 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoral Preferences of LLMs Under Directed Contextual Influence
Feb 26, 2026Moral benchmarks for LLMs typically use context-free prompts, implicitly assuming stable preferences. In deployment, however, prompts routinely include contextual signals such as user requests, cues on social norms, etc. that may steer decisions. We study how directed contextual influences reshape decisions in trolley-problem-style moral triage settings. We introduce a pilot evaluation harness for directed contextual influence in trolley-problem-style moral triage: for each demographic factor, we apply matched, direction-flipped contextual influences that differ only in which group they favor, enabling systematic measurement of directional response. We find that: (i) contextual influences often significantly shift decisions, even when only superficially relevant; (ii) baseline preferences are a poor predictor of directional steerability, as models can appear baseline-neutral yet exhibit systematic steerability asymmetry under influence; (iii) influences can backfire: models may explicitly claim neutrality or discount the contextual cue, yet their choices still shift, sometimes in the opposite direction; and (iv) reasoning reduces average sensitivity, but amplifies the effect of biased few-shot examples. Our findings motivate extending moral evaluations with controlled, direction-flipped context manipulations to better characterize model behavior.
Effort and Size Estimation in Software Projects with Large Language Model-based Intelligent Interfaces
Feb 11, 2024The advancement of Large Language Models (LLM) has also resulted in an equivalent proliferation in its applications. Software design, being one, has gained tremendous benefits in using LLMs as an interface component that extends fixed user stories. However, inclusion of LLM-based AI agents in software design often poses unexpected challenges, especially in the estimation of development efforts. Through the example of UI-based user stories, we provide a comparison against traditional methods and propose a new way to enhance specifications of natural language-based questions that allows for the estimation of development effort by taking into account data sources, interfaces and algorithms.
AttrLostGAN: Attribute Controlled Image Synthesis from Reconfigurable Layout and Style
Mar 25, 2021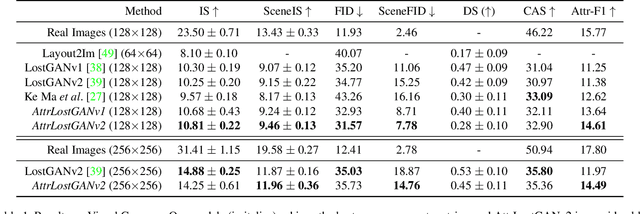
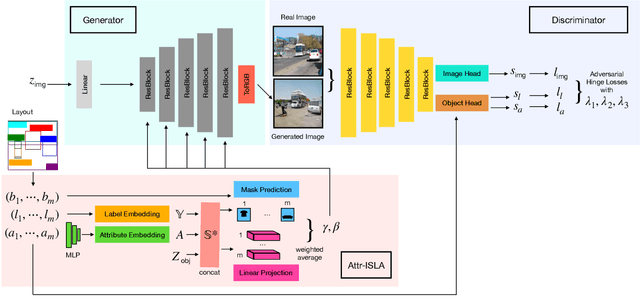
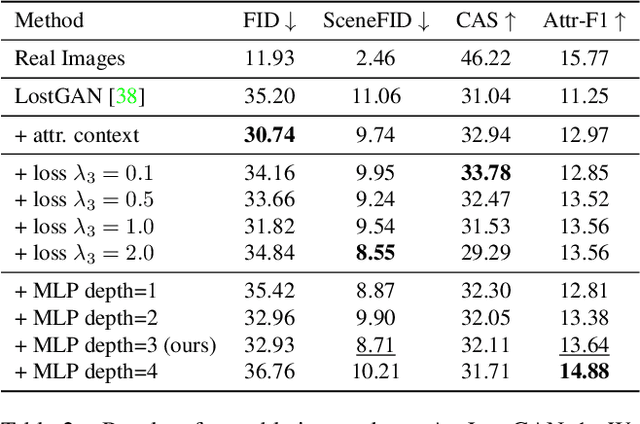
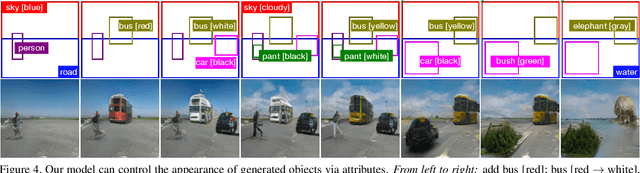
Conditional image synthesis from layout has recently attracted much interest. Previous approaches condition the generator on object locations as well as class labels but lack fine-grained control over the diverse appearance aspects of individual objects. Gaining control over the image generation process is fundamental to build practical applications with a user-friendly interface. In this paper, we propose a method for attribute controlled image synthesis from layout which allows to specify the appearance of individual objects without affecting the rest of the image. We extend a state-of-the-art approach for layout-to-image generation to additionally condition individual objects on attributes. We create and experiment on a synthetic, as well as the challenging Visual Genome dataset. Our qualitative and quantitative results show that our method can successfully control the fine-grained details of individual objects when modelling complex scenes with multiple objects.
