 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSINCO: A Novel structural regularizer for image compression using implicit neural representations
Oct 26, 2022Implicit neural representations (INR) have been recently proposed as deep learning (DL) based solutions for image compression. An image can be compressed by training an INR model with fewer weights than the number of image pixels to map the coordinates of the image to corresponding pixel values. While traditional training approaches for INRs are based on enforcing pixel-wise image consistency, we propose to further improve image quality by using a new structural regularizer. We present structural regularization for INR compression (SINCO) as a novel INR method for image compression. SINCO imposes structural consistency of the compressed images to the groundtruth by using a segmentation network to penalize the discrepancy of segmentation masks predicted from compressed images. We validate SINCO on brain MRI images by showing that it can achieve better performance than some recent INR methods.
CoRRECT: A Deep Unfolding Framework for Motion-Corrected Quantitative R2* Mapping
Oct 12, 2022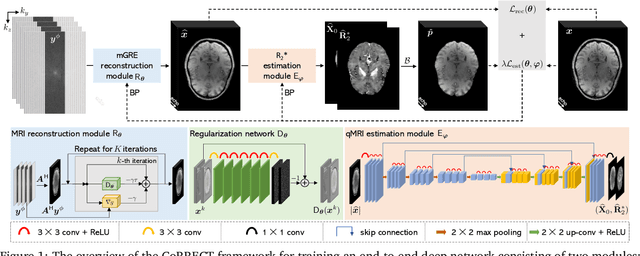
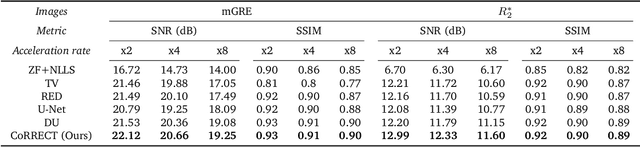
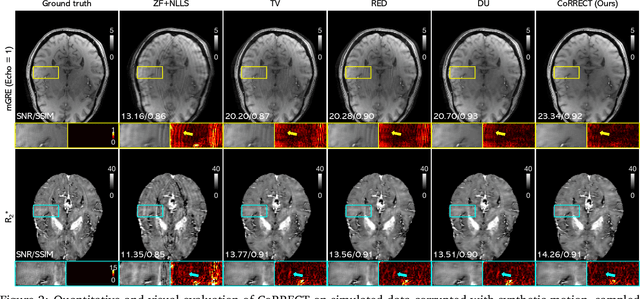
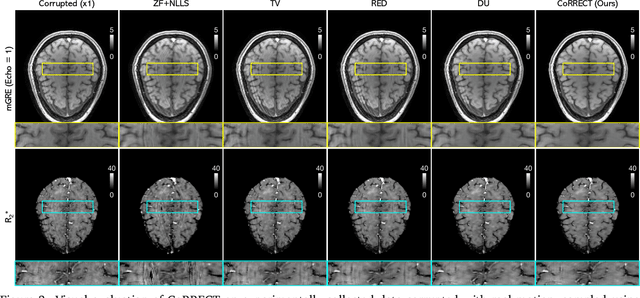
Quantitative MRI (qMRI) refers to a class of MRI methods for quantifying the spatial distribution of biological tissue parameters. Traditional qMRI methods usually deal separately with artifacts arising from accelerated data acquisition, involuntary physical motion, and magnetic-field inhomogeneities, leading to suboptimal end-to-end performance. This paper presents CoRRECT, a unified deep unfolding (DU) framework for qMRI consisting of a model-based end-to-end neural network, a method for motion-artifact reduction, and a self-supervised learning scheme. The network is trained to produce R2* maps whose k-space data matches the real data by also accounting for motion and field inhomogeneities. When deployed, CoRRECT only uses the k-space data without any pre-computed parameters for motion or inhomogeneity correction. Our results on experimentally collected multi-Gradient-Recalled Echo (mGRE) MRI data show that CoRRECT recovers motion and inhomogeneity artifact-free R2* maps in highly accelerated acquisition settings. This work opens the door to DU methods that can integrate physical measurement models, biophysical signal models, and learned prior models for high-quality qMRI.
