 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Spatiotemporal Prediction with Bayesian Neural Fields
Mar 12, 2024Spatiotemporal datasets, which consist of spatially-referenced time series, are ubiquitous in many scientific and business-intelligence applications, such as air pollution monitoring, disease tracking, and cloud-demand forecasting. As modern datasets continue to increase in size and complexity, there is a growing need for new statistical methods that are flexible enough to capture complex spatiotemporal dynamics and scalable enough to handle large prediction problems. This work presents the Bayesian Neural Field (BayesNF), a domain-general statistical model for inferring rich probability distributions over a spatiotemporal domain, which can be used for data-analysis tasks including forecasting, interpolation, and variography. BayesNF integrates a novel deep neural network architecture for high-capacity function estimation with hierarchical Bayesian inference for robust uncertainty quantification. By defining the prior through a sequence of smooth differentiable transforms, posterior inference is conducted on large-scale data using variationally learned surrogates trained via stochastic gradient descent. We evaluate BayesNF against prominent statistical and machine-learning baselines, showing considerable improvements on diverse prediction problems from climate and public health datasets that contain tens to hundreds of thousands of measurements. The paper is accompanied with an open-source software package (https://github.com/google/bayesnf) that is easy-to-use and compatible with modern GPU and TPU accelerators on the JAX machine learning platform.
Adaptive Braking for Mitigating Gradient Delay
Jul 10, 2020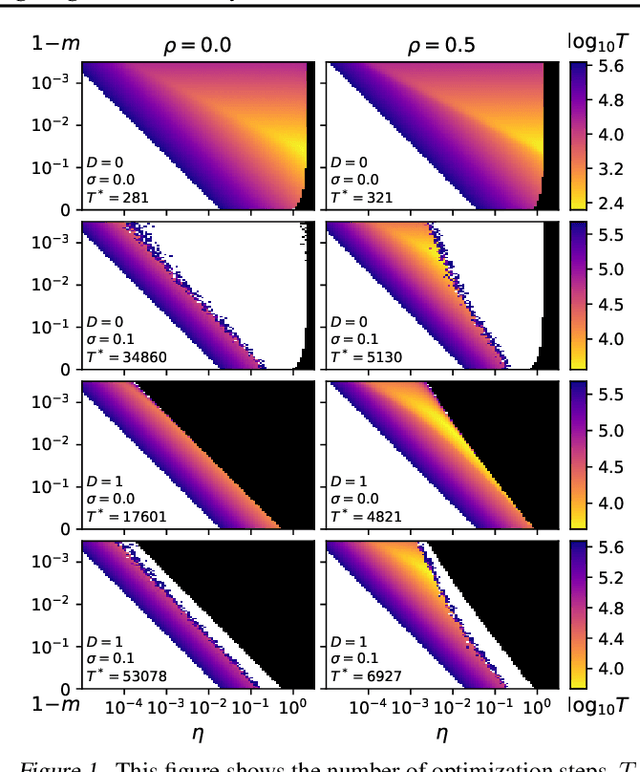
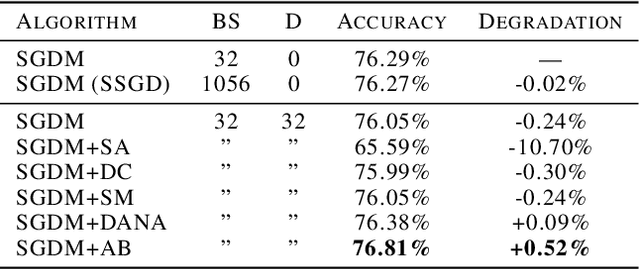
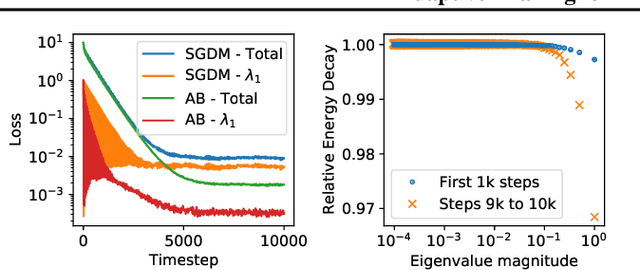
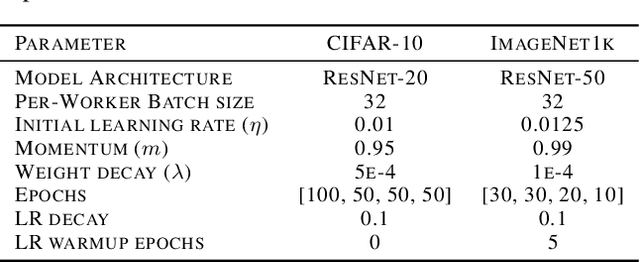
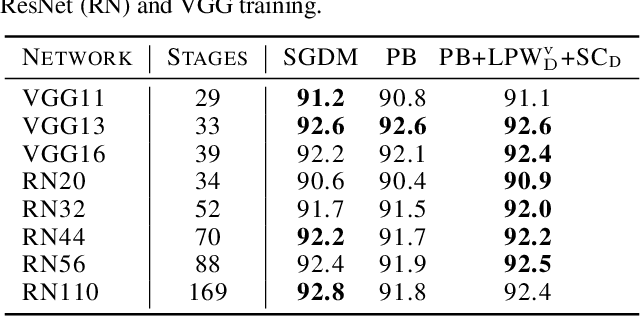
