 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow much data is sufficient to learn high-performing algorithms?
Sep 09, 2019
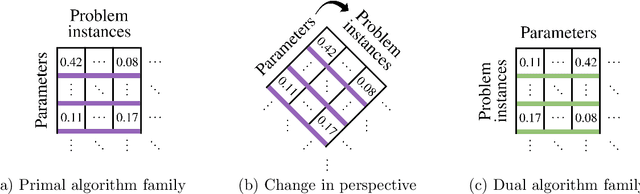
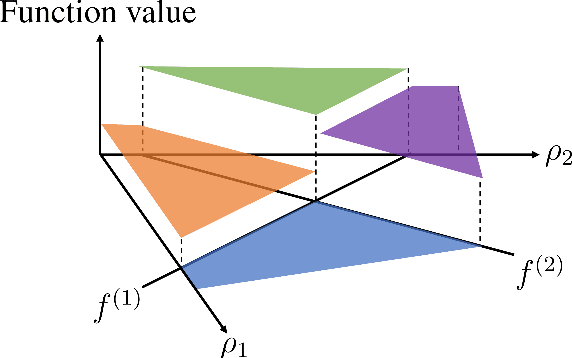
Algorithms for scientific analysis typically have tunable parameters that significantly influence computational efficiency and solution quality. If a parameter setting leads to strong algorithmic performance on average over a set of typical problem instances, that parameter setting---ideally---will perform well in the future. However, if the set of typical problem instances is small, average performance will not generalize to future performance. This raises the question: how large should this set be? We answer this question for any algorithm satisfying an easy-to-describe, ubiquitous property: its performance is a piecewise-structured function of its parameters. We are the first to provide a unified sample complexity framework for algorithm parameter configuration; prior research followed case-by-case analyses. We present applications from diverse domains, including biology, political science, and economics.
Coarse Correlation in Extensive-Form Games
Aug 26, 2019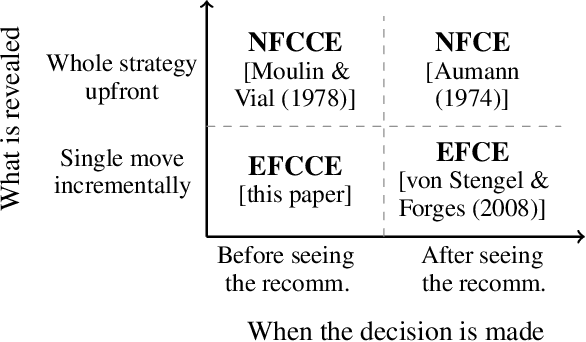

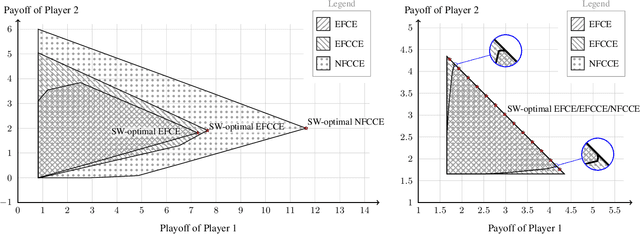
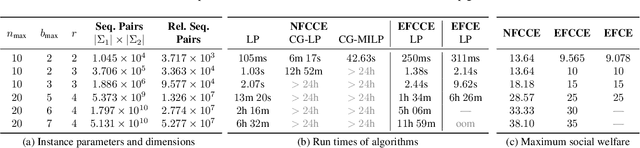
Coarse correlation models strategic interactions of rational agents complemented by a correlation device, that is a mediator that can recommend behavior but not enforce it. Despite being a classical concept in the theory of normal-form games for more than forty years, not much is known about the merits of coarse correlation in extensive-form settings. In this paper, we consider two instantiations of the idea of coarse correlation in extensive-form games: normal-form coarse-correlated equilibrium (NFCCE), already defined in the literature, and extensive-form coarse-correlated equilibrium (EFCCE), which we introduce for the first time. We show that EFCCE is a subset of NFCCE and a superset of the related extensive-form correlated equilibrium. We also show that, in two-player extensive-form games, social-welfare-maximizing EFCCEs and NFCEEs are bilinear saddle points, and give new efficient algorithms for the special case of games with no chance moves. In our experiments, our proposed algorithm for NFCCE is two to four orders of magnitude faster than the prior state of the art.