Self-Supervised Deep Equilibrium Models for Inverse Problems with Theoretical Guarantees
Oct 07, 2022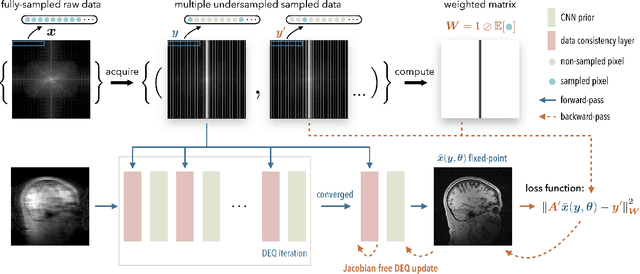
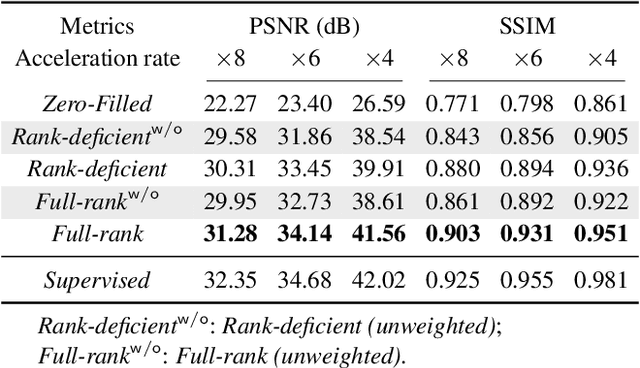
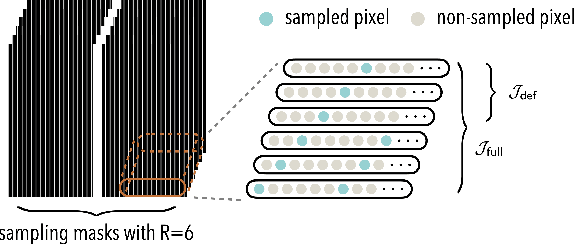
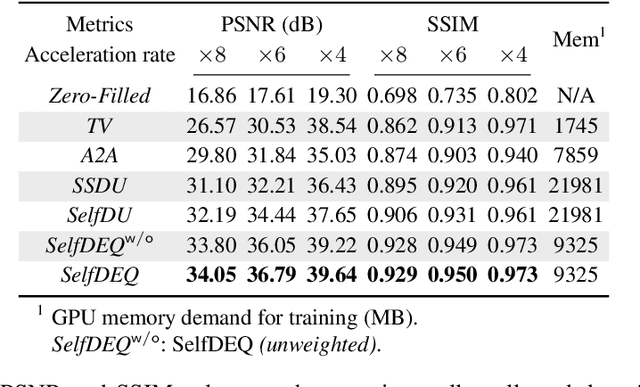
Deep equilibrium models (DEQ) have emerged as a powerful alternative to deep unfolding (DU) for image reconstruction. DEQ models-implicit neural networks with effectively infinite number of layers-were shown to achieve state-of-the-art image reconstruction without the memory complexity associated with DU. While the performance of DEQ has been widely investigated, the existing work has primarily focused on the settings where groundtruth data is available for training. We present self-supervised deep equilibrium model (SelfDEQ) as the first self-supervised reconstruction framework for training model-based implicit networks from undersampled and noisy MRI measurements. Our theoretical results show that SelfDEQ can compensate for unbalanced sampling across multiple acquisitions and match the performance of fully supervised DEQ. Our numerical results on in-vivo MRI data show that SelfDEQ leads to state-of-the-art performance using only undersampled and noisy training data.
