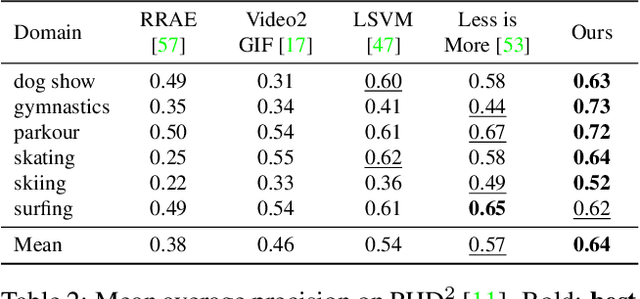
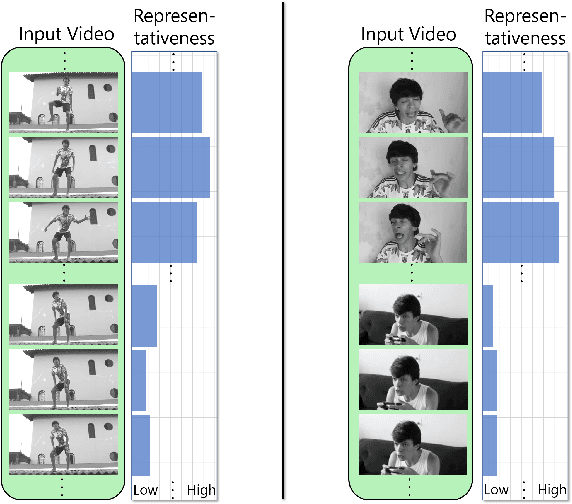

We present a domain- and user-preference-agnostic approach to detect highlightable excerpts from human-centric videos. Our method works on the graph-based representation of multiple observable human-centric modalities in the videos, such as poses and faces. We use an autoencoder network equipped with spatial-temporal graph convolutions to detect human activities and interactions based on these modalities. We train our network to map the activity- and interaction-based latent structural representations of the different modalities to per-frame highlight scores based on the representativeness of the frames. We use these scores to compute which frames to highlight and stitch contiguous frames to produce the excerpts. We train our network on the large-scale AVA-Kinetics action dataset and evaluate it on four benchmark video highlight datasets: DSH, TVSum, PHD2, and SumMe. We observe a 4-12% improvement in the mean average precision of matching the human-annotated highlights over state-of-the-art methods in these datasets, without requiring any user-provided preferences or dataset-specific fine-tuning.
Speech2AffectiveGestures: Synthesizing Co-Speech Gestures with Generative Adversarial Affective Expression Learning
Aug 03, 2021
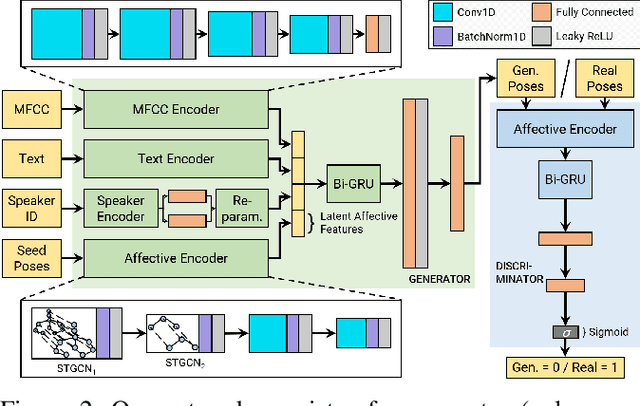
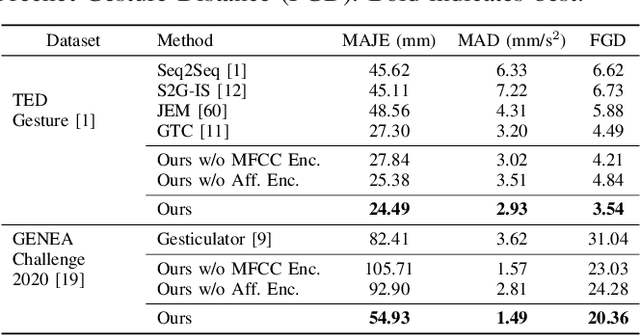

We present a generative adversarial network to synthesize 3D pose sequences of co-speech upper-body gestures with appropriate affective expressions. Our network consists of two components: a generator to synthesize gestures from a joint embedding space of features encoded from the input speech and the seed poses, and a discriminator to distinguish between the synthesized pose sequences and real 3D pose sequences. We leverage the Mel-frequency cepstral coefficients and the text transcript computed from the input speech in separate encoders in our generator to learn the desired sentiments and the associated affective cues. We design an affective encoder using multi-scale spatial-temporal graph convolutions to transform 3D pose sequences into latent, pose-based affective features. We use our affective encoder in both our generator, where it learns affective features from the seed poses to guide the gesture synthesis, and our discriminator, where it enforces the synthesized gestures to contain the appropriate affective expressions. We perform extensive evaluations on two benchmark datasets for gesture synthesis from the speech, the TED Gesture Dataset and the GENEA Challenge 2020 Dataset. Compared to the best baselines, we improve the mean absolute joint error by 10--33%, the mean acceleration difference by 8--58%, and the Fr\'echet Gesture Distance by 21--34%. We also conduct a user study and observe that compared to the best current baselines, around 15.28% of participants indicated our synthesized gestures appear more plausible, and around 16.32% of participants felt the gestures had more appropriate affective expressions aligned with the speech.
