 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlurb-Refined Inference from Crowdsourced Book Reviews using Hierarchical Genre Mining with Dual-Path Graph Convolutions
Dec 24, 2025Accurate book genre classification is fundamental to digital library organization, content discovery, and personalized recommendation. Existing approaches typically model genre prediction as a flat, single-label task, ignoring hierarchical genre structure and relying heavily on noisy, subjective user reviews, which often degrade classification reliability. We propose HiGeMine, a two-phase hierarchical genre mining framework that robustly integrates user reviews with authoritative book blurbs. In the first phase, HiGeMine employs a zero-shot semantic alignment strategy to filter reviews, retaining only those semantically consistent with the corresponding blurb, thereby mitigating noise, bias, and irrelevance. In the second phase, we introduce a dual-path, two-level graph-based classification architecture: a coarse-grained Level-1 binary classifier distinguishes fiction from non-fiction, followed by Level-2 multi-label classifiers for fine-grained genre prediction. Inter-genre dependencies are explicitly modeled using a label co-occurrence graph, while contextual representations are derived from pretrained language models applied to the filtered textual content. To facilitate systematic evaluation, we curate a new hierarchical book genre dataset. Extensive experiments demonstrate that HiGeMine consistently outperformed strong baselines across hierarchical genre classification tasks. The proposed framework offers a principled and effective solution for leveraging both structured and unstructured textual data in hierarchical book genre analysis.
ProtoSiTex: Learning Semi-Interpretable Prototypes for Multi-label Text Classification
Oct 14, 2025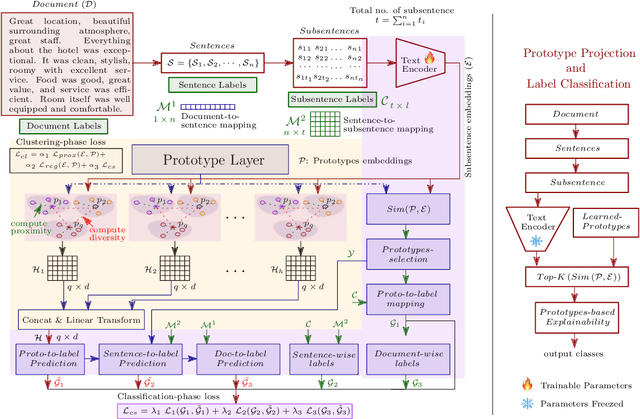
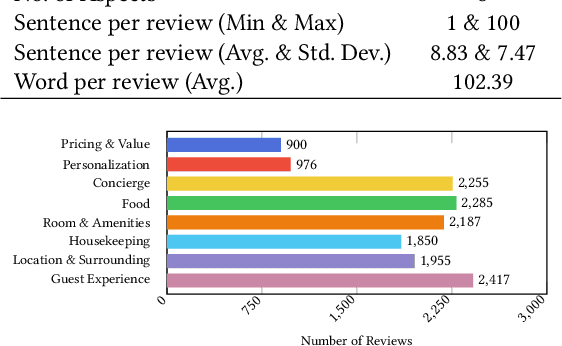
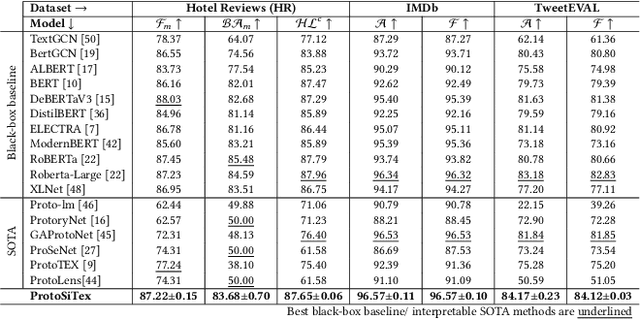
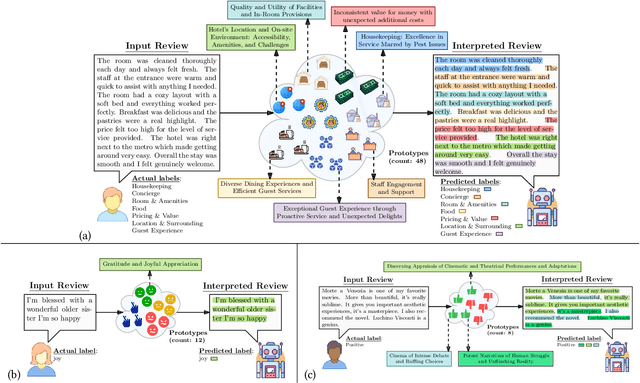
The surge in user-generated reviews has amplified the need for interpretable models that can provide fine-grained insights. Existing prototype-based models offer intuitive explanations but typically operate at coarse granularity (sentence or document level) and fail to address the multi-label nature of real-world text classification. We propose ProtoSiTex, a semi-interpretable framework designed for fine-grained multi-label text classification. ProtoSiTex employs a dual-phase alternating training strategy: an unsupervised prototype discovery phase that learns semantically coherent and diverse prototypes, and a supervised classification phase that maps these prototypes to class labels. A hierarchical loss function enforces consistency across sub-sentence, sentence, and document levels, enhancing interpretability and alignment. Unlike prior approaches, ProtoSiTex captures overlapping and conflicting semantics using adaptive prototypes and multi-head attention. We also introduce a benchmark dataset of hotel reviews annotated at the sub-sentence level with multiple labels. Experiments on this dataset and two public benchmarks (binary and multi-class) show that ProtoSiTex achieves state-of-the-art performance while delivering faithful, human-aligned explanations, establishing it as a robust solution for semi-interpretable multi-label text classification.