SPICE: Self-Supervised Learning for MRI with Automatic Coil Sensitivity Estimation
Oct 05, 2022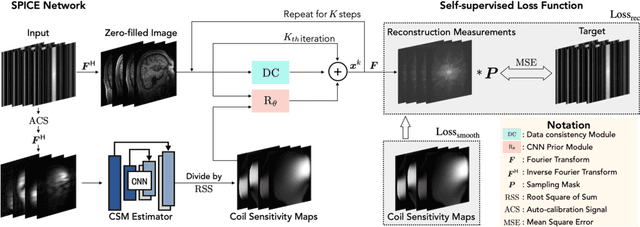
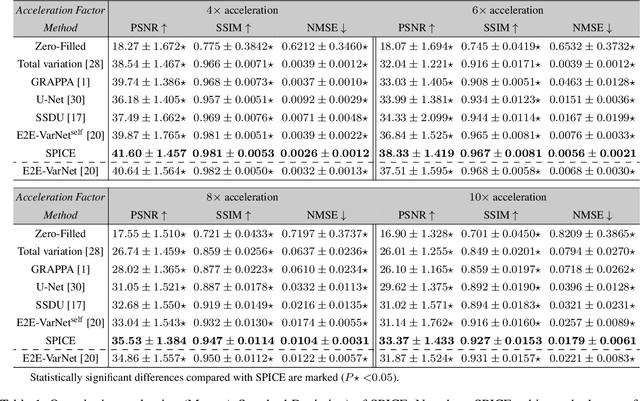
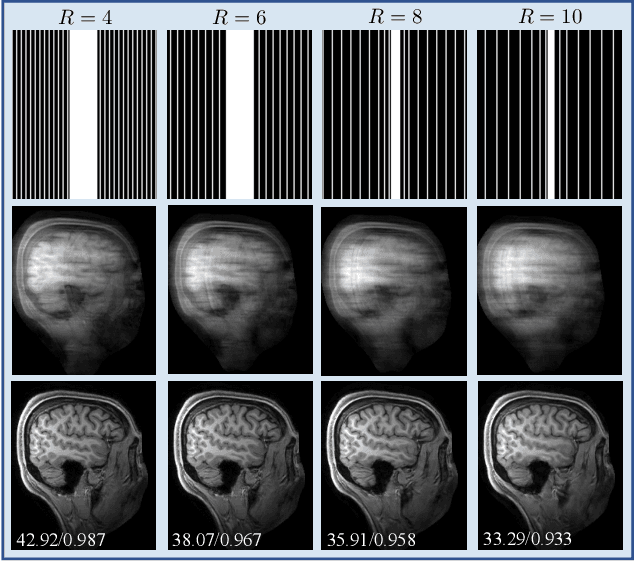
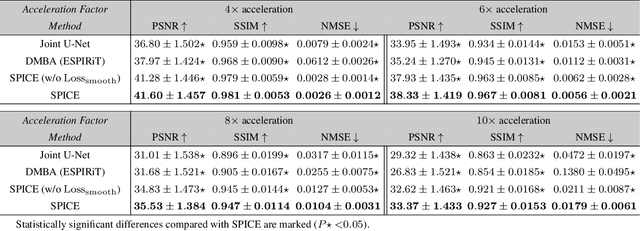
Deep model-based architectures (DMBAs) integrating physical measurement models and learned image regularizers are widely used in parallel magnetic resonance imaging (PMRI). Traditional DMBAs for PMRI rely on pre-estimated coil sensitivity maps (CSMs) as a component of the measurement model. However, estimation of accurate CSMs is a challenging problem when measurements are highly undersampled. Additionally, traditional training of DMBAs requires high-quality groundtruth images, limiting their use in applications where groundtruth is difficult to obtain. This paper addresses these issues by presenting SPICE as a new method that integrates self-supervised learning and automatic coil sensitivity estimation. Instead of using pre-estimated CSMs, SPICE simultaneously reconstructs accurate MR images and estimates high-quality CSMs. SPICE also enables learning from undersampled noisy measurements without any groundtruth. We validate SPICE on experimentally collected data, showing that it can achieve state-of-the-art performance in highly accelerated data acquisition settings (up to 10x).
