 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Multi-Persona Framework for Evidence-Aware Fake News Detection
Dec 24, 2025The rapid proliferation of online misinformation poses significant risks to public trust, policy, and safety, necessitating reliable automated fake news detection. Existing methods often struggle with multimodal content, domain generalization, and explainability. We propose AMPEND-LS, an agentic multi-persona evidence-grounded framework with LLM-SLM synergy for multimodal fake news detection. AMPEND-LS integrates textual, visual, and contextual signals through a structured reasoning pipeline powered by LLMs, augmented with reverse image search, knowledge graph paths, and persuasion strategy analysis. To improve reliability, we introduce a credibility fusion mechanism combining semantic similarity, domain trustworthiness, and temporal context, and a complementary SLM classifier to mitigate LLM uncertainty and hallucinations. Extensive experiments across three benchmark datasets demonstrate that AMPEND-LS consistently outperformed state-of-the-art baselines in accuracy, F1 score, and robustness. Qualitative case studies further highlight its transparent reasoning and resilience against evolving misinformation. This work advances the development of adaptive, explainable, and evidence-aware systems for safeguarding online information integrity.
ProtoSiTex: Learning Semi-Interpretable Prototypes for Multi-label Text Classification
Oct 14, 2025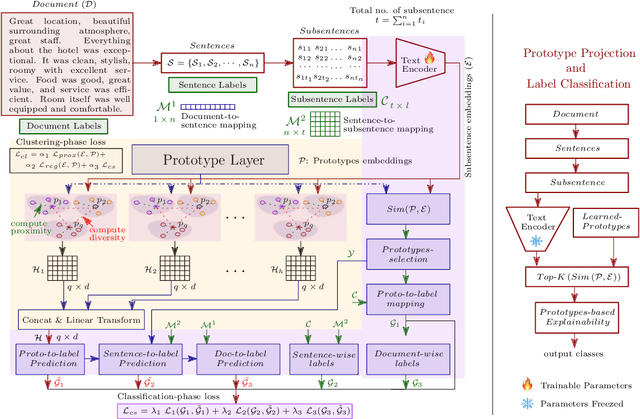
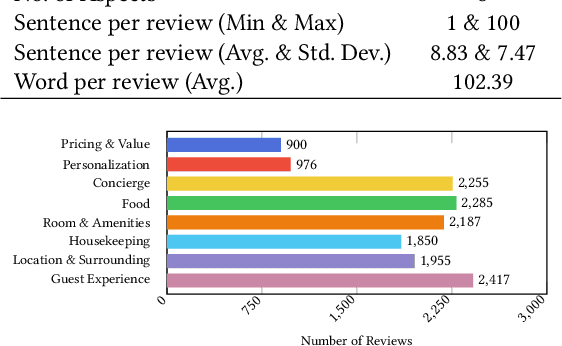
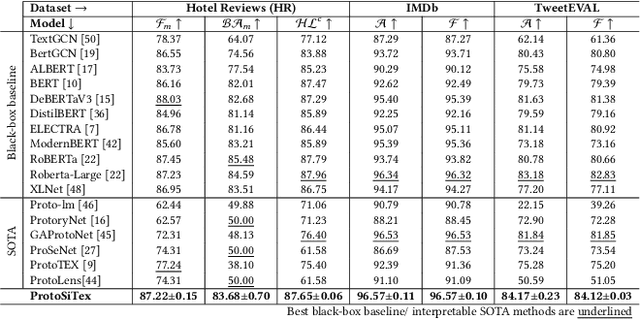
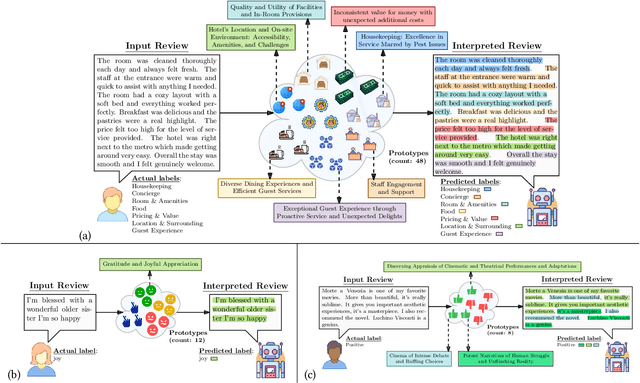
The surge in user-generated reviews has amplified the need for interpretable models that can provide fine-grained insights. Existing prototype-based models offer intuitive explanations but typically operate at coarse granularity (sentence or document level) and fail to address the multi-label nature of real-world text classification. We propose ProtoSiTex, a semi-interpretable framework designed for fine-grained multi-label text classification. ProtoSiTex employs a dual-phase alternating training strategy: an unsupervised prototype discovery phase that learns semantically coherent and diverse prototypes, and a supervised classification phase that maps these prototypes to class labels. A hierarchical loss function enforces consistency across sub-sentence, sentence, and document levels, enhancing interpretability and alignment. Unlike prior approaches, ProtoSiTex captures overlapping and conflicting semantics using adaptive prototypes and multi-head attention. We also introduce a benchmark dataset of hotel reviews annotated at the sub-sentence level with multiple labels. Experiments on this dataset and two public benchmarks (binary and multi-class) show that ProtoSiTex achieves state-of-the-art performance while delivering faithful, human-aligned explanations, establishing it as a robust solution for semi-interpretable multi-label text classification.