Learning to Optimize Computational Resources: Frugal Training with Generalization Guarantees
May 26, 2019
Algorithms typically come with tunable parameters that have a considerable impact on the computational resources they consume. Too often, practitioners must hand-tune the parameters, a tedious and error-prone task. A recent line of research provides algorithms that return nearly-optimal parameters from within a finite set. These algorithms can be used when the parameter space is infinite by providing as input a random sample of parameters. This data-independent discretization, however, might miss pockets of nearly-optimal parameters: prior research has presented scenarios where the only viable parameters lie within an arbitrarily small region. We provide an algorithm that learns a finite set of promising parameters from within an infinite set. Our algorithm can help compile a configuration portfolio, or it can be used to select the input to a configuration algorithm for finite parameter spaces. Our approach applies to any configuration problem that satisfies a simple yet ubiquitous structure: the algorithm's performance is a piecewise constant function of its parameters. Prior research has exhibited this structure in domains from integer programming to clustering. For these types of combinatorial problems, this is the first configuration algorithm beyond exhaustive search whose output provably competes with the best parameters from an infinite space.
Limited Lookahead in Imperfect-Information Games
Feb 17, 2019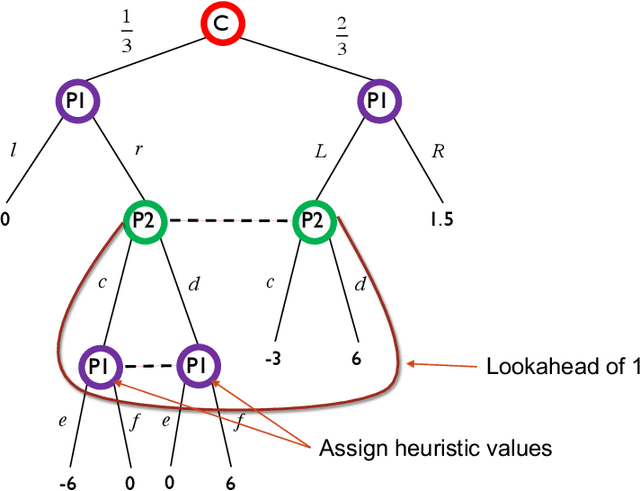
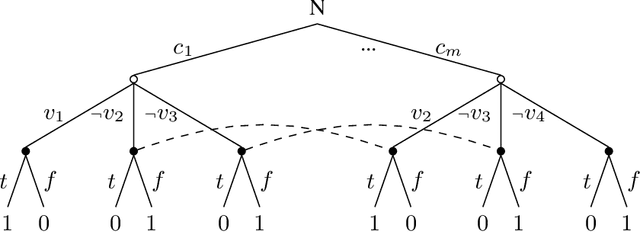
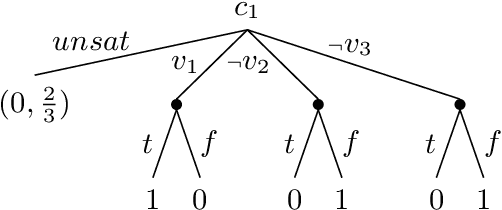
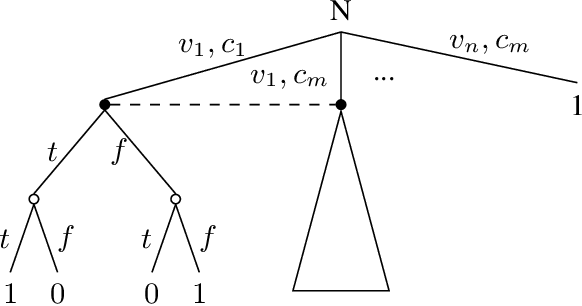
Limited lookahead has been studied for decades in complete-information games. We initiate a new direction via two simultaneous deviation points: generalization to incomplete-information games and a game-theoretic approach. We study how one should act when facing an opponent whose lookahead is limited. We study this for opponents that differ based on their lookahead depth, based on whether they, too, have incomplete information, and based on how they break ties. We characterize the hardness of finding a Nash equilibrium or an optimal commitment strategy for either player, showing that in some of these variations the problem can be solved in polynomial time while in others it is PPAD-hard or NP-hard. We proceed to design algorithms for computing optimal commitment strategies---for when the opponent breaks ties favorably, according to a fixed rule, or adversarially. We then experimentally investigate the impact of limited lookahead. The limited-lookahead player often obtains the value of the game if she knows the expected values of nodes in the game tree for some equilibrium---but we prove this is not sufficient in general. Finally, we study the impact of noise in those estimates and different lookahead depths. This uncovers an incomplete-information game lookahead pathology.