Dual-Cycle: Self-Supervised Dual-View Fluorescence Microscopy Image Reconstruction using CycleGAN
Sep 23, 2022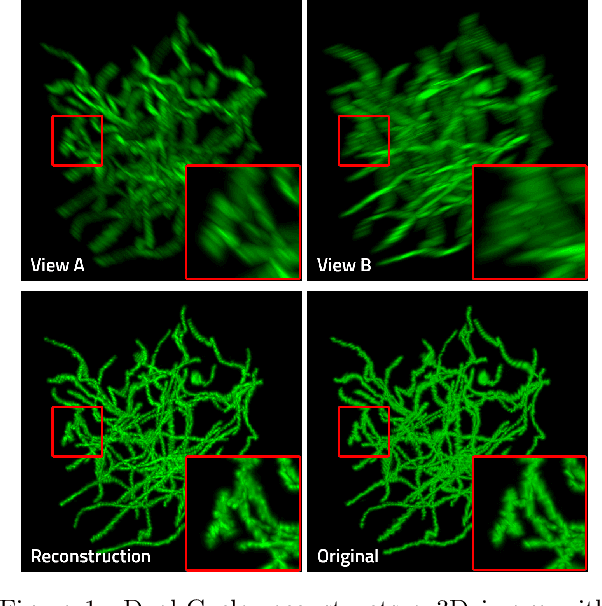

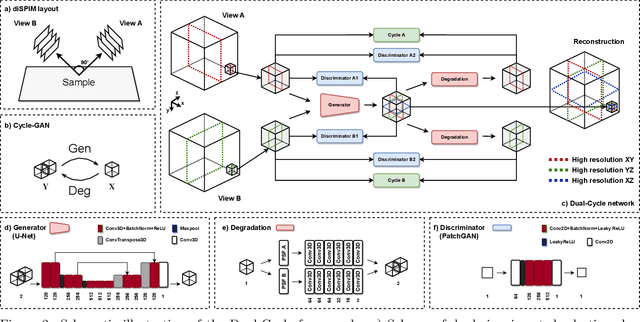
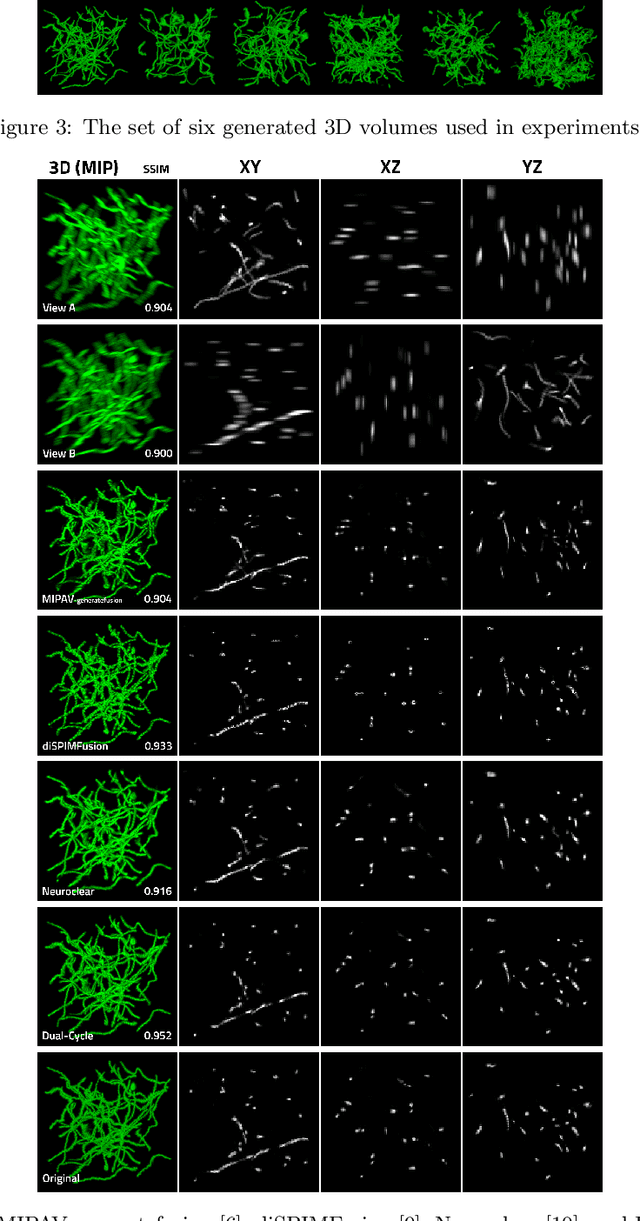
Three-dimensional fluorescence microscopy often suffers from anisotropy, where the resolution along the axial direction is lower than that within the lateral imaging plane. We address this issue by presenting Dual-Cycle, a new framework for joint deconvolution and fusion of dual-view fluorescence images. Inspired by the recent Neuroclear method, Dual-Cycle is designed as a cycle-consistent generative network trained in a self-supervised fashion by combining a dual-view generator and prior-guided degradation model. We validate Dual-Cycle on both synthetic and real data showing its state-of-the-art performance without any external training data.