An Adaptive Data-Resilient Multi-Modal Framework for Hierarchical Multi-Label Book Genre Identification
May 05, 2025



Identifying the finer details of a book's genres enhances user experience by enabling efficient book discovery and personalized recommendations, ultimately improving reader engagement and satisfaction. It also provides valuable insights into market trends and consumer preferences, allowing publishers and marketers to make data-driven decisions regarding book production and marketing strategies. While traditional book genre classification methods primarily rely on review data or textual analysis, incorporating additional modalities, such as book covers, blurbs, and metadata, can offer richer context and improve prediction accuracy. However, the presence of incomplete or noisy information across these modalities presents a significant challenge. This paper introduces IMAGINE (Intelligent Multi-modal Adaptive Genre Identification NEtwork), a framework designed to address these complexities. IMAGINE extracts robust feature representations from multiple modalities and dynamically selects the most informative sources based on data availability. It employs a hierarchical classification strategy to capture genre relationships and remains adaptable to varying input conditions. Additionally, we curate a hierarchical genre classification dataset that structures genres into a well-defined taxonomy, accommodating the diverse nature of literary works. IMAGINE integrates information from multiple sources and assigns multiple genre labels to each book, ensuring a more comprehensive classification. A key feature of our framework is its resilience to incomplete data, enabling accurate predictions even when certain modalities, such as text, images, or metadata, are missing or incomplete. Experimental results show that IMAGINE outperformed existing baselines in genre classification accuracy, particularly in scenarios with insufficient modality-specific data.
Demystifying Visual Features of Movie Posters for Multi-Label Genre Identification
Sep 21, 2023



In the film industry, movie posters have been an essential part of advertising and marketing for many decades, and continue to play a vital role even today in the form of digital posters through online, social media and OTT platforms. Typically, movie posters can effectively promote and communicate the essence of a film, such as its genre, visual style/ tone, vibe and storyline cue/ theme, which are essential to attract potential viewers. Identifying the genres of a movie often has significant practical applications in recommending the film to target audiences. Previous studies on movie genre identification are limited to subtitles, plot synopses, and movie scenes that are mostly accessible after the movie release. Posters usually contain pre-release implicit information to generate mass interest. In this paper, we work for automated multi-label genre identification only from movie poster images, without any aid of additional textual/meta-data information about movies, which is one of the earliest attempts of its kind. Here, we present a deep transformer network with a probabilistic module to identify the movie genres exclusively from the poster. For experimental analysis, we procured 13882 number of posters of 13 genres from the Internet Movie Database (IMDb), where our model performances were encouraging and even outperformed some major contemporary architectures.