 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTyng-Luh Liu
C2S2: Cost-aware Channel Sparse Selection for Progressive Network Pruning
Apr 06, 2019
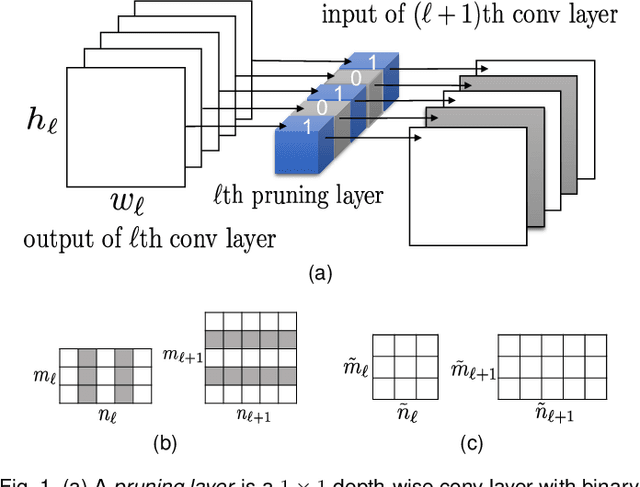
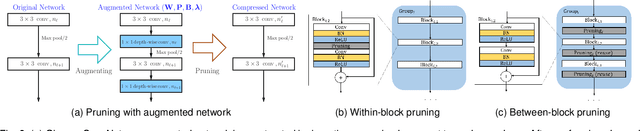
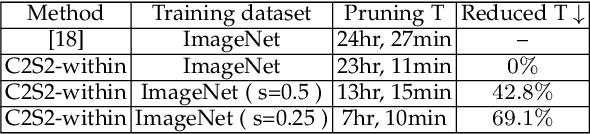
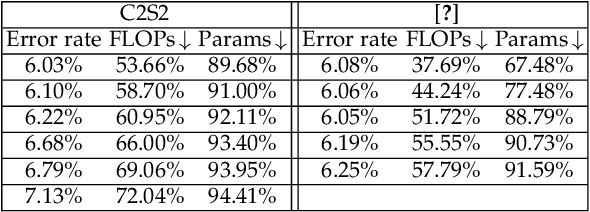
This paper describes a channel-selection approach for simplifying deep neural networks. Specifically, we propose a new type of generic network layer, called pruning layer, to seamlessly augment a given pre-trained model for compression. Each pruning layer, comprising $1 \times 1$ depth-wise kernels, is represented with a dual format: one is real-valued and the other is binary. The former enables a two-phase optimization process of network pruning to operate with an end-to-end differentiable network, and the latter yields the mask information for channel selection. Our method progressively performs the pruning task layer-wise, and achieves channel selection according to a sparsity criterion to favor pruning more channels. We also develop a cost-aware mechanism to prevent the compression from sacrificing the expected network performance. Our results for compressing several benchmark deep networks on image classification and semantic segmentation are comparable to those by state-of-the-art.
Unsupervised Meta-learning of Figure-Ground Segmentation via Imitating Visual Effects
Dec 20, 2018

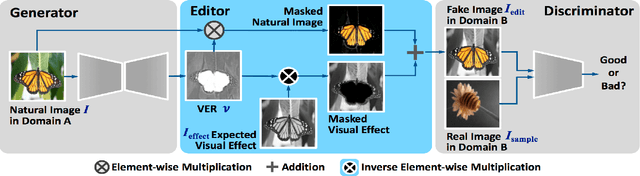
This paper presents a "learning to learn" approach to figure-ground image segmentation. By exploring webly-abundant images of specific visual effects, our method can effectively learn the visual-effect internal representations in an unsupervised manner and uses this knowledge to differentiate the figure from the ground in an image. Specifically, we formulate the meta-learning process as a compositional image editing task that learns to imitate a certain visual effect and derive the corresponding internal representation. Such a generative process can help instantiate the underlying figure-ground notion and enables the system to accomplish the intended image segmentation. Whereas existing generative methods are mostly tailored to image synthesis or style transfer, our approach offers a flexible learning mechanism to model a general concept of figure-ground segmentation from unorganized images that have no explicit pixel-level annotations. We validate our approach via extensive experiments on six datasets to demonstrate that the proposed model can be end-to-end trained without ground-truth pixel labeling yet outperforms the existing methods of unsupervised segmentation tasks.