Deep Model-Based Architectures for Inverse Problems under Mismatched Priors
Jul 26, 2022
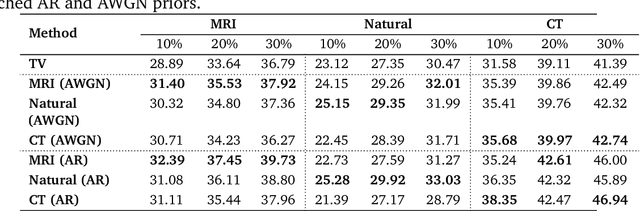
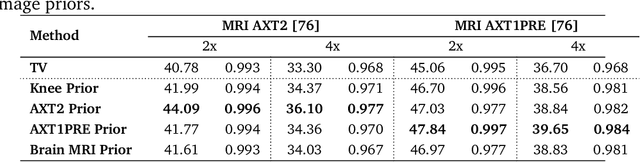
There is a growing interest in deep model-based architectures (DMBAs) for solving imaging inverse problems by combining physical measurement models and learned image priors specified using convolutional neural nets (CNNs). For example, well-known frameworks for systematically designing DMBAs include plug-and-play priors (PnP), deep unfolding (DU), and deep equilibrium models (DEQ). While the empirical performance and theoretical properties of DMBAs have been widely investigated, the existing work in the area has primarily focused on their performance when the desired image prior is known exactly. This work addresses the gap in the prior work by providing new theoretical and numerical insights into DMBAs under mismatched CNN priors. Mismatched priors arise naturally when there is a distribution shift between training and testing data, for example, due to test images being from a different distribution than images used for training the CNN prior. They also arise when the CNN prior used for inference is an approximation of some desired statistical estimator (MAP or MMSE). Our theoretical analysis provides explicit error bounds on the solution due to the mismatched CNN priors under a set of clearly specified assumptions. Our numerical results compare the empirical performance of DMBAs under realistic distribution shifts and approximate statistical estimators.
Online Deep Equilibrium Learning for Regularization by Denoising
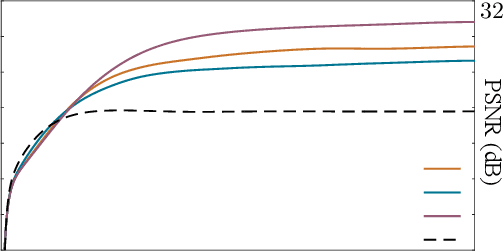
May 25, 2022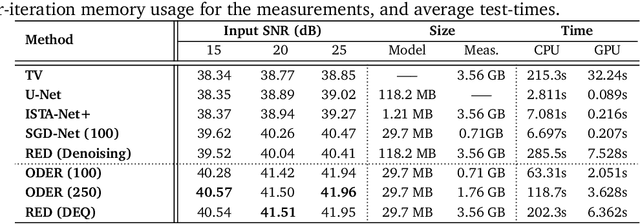
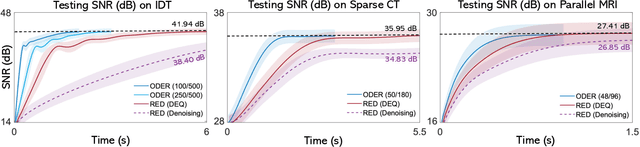
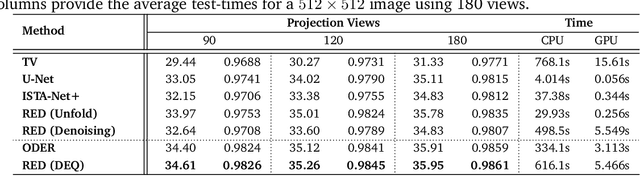
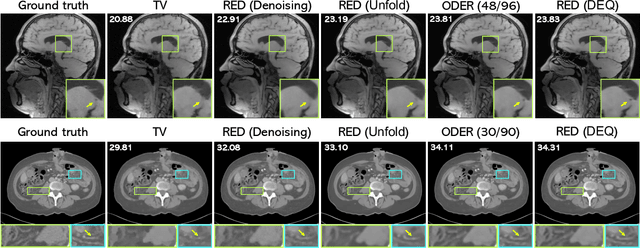