Fusion Strategies for Learning User Embeddings with Neural Networks
Jan 08, 2019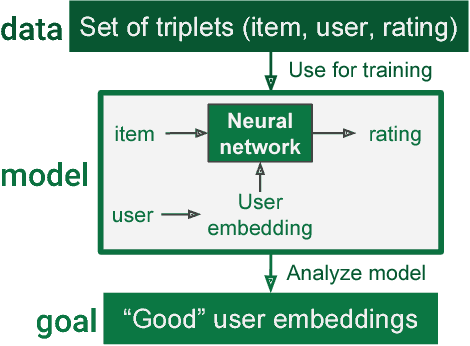
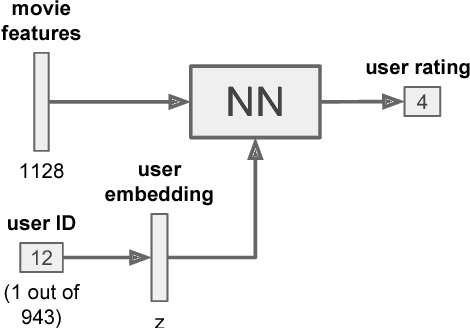
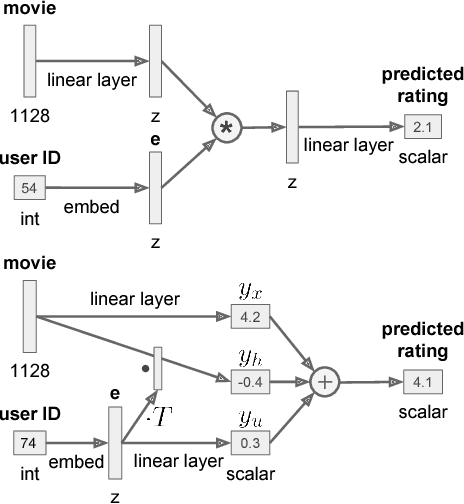
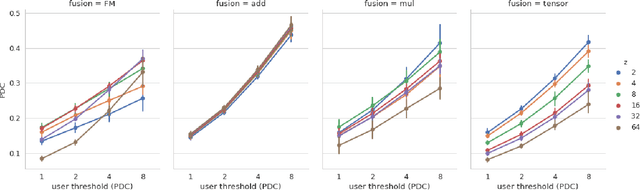
Growing amounts of online user data motivate the need for automated processing techniques. In case of user ratings, one interesting option is to use neural networks for learning to predict ratings given an item and a user. While training for prediction, such an approach at the same time learns to map each user to a vector, a so-called user embedding. Such embeddings can for example be valuable for estimating user similarity. However, there are various ways how item and user information can be combined in neural networks, and it is unclear how the way of combining affects the resulting embeddings. In this paper, we run an experiment on movie ratings data, where we analyze the effect on embedding quality caused by several fusion strategies in neural networks. For evaluating embedding quality, we propose a novel measure, Pair-Distance Correlation, which quantifies the condition that similar users should have similar embedding vectors. We find that the fusion strategy affects results in terms of both prediction performance and embedding quality. Surprisingly, we find that prediction performance not necessarily reflects embedding quality. This suggests that if embeddings are of interest, the common tendency to select models based on their prediction ability should be reconsidered.