Non-local RoI for Cross-Object Perception
Nov 25, 2018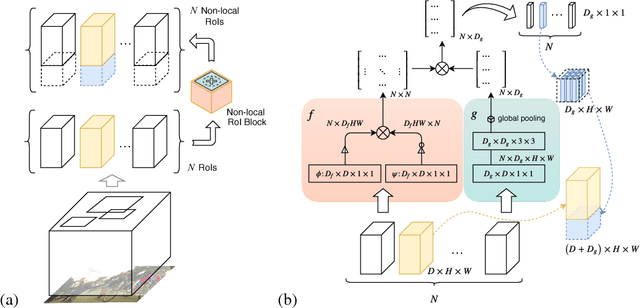
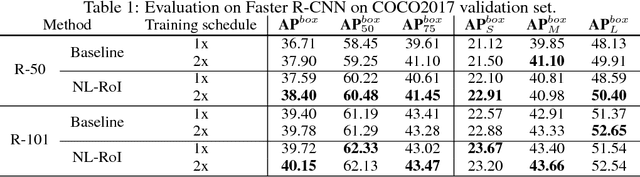
We present a generic and flexible module that encodes region proposals by both their intrinsic features and the extrinsic correlations to the others. The proposed non-local region of interest (NL-RoI) can be seamlessly adapted into different generalized R-CNN architectures to better address various perception tasks. Observe that existing techniques from R-CNN treat RoIs independently and perform the prediction solely based on image features within each region proposal. However, the pairwise relationships between proposals could further provide useful information for detection and segmentation. NL-RoI is thus formulated to enrich each RoI representation with the information from all other RoIs, and yield a simple, low-cost, yet effective module for region-based convolutional networks. Our experimental results show that NL-RoI can improve the performance of Faster/Mask R-CNN for object detection and instance segmentation.
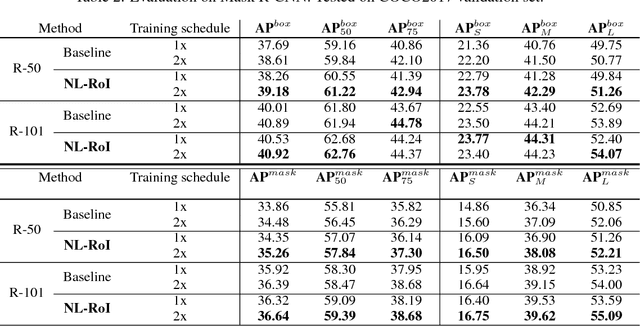
Non-local RoIs for Instance Segmentation
Jul 14, 2018
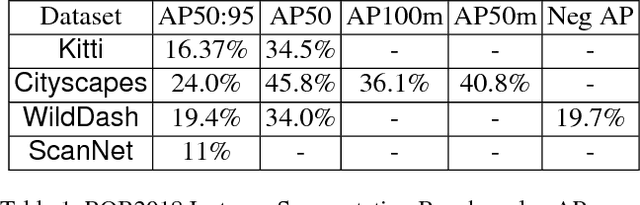
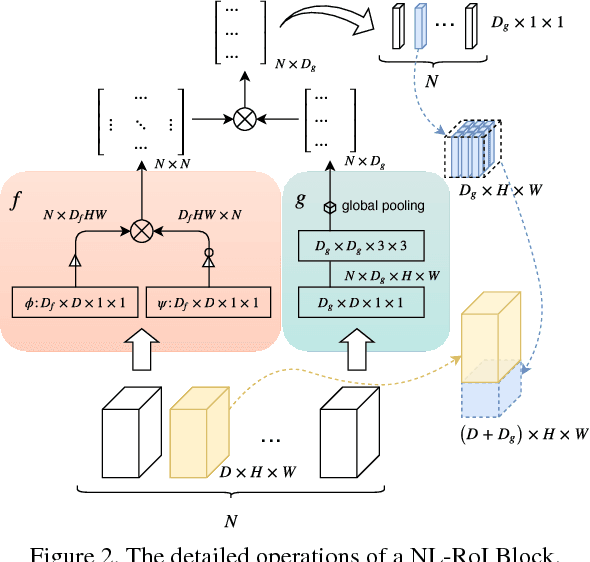

We introduce the concept of Non-Local RoI (NL-RoI) Block as a generic and flexible module that can be seamlessly adapted into different Mask R-CNN heads for various tasks. Mask R-CNN treats RoIs (Regions of Interest) independently and performs the prediction based on individual object bounding boxes. However, the correlation between objects may provide useful information for detection and segmentation. The proposed NL-RoI