Plug-and-Play Priors (PnP) and Regularization by Denoising (RED) are widely-used frameworks for solving imaging inverse problems by computing fixed-points of operators combining physical measurement models and learned image priors. While traditional PnP/RED formulations have focused on priors specified using image denoisers, there is a growing interest in learning PnP/RED priors that are end-to-end optimal. The recent Deep Equilibrium Models (DEQ) framework has enabled memory-efficient end-to-end learning of PnP/RED priors by implicitly differentiating through the fixed-point equations without storing intermediate activation values. However, the dependence of the computational/memory complexity of the measurement models in PnP/RED on the total number of measurements leaves DEQ impractical for many imaging applications. We propose ODER as a new strategy for improving the efficiency of DEQ through stochastic approximations of the measurement models. We theoretically analyze ODER giving insights into its convergence and ability to approximate the traditional DEQ approach. Our numerical results suggest the potential improvements in training/testing complexity due to ODER on three distinct imaging applications.
Image Reconstruction for MRI using Deep CNN Priors Trained without Groundtruth
Apr 10, 2022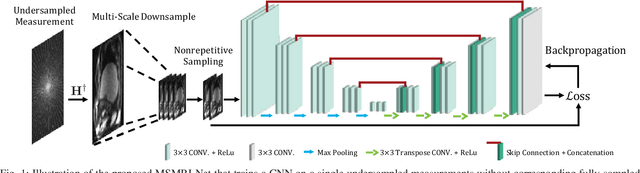
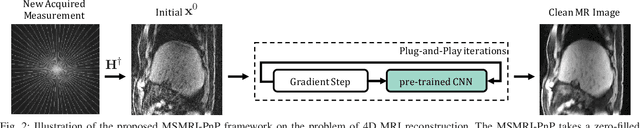
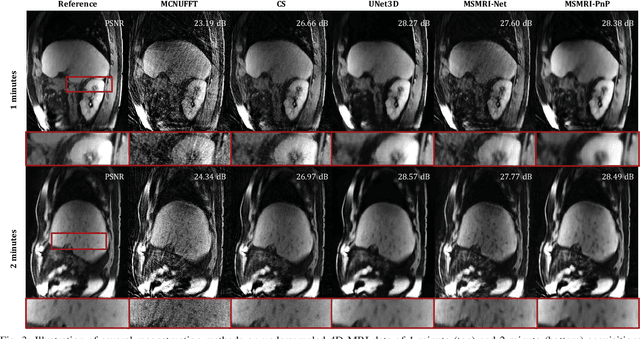
We propose a new plug-and-play priors (PnP) based MR image reconstruction method that systematically enforces data consistency while also exploiting deep-learning priors. Our prior is specified through a convolutional neural network (CNN) trained without any artifact-free ground truth to remove undersampling artifacts from MR images. The results on reconstructing free-breathing MRI data into ten respiratory phases show that the method can form high-quality 4D images from severely undersampled measurements corresponding to acquisitions of about 1 and 2 minutes in length. The results also highlight the competitive performance of the method compared to several popular alternatives, including the TGV regularization and traditional UNet3D.