Learning Unseen Emotions from Gestures via Semantically-Conditioned Zero-Shot Perception with Adversarial Autoencoders
Sep 18, 2020
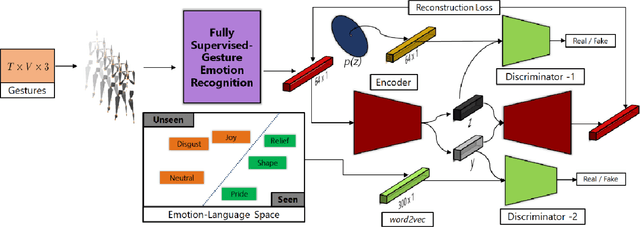

We present a novel generalized zero-shot algorithm to recognize perceived emotions from gestures. Our task is to map gestures to novel emotion categories not encountered in training. We introduce an adversarial, autoencoder-based representation learning that correlates 3D motion-captured gesture sequence with the vectorized representation of the natural-language perceived emotion terms using word2vec embeddings. The language-semantic embedding provides a representation of the emotion label space, and we leverage this underlying distribution to map the gesture-sequences to the appropriate categorical emotion labels. We train our method using a combination of gestures annotated with known emotion terms and gestures not annotated with any emotions. We evaluate our method on the MPI Emotional Body Expressions Database (EBEDB) and obtain an accuracy of $58.43\%$. This improves the performance of current state-of-the-art algorithms for generalized zero-shot learning by $25$--$27\%$ on the absolute.
Emotions Don't Lie: A Deepfake Detection Method using Audio-Visual Affective Cues
Mar 17, 2020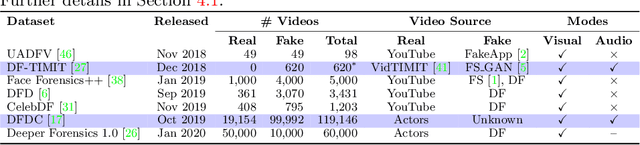
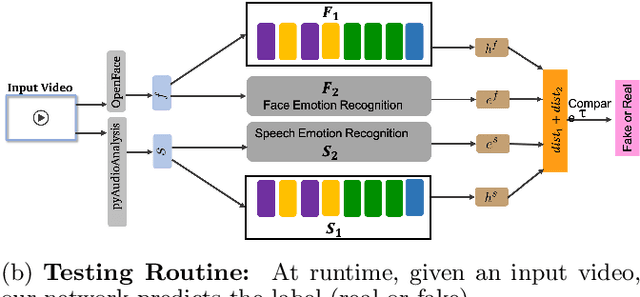
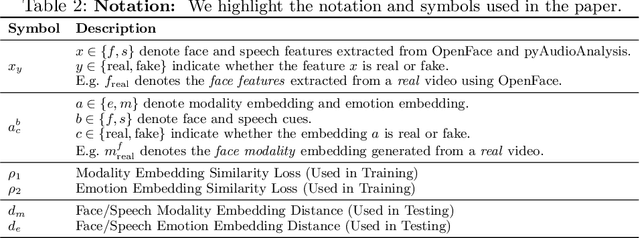

We present a learning-based multimodal method for detecting real and deepfake videos. To maximize information for learning, we extract and analyze the similarity between the two audio and visual modalities from within the same video. Additionally, we extract and compare affective cues corresponding to emotion from the two modalities within a video to infer whether the input video is "real" or "fake". We propose a deep learning network, inspired by the Siamese network architecture and the triplet loss. To validate our model, we report the AUC metric on two large-scale, audio-visual deepfake detection datasets, DeepFake-TIMIT Dataset and DFDC. We compare our approach with several SOTA deepfake detection methods and report per-video AUC of 84.4% on the DFDC and 96.6% on the DF-TIMIT datasets, respectively.