Block enables each RoI to refer to all other RoIs' information, and results in a simple, low-cost but effective module. Our experimental results show that generalizations with NL-RoI Blocks can improve the performance of Mask R-CNN for instance segmentation on the Robust Vision Challenge benchmarks.
Cube Padding for Weakly-Supervised Saliency Prediction in 360° Videos
Jun 04, 2018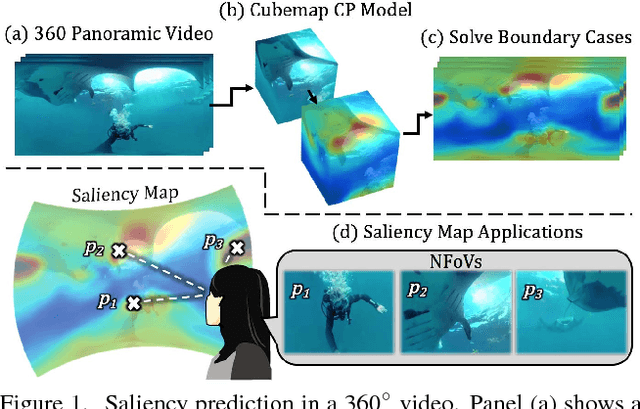
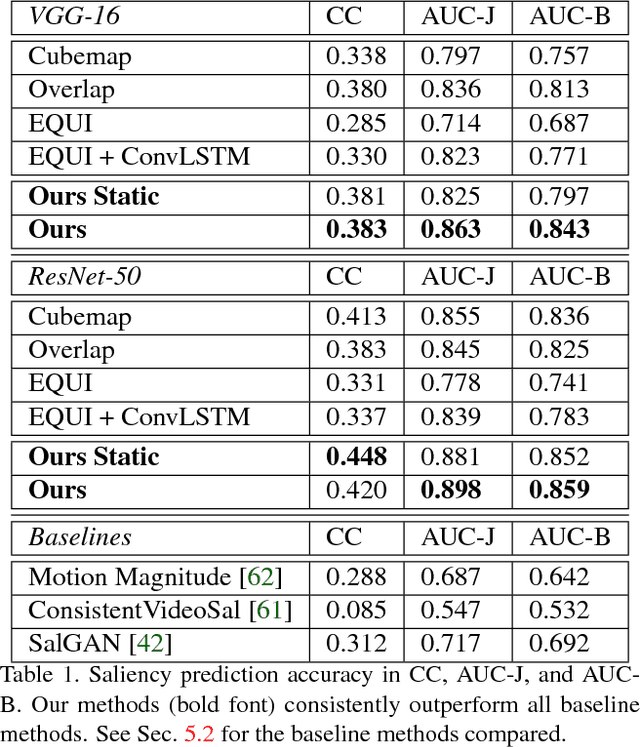
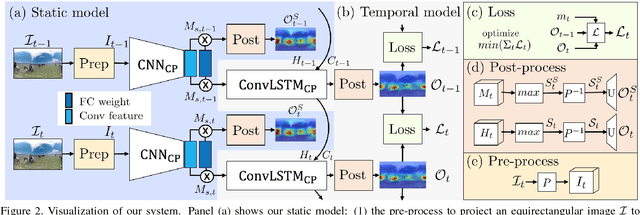
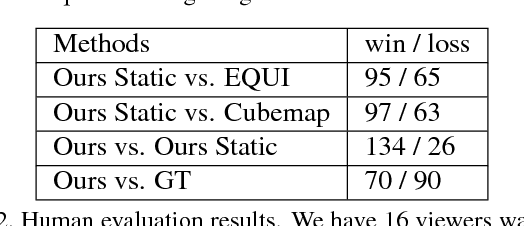
Automatic saliency prediction in 360{\deg} videos is critical for viewpoint guidance applications (e.g., Facebook 360 Guide). We propose a spatial-temporal network which is (1) weakly-supervised trained and (2) tailor-made for 360{\deg} viewing sphere. Note that most existing methods are less scalable since they rely on annotated saliency map for training. Most importantly, they convert 360{\deg} sphere to 2D images (e.g., a single equirectangular image or multiple separate Normal Field-of-View (NFoV) images) which introduces distortion and image boundaries. In contrast, we propose a simple and effective Cube Padding (CP) technique as follows. Firstly, we render the 360{\deg} view on six faces of a cube using perspective projection. Thus, it introduces very little distortion. Then, we concatenate all six faces while utilizing the connectivity between faces on the cube for image padding (i.e., Cube Padding) in convolution, pooling, convolutional LSTM layers. In this way, CP introduces no image boundary while being applicable to almost all Convolutional Neural Network (CNN) structures. To evaluate our method, we propose Wild-360, a new 360{\deg} video saliency dataset, containing challenging videos with saliency heatmap annotations. In experiments, our method outperforms baseline methods in both speed and quality.