Neural network training is commonly accelerated by using multiple synchronized workers to compute gradient updates in parallel. Asynchronous methods remove synchronization overheads and improve hardware utilization at the cost of introducing gradient delay, which impedes optimization and can lead to lower final model performance. We introduce Adaptive Braking (AB), a modification for momentum-based optimizers that mitigates the effects of gradient delay. AB dynamically scales the gradient based on the alignment of the gradient and the velocity. This can dampen oscillations along high curvature directions of the loss surface, stabilizing and accelerating asynchronous training. We show that applying AB on top of SGD with momentum enables training ResNets on CIFAR-10 and ImageNet-1k with delays $D \geq$ 32 update steps with minimal drop in final test accuracy.
Pipelined Backpropagation at Scale: Training Large Models without Batches
Mar 25, 2020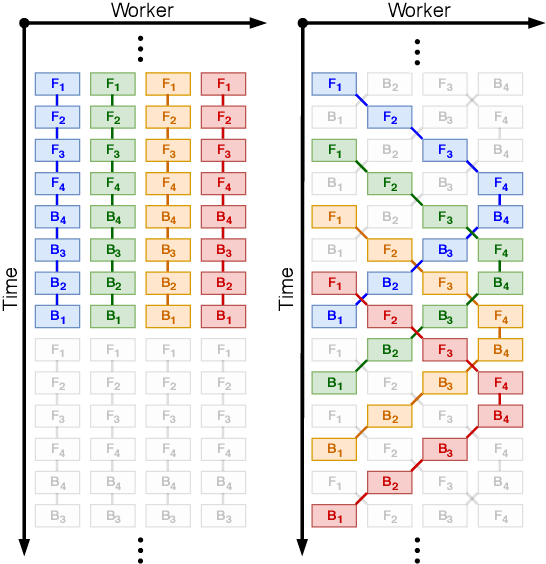
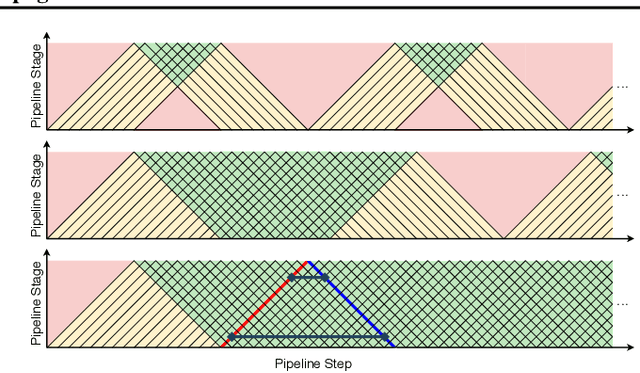
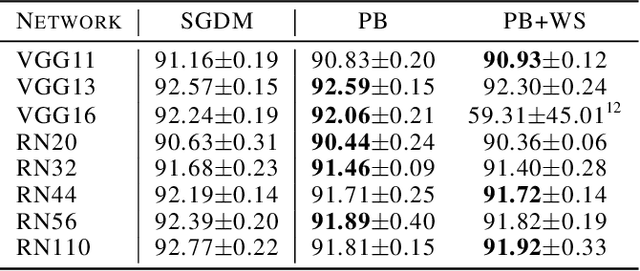
Parallelism is crucial for accelerating the training of deep neural networks. Pipeline parallelism can provide an efficient alternative to traditional data parallelism by allowing workers to specialize. Performing mini-batch SGD using pipeline parallelism has the overhead of filling and draining the pipeline. Pipelined Backpropagation updates the model parameters without draining the pipeline. This removes the overhead but introduces stale gradients and inconsistency between the weights used on the forward and backward passes, reducing final accuracy and the stability of training. We introduce Spike Compensation and Linear Weight Prediction to mitigate these effects. Analysis on a convex quadratic shows that both methods effectively counteract staleness. We train multiple convolutional networks at a batch size of one, completely replacing batch parallelism with fine-grained pipeline parallelism. With our methods, Pipelined Backpropagation achieves full accuracy on CIFAR-10 and ImageNet without hyperparameter tuning.