The Focus-Aspect-Polarity Model for Predicting Subjective Noun Attributes in Images
Oct 15, 2018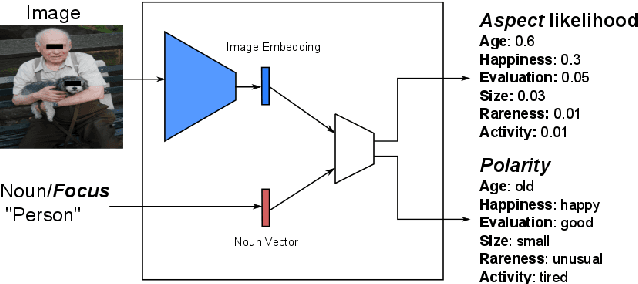

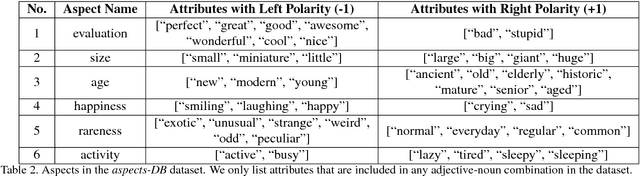
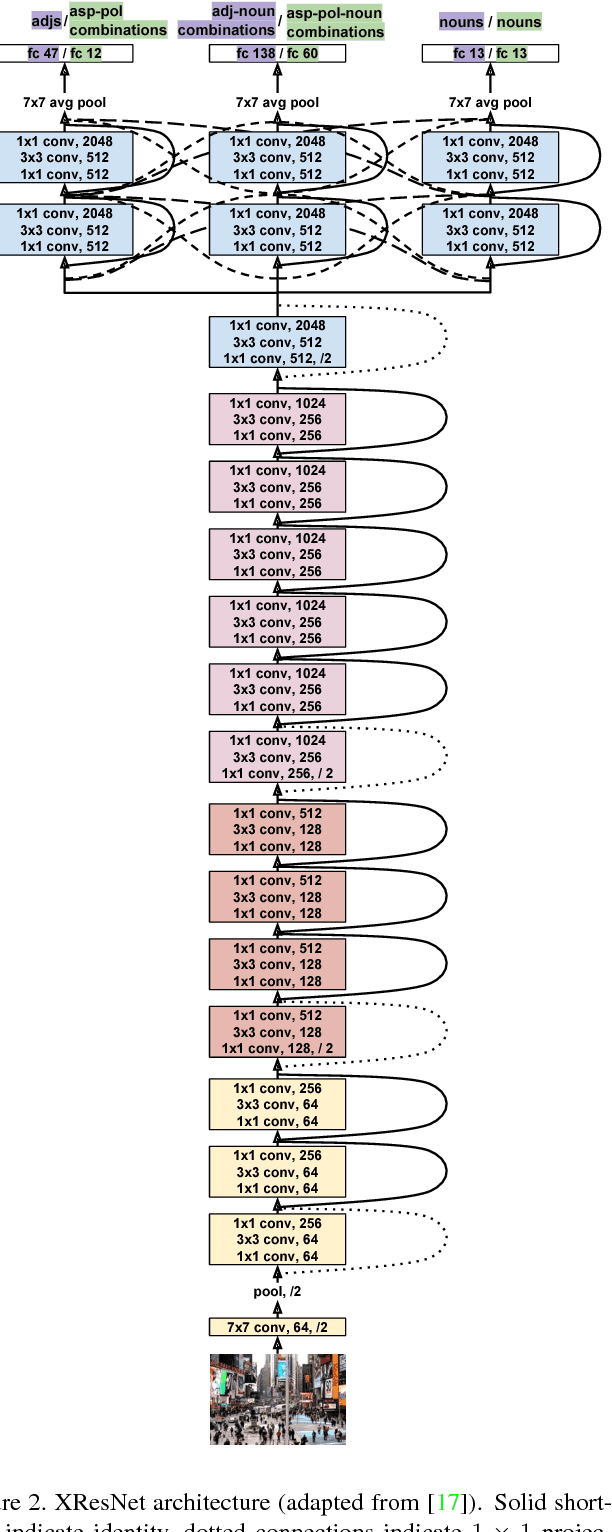
Subjective visual interpretation is a challenging yet important topic in computer vision. Many approaches reduce this problem to the prediction of adjective- or attribute-labels from images. However, most of these do not take attribute semantics into account, or only process the image in a holistic manner. Furthermore, there is a lack of relevant datasets with fine-grained subjective labels. In this paper, we propose the Focus-Aspect-Polarity model to structure the process of capturing subjectivity in image processing, and introduce a novel dataset following this way of modeling. We run experiments on this dataset to compare several deep learning methods and find that incorporating context information based on tensor multiplication in several cases outperforms the default way of information fusion (concatenation).