Guided Co-training for Large-Scale Multi-View Spectral Clustering
Jul 18, 2017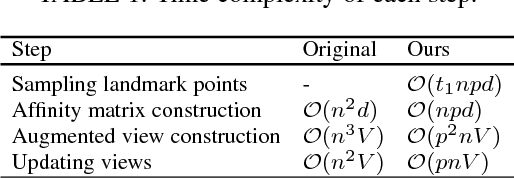
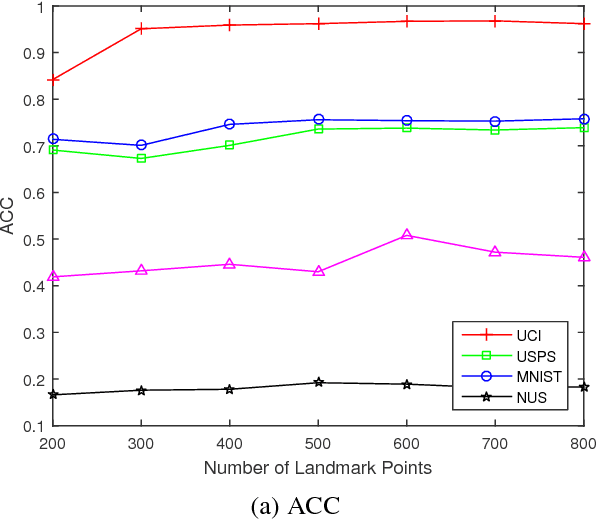

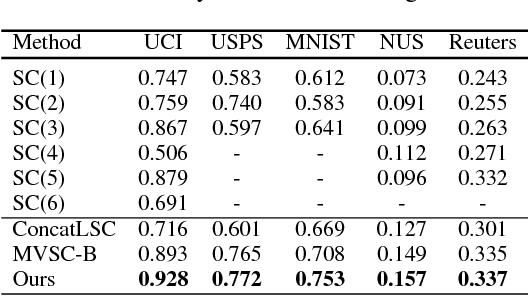
In many real-world applications, we have access to multiple views of the data, each of which characterizes the data from a distinct aspect. Several previous algorithms have demonstrated that one can achieve better clustering accuracy by integrating information from all views appropriately than using only an individual view. Owing to the effectiveness of spectral clustering, many multi-view clustering methods are based on it. Unfortunately, they have limited applicability to large-scale data due to the high computational complexity of spectral clustering. In this work, we propose a novel multi-view spectral clustering method for large-scale data. Our approach is structured under the guided co-training scheme to fuse distinct views, and uses the sampling technique to accelerate spectral clustering. More specifically, we first select $p$ ($\ll n$) landmark points and then approximate the eigen-decomposition accordingly. The augmented view, which is essential to guided co-training process, can then be quickly determined by our method. The proposed algorithm scales linearly with the number of given data. Extensive experiments have been performed and the results support the advantage of our method for handling the large-scale multi-view situation.