Flexpoint: An Adaptive Numerical Format for Efficient Training of Deep Neural Networks
Dec 02, 2017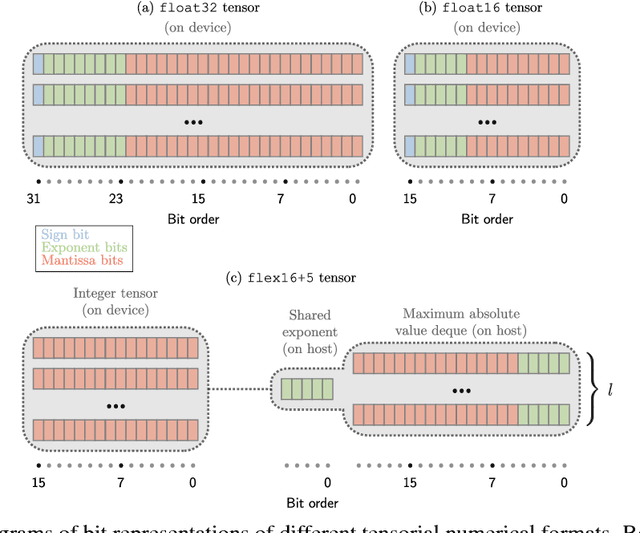
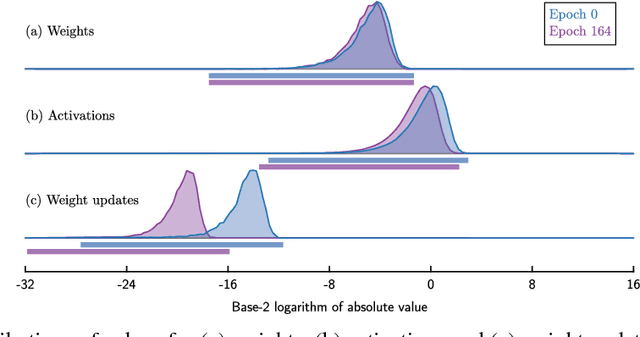
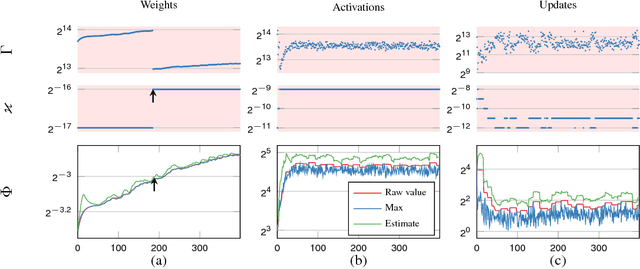
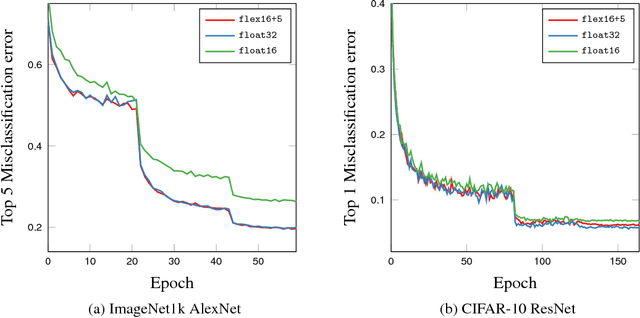
Deep neural networks are commonly developed and trained in 32-bit floating point format. Significant gains in performance and energy efficiency could be realized by training and inference in numerical formats optimized for deep learning. Despite advances in limited precision inference in recent years, training of neural networks in low bit-width remains a challenging problem. Here we present the Flexpoint data format, aiming at a complete replacement of 32-bit floating point format training and inference, designed to support modern deep network topologies without modifications. Flexpoint tensors have a shared exponent that is dynamically adjusted to minimize overflows and maximize available dynamic range. We validate Flexpoint by training AlexNet, a deep residual network and a generative adversarial network, using a simulator implemented with the neon deep learning framework. We demonstrate that 16-bit Flexpoint closely matches 32-bit floating point in training all three models, without any need for tuning of model hyperparameters. Our results suggest Flexpoint as a promising numerical format for future hardware for training and inference.