 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC2S2: Cost-aware Channel Sparse Selection for Progressive Network Pruning
Paper and Code
Apr 06, 2019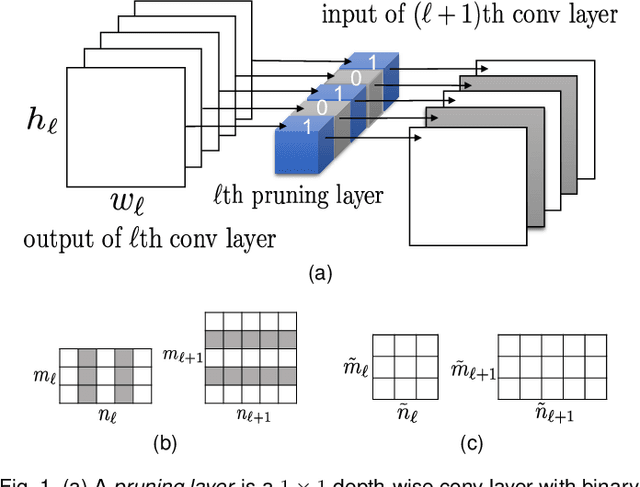
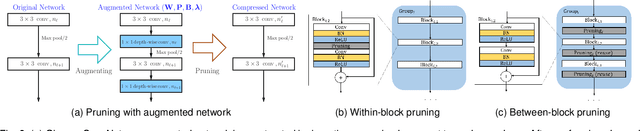
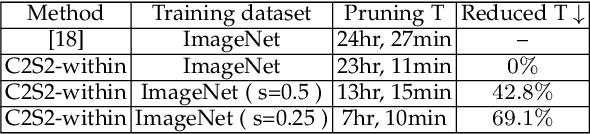
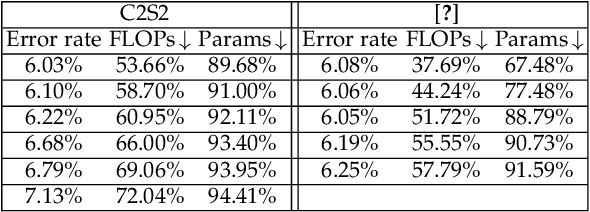
This paper describes a channel-selection approach for simplifying deep neural networks. Specifically, we propose a new type of generic network layer, called pruning layer, to seamlessly augment a given pre-trained model for compression. Each pruning layer, comprising $1 \times 1$ depth-wise kernels, is represented with a dual format: one is real-valued and the other is binary. The former enables a two-phase optimization process of network pruning to operate with an end-to-end differentiable network, and the latter yields the mask information for channel selection. Our method progressively performs the pruning task layer-wise, and achieves channel selection according to a sparsity criterion to favor pruning more channels. We also develop a cost-aware mechanism to prevent the compression from sacrificing the expected network performance. Our results for compressing several benchmark deep networks on image classification and semantic segmentation are comparable to those by state-of-the-art.