Implicit Sparse Code Hashing
Dec 01, 2015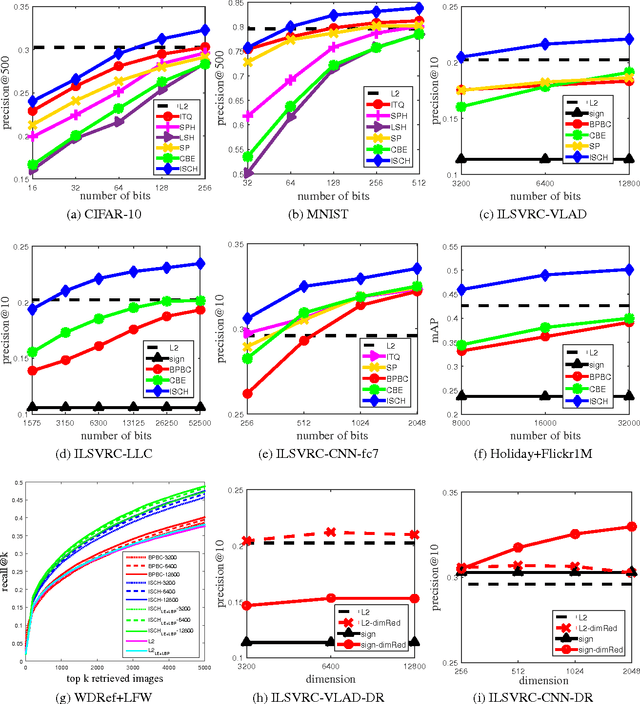
We address the problem of converting large-scale high-dimensional image data into binary codes so that approximate nearest-neighbor search over them can be efficiently performed. Different from most of the existing unsupervised approaches for yielding binary codes, our method is based on a dimensionality-reduction criterion that its resulting mapping is designed to preserve the image relationships entailed by the inner products of sparse codes, rather than those implied by the Euclidean distances in the ambient space. While the proposed formulation does not require computing any sparse codes, the underlying computation model still inevitably involves solving an unmanageable eigenproblem when extremely high-dimensional descriptors are used. To overcome the difficulty, we consider the column-sampling technique and presume a special form of rotation matrix to facilitate subproblem decomposition. We test our method on several challenging image datasets and demonstrate its effectiveness by comparing with state-of-the-art binary coding techniques.