EmotiCon: Context-Aware Multimodal Emotion Recognition using Frege's Principle
Mar 14, 2020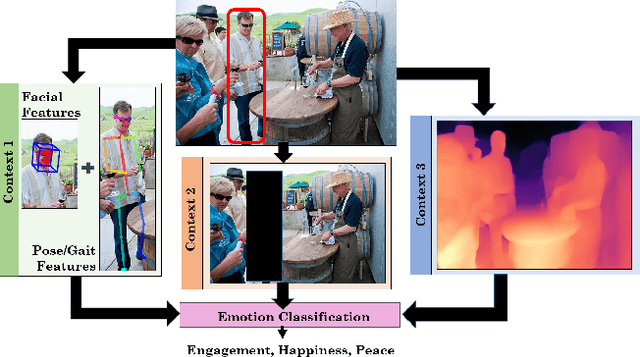
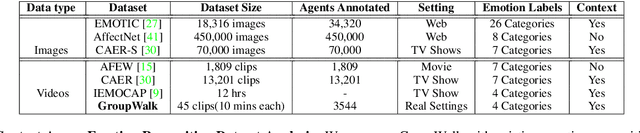
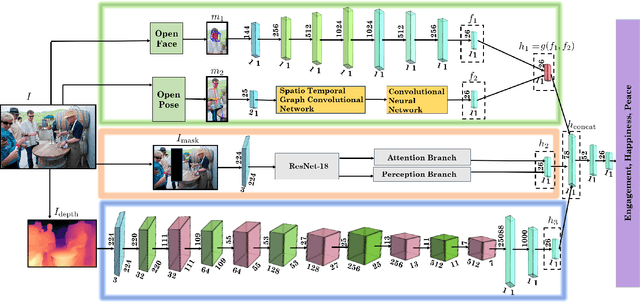
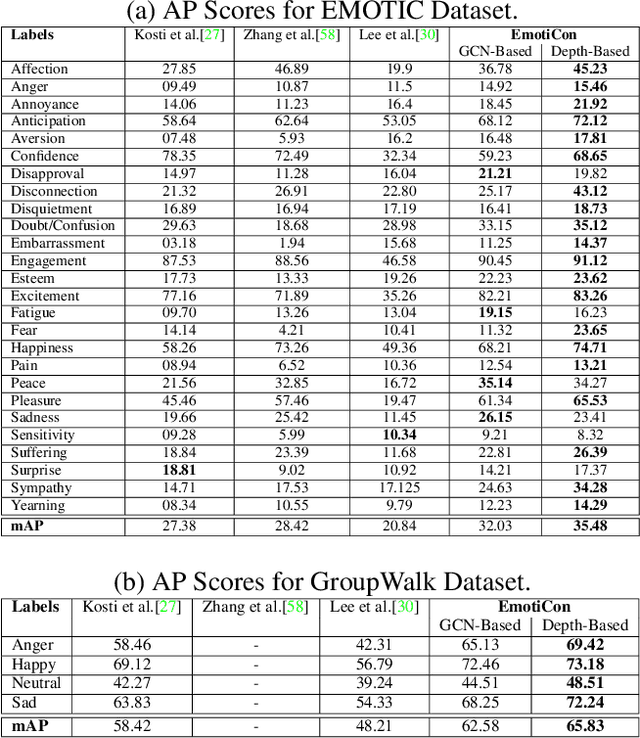
We present EmotiCon, a learning-based algorithm for context-aware perceived human emotion recognition from videos and images. Motivated by Frege's Context Principle from psychology, our approach combines three interpretations of context for emotion recognition. Our first interpretation is based on using multiple modalities(e.g. faces and gaits) for emotion recognition. For the second interpretation, we gather semantic context from the input image and use a self-attention-based CNN to encode this information. Finally, we use depth maps to model the third interpretation related to socio-dynamic interactions and proximity among agents. We demonstrate the efficiency of our network through experiments on EMOTIC, a benchmark dataset. We report an Average Precision (AP) score of 35.48 across 26 classes, which is an improvement of 7-8 over prior methods. We also introduce a new dataset, GroupWalk, which is a collection of videos captured in multiple real-world settings of people walking. We report an AP of 65.83 across 4 categories on GroupWalk, which is also an improvement over prior methods.