Stable-Predictive Optimistic Counterfactual Regret Minimization
Feb 13, 2019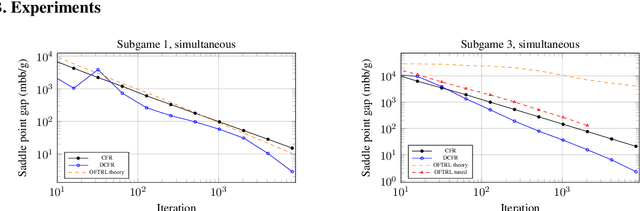
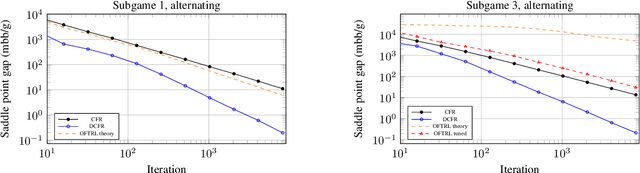
The CFR framework has been a powerful tool for solving large-scale extensive-form games in practice. However, the theoretical rate at which past CFR-based algorithms converge to the Nash equilibrium is on the order of $O(T^{-1/2})$, where $T$ is the number of iterations. In contrast, first-order methods can be used to achieve a $O(T^{-1})$ dependence on iterations, yet these methods have been less successful in practice. In this work we present the first CFR variant that breaks the square-root dependence on iterations. By combining and extending recent advances on predictive and stable regret minimizers for the matrix-game setting we show that it is possible to leverage "optimistic" regret minimizers to achieve a $O(T^{-3/4})$ convergence rate within CFR. This is achieved by introducing a new notion of stable-predictivity, and by setting the stability of each counterfactual regret minimizer relative to its location in the decision tree. Experiments show that this method is faster than the original CFR algorithm, although not as fast as newer variants, in spite of their worst-case $O(T^{-1/2})$ dependence on iterations.
Composability of Regret Minimizers
Nov 06, 2018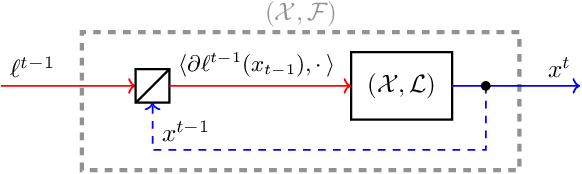
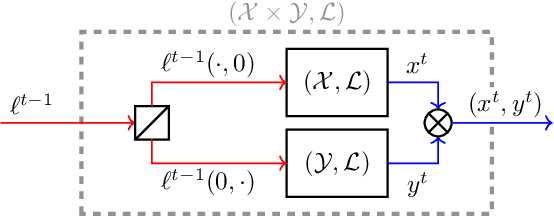
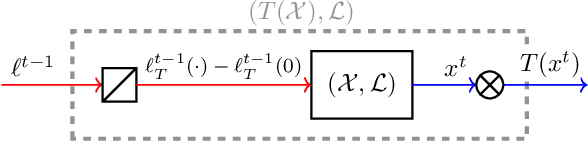
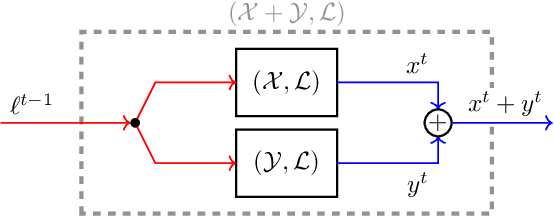
Regret minimization is a powerful tool for solving large-scale problems; it was recently used in breakthrough results for large-scale extensive-form-game solving. This was achieved by composing simplex regret minimizers into an overall regret-minimization framework for extensive-form-game strategy spaces. In this paper we study the general composability of regret minimizers. We derive a calculus for constructing regret minimizers for complex convex sets that are constructed from convexity-preserving operations on simpler convex sets. In particular, we show that local regret minimizers for the simpler sets can be composed with additional regret minimizers into an aggregate regret minimizer for the complex set. As an application of our framework we show that the CFR framework can be constructed easily from our framework. We also show how to construct a CFR variant for extensive-form games with strategy constraints. Unlike a recently proposed variant of CFR for strategy constraints by Davis, Waugh, and Bowling (2018), the algorithm resulting from our calculus does not depend on any unknown constants and thus avoids binary search.
Deep Counterfactual Regret Minimization
Nov 01, 2018



Counterfactual Regret Minimization (CFR) is the leading algorithm for solving large imperfect-information games. It iteratively traverses the game tree in order to converge to a Nash equilibrium. In order to deal with extremely large games, CFR typically uses domain-specific heuristics to simplify the target game in a process known as abstraction. This simplified game is solved with tabular CFR, and its solution is mapped back to the full game. This