Contour Detection Using Cost-Sensitive Convolutional Neural Networks
May 12, 2015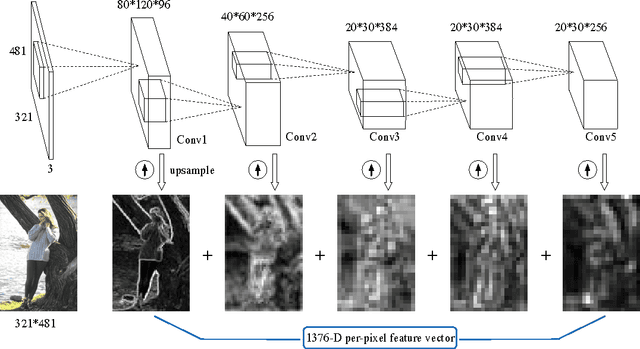
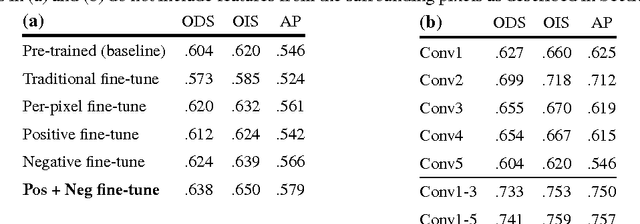
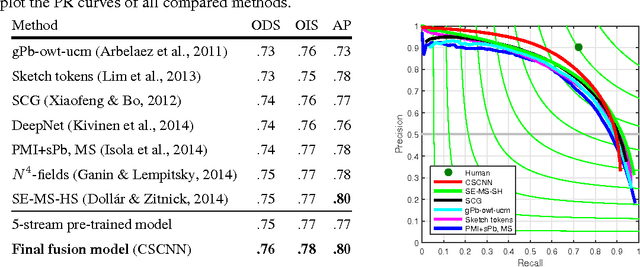
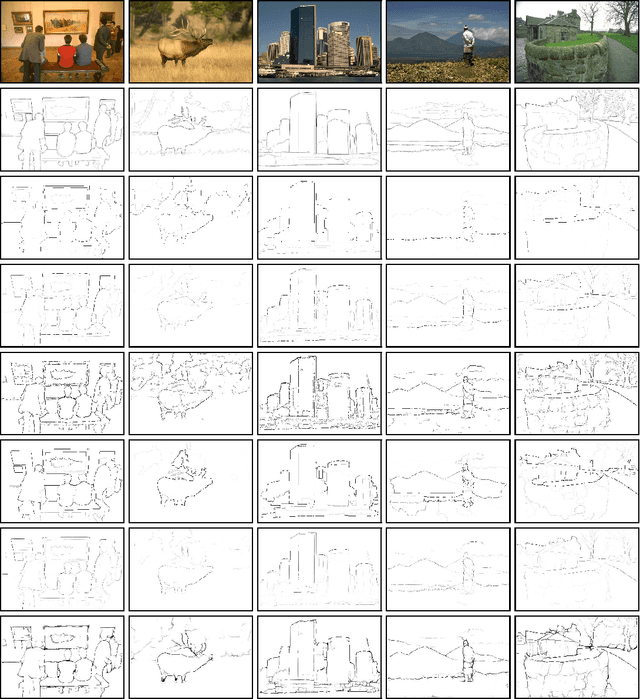
We address the problem of contour detection via per-pixel classifications of edge point. To facilitate the process, the proposed approach leverages with DenseNet, an efficient implementation of multiscale convolutional neural networks (CNNs), to extract an informative feature vector for each pixel and uses an SVM classifier to accomplish contour detection. The main challenge lies in adapting a pre-trained per-image CNN model for yielding per-pixel image features. We propose to base on the DenseNet architecture to achieve pixelwise fine-tuning and then consider a cost-sensitive strategy to further improve the learning with a small dataset of edge and non-edge image patches. In the experiment of contour detection, we look into the effectiveness of combining per-pixel features from different CNN layers and obtain comparable performances to the state-of-the-art on BSDS500.
Pixel-wise Deep Learning for Contour Detection
Apr 08, 2015
We address the problem of contour detection via per-pixel classifications of edge point. To facilitate the process, the proposed approach leverages with DenseNet, an efficient implementation of multiscale convolutional neural networks (CNNs), to extract an informative feature vector for each pixel and uses an SVM classifier to accomplish contour detection. In the experiment of contour detection, we look into the effectiveness of combining per-pixel features from different CNN layers and verify their performance on BSDS500.