CMetric: A Driving Behavior Measure Using Centrality Functions
Mar 09, 2020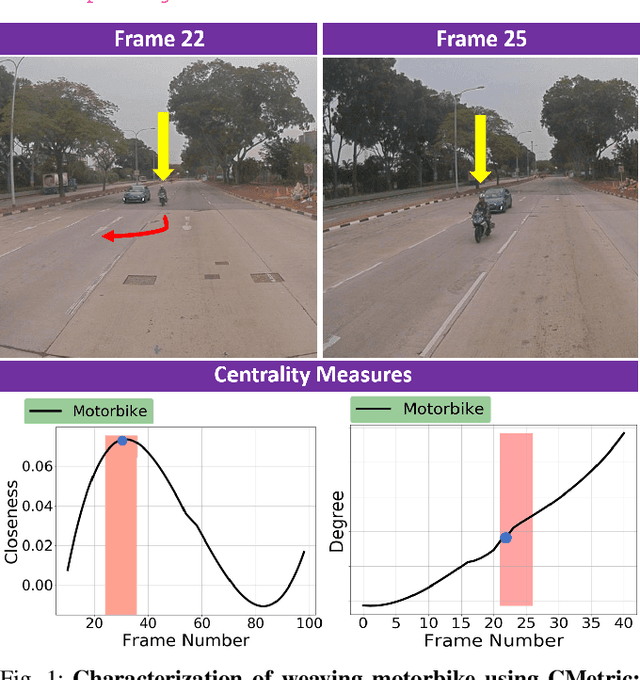
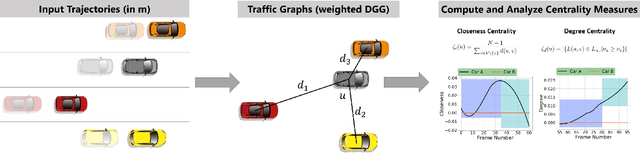
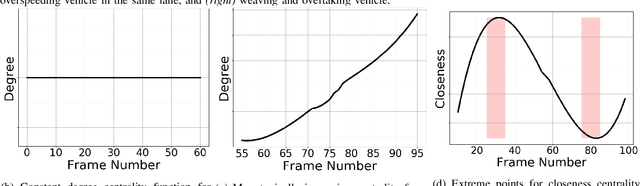
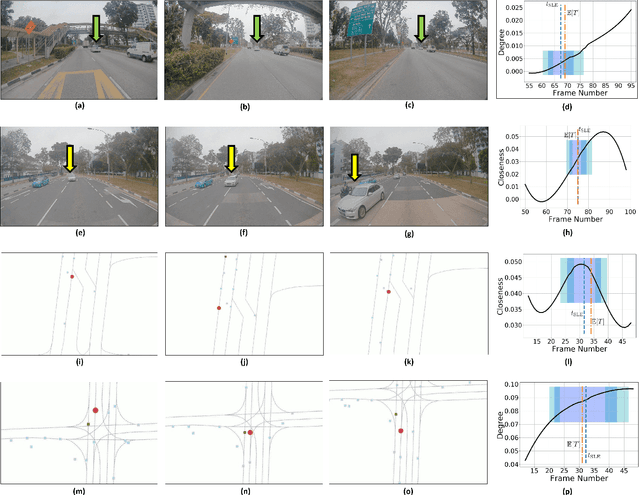
We present a new measure, CMetric, to classify driver behaviors using centrality functions. Our formulation combines concepts from computational graph theory and social traffic psychology to quantify and classify the behavior of human drivers. CMetric is used to compute the probability of a vehicle executing a driving style, as well as the intensity used to execute the style. Our approach is designed for realtime autonomous driving applications, where the trajectory of each vehicle or road-agent is extracted from a video. We compute a dynamic geometric graph (DGG) based on the positions and proximity of the road-agents and centrality functions corresponding to closeness and degree. These functions are used to compute the CMetric based on style likelihood and style intensity estimates. Our approach is general and makes no assumption about traffic density, heterogeneity, or how driving behaviors change over time. We present efficient techniques to compute CMetric and demonstrate its performance on well-known autonomous driving datasets. We evaluate the accuracy of CMetric and compare with ground truth behavior labels and with that of a human observer by performing a user study over over a long vehicle trajectory.