Plug-and-Play Methods for Integrating Physical and Learned Models in Computational Imaging
Mar 31, 2022


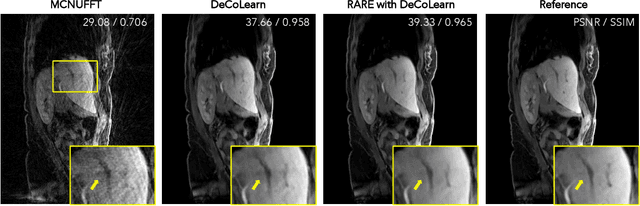
Plug-and-Play Priors (PnP) is one of the most widely-used frameworks for solving computational imaging problems through the integration of physical models and learned models. PnP leverages high-fidelity physical sensor models and powerful machine learning methods for prior modeling of data to provide state-of-the-art reconstruction algorithms. PnP algorithms alternate between minimizing a data-fidelity term to promote data consistency and imposing a learned regularizer in the form of an image denoiser. Recent highly-successful applications of PnP algorithms include bio-microscopy, computerized tomography, magnetic resonance imaging, and joint ptycho-tomography. This article presents a unified and principled review of PnP by tracing its roots, describing its major variations, summarizing main results, and discussing applications in computational imaging. We also point the way towards further developments by discussing recent results on equilibrium equations that formulate the problem associated with PnP algorithms.
Learning Cross-Video Neural Representations for High-Quality Frame Interpolation
Feb 28, 2022
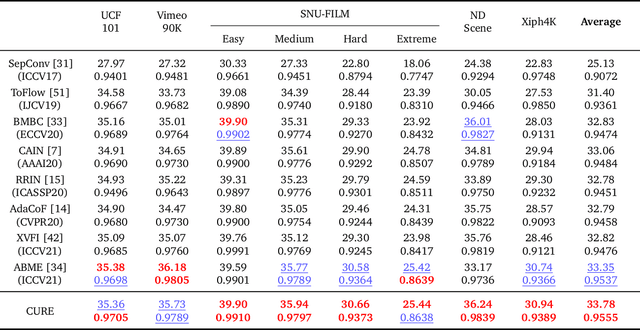
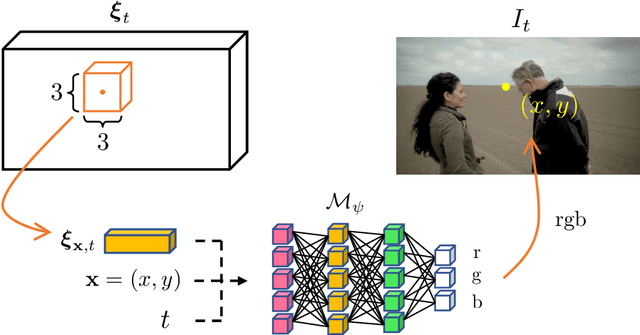
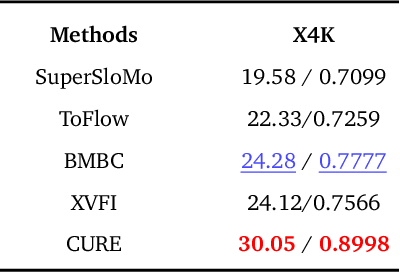
This paper considers the problem of temporal video interpolation, where the goal is to synthesize a new video frame given its two neighbors. We propose Cross-Video Neural Representation (CURE) as the first video interpolation method based on neural fields (NF). NF refers to the recent class of methods for the neural representation of complex 3D scenes that has seen widespread success and application across computer vision. CURE represents the video as a continuous function parameterized by a coordinate-based neural network, whose inputs are the spatiotemporal coordinates and outputs are the corresponding RGB values. CURE introduces a new architecture that conditions the neural network on the input frames for imposing space-time consistency in the synthesized video. This not only improves the final interpolation quality, but also enables CURE to learn a prior across multiple videos. Experimental evaluations show that CURE achieves the state-of-the-art performance on video interpolation on several benchmark datasets.