The Liar's Walk: Detecting Deception with Gait and Gesture
Dec 20, 2019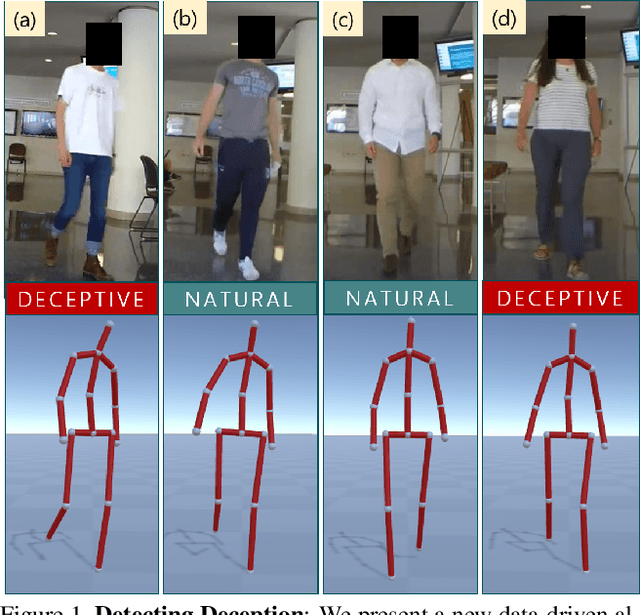
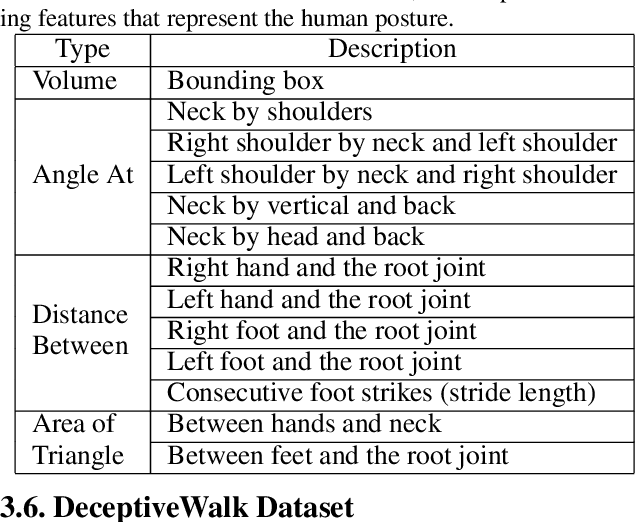
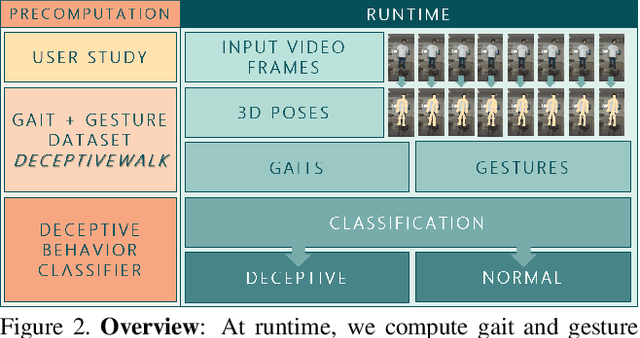

We present a data-driven deep neural algorithm for detecting deceptive walking behavior using nonverbal cues like gaits and gestures. We conducted an elaborate user study, where we recorded many participants performing tasks involving deceptive walking. We extract the participants' walking gaits as series of 3D poses. We annotate various gestures performed by participants during their tasks. Based on the gait and gesture data, we train an LSTM-based deep neural network to obtain deep features. Finally, we use a combination of psychology-based gait, gesture, and deep features to detect deceptive walking with an accuracy of 93.4%. This is an improvement of 16.1% over handcrafted gait and gesture features and an improvement of 5.9% and 10.1% over classifiers based on the state-of-the-art emotion and action classification algorithms, respectively. Additionally, we present a novel dataset, DeceptiveWalk, that contains gaits and gestures with their associated deception labels. To the best of our knowledge, ours is the first algorithm to detect deceptive behavior using non-verbal cues of gait and gesture.
Forecasting Trajectory and Behavior of Road-Agents Using Spectral Clustering in Graph-LSTMs
Dec 02, 2019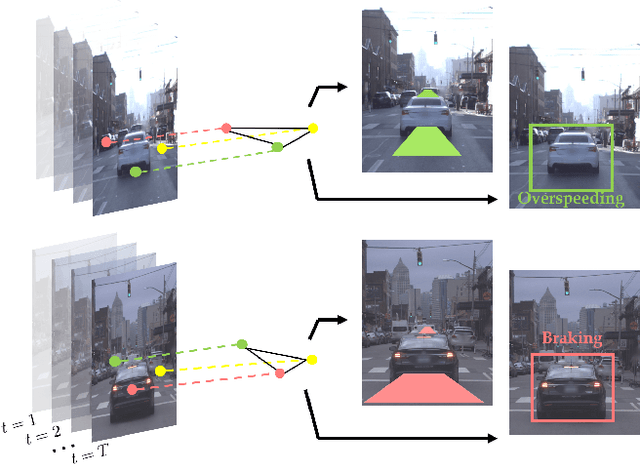

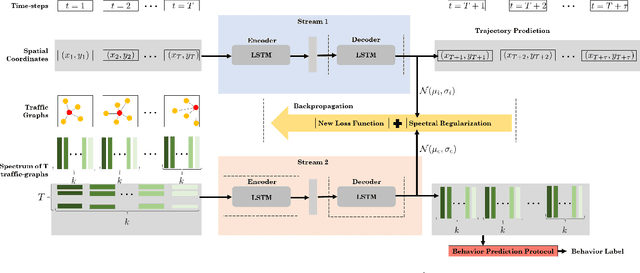

We present a novel approach for traffic forecasting in urban traffic scenarios using a combination of spectral graph analysis and deep learning. We predict both the low-level information (future trajectories) as well as the high-level information (road-agent behavior) from the extracted trajectory of each road-agent. Our formulation represents the proximity between the road agents using a dynamic weighted traffic-graph. We use a two-stream graph convolutional LSTM network to perform traffic forecasting using these weighted traffic-graphs. The first stream predicts the spatial coordinates of road-agents, while the second stream predicts whether a road-agent is going to exhibit aggressive, conservative, or normal behavior. We introduce spectral cluster regularization to reduce the error margin in long-term prediction (3-5 seconds) and improve the accuracy of the predicted trajectories. We evaluate our approach on the Argoverse, Lyft, and Apolloscape datasets and highlight the benefits over prior trajectory prediction methods. In practice, our approach reduces the average prediction error by more than 54% over prior algorithms and achieves a weighted average accuracy of 91.2% for behavior prediction.
M3ER: Multiplicative Multimodal Emotion Recognition Using Facial, Textual, and Speech Cues
Nov 22, 2019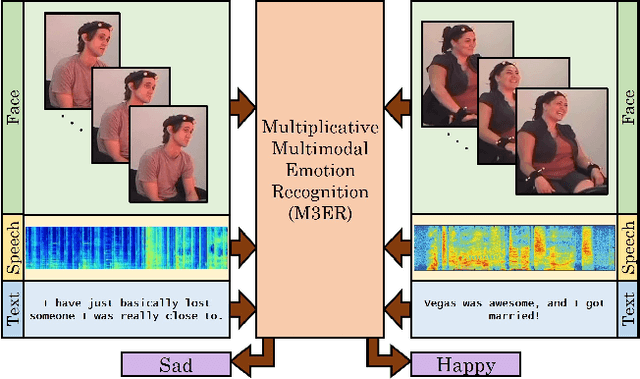
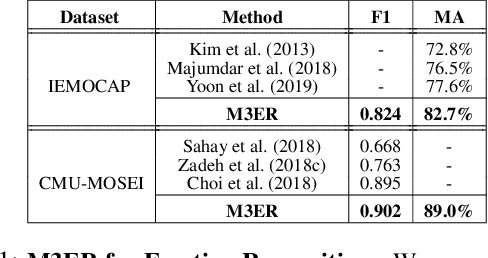
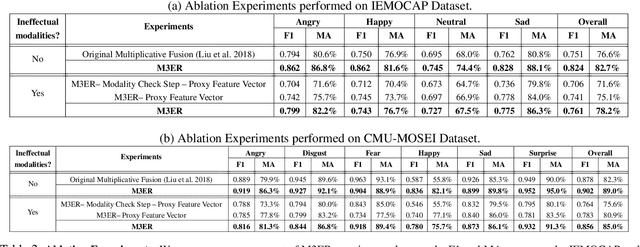
We present M3ER, a learning-based method for emotion recognition from multiple input modalities. Our approach combines cues from multiple co-occurring modalities (such as face, text, and speech) and also is more robust than other methods to sensor noise in any of the individual modalities. M3ER models a novel, data-driven multiplicative fusion method to combine the modalities, which learn to emphasize the more reliable cues and suppress others on a per-sample basis. By introducing a check step which uses Canonical Correlational Analysis to differentiate between ineffective and effective modalities, M3ER is robust to sensor noise. M3ER also generates proxy features in place of the ineffectual modalities. We demonstrate the efficiency of our network through experimentation on two benchmark datasets, IEMOCAP and CMU-MOSEI. We report a mean accuracy of 82.7% on IEMOCAP and 89.0% on CMU-MOSEI, which, collectively, is an improvement of about 5% over prior work.
Take an Emotion Walk: Perceiving Emotions from Gaits Using Hierarchical Attention Pooling and Affective Mapping
Nov 20, 2019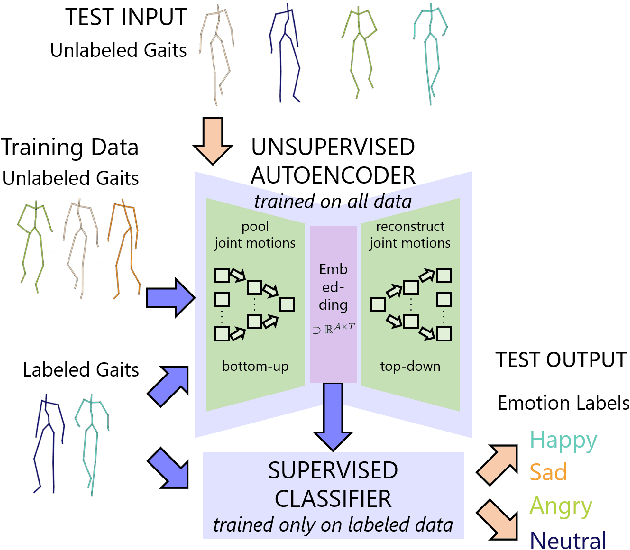

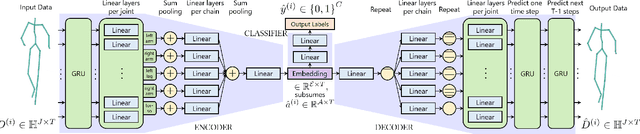
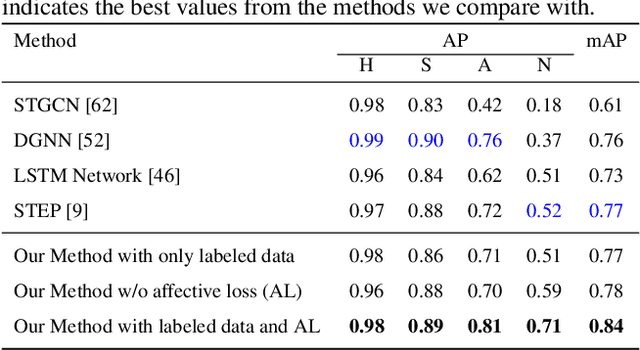
We present an autoencoder-based semi-supervised approach to classify perceived human emotions from walking styles obtained from videos or from motion-captured data and represented as sequences of 3D poses. Given the motion on each joint in the pose at each time step extracted from 3D pose sequences, we hierarchically pool these joint motions in a bottom-up manner in the encoder, following the kinematic chains in the human body. We also constrain the latent embeddings of the encoder to contain the space of psychologically-motivated affective features underlying the gaits. We train the decoder to reconstruct the motions per joint per time step in a top-down manner from the latent embeddings. For the annotated data, we also train a classifier to map the latent embeddings to emotion labels. Our semi-supervised approach achieves a mean average precision of 0.84 on the Emotion-Gait benchmark dataset, which contains gaits collected from multiple sources. We outperform current state-of-art algorithms for both emotion recognition and action recognition from 3D gaits by 7% -- 23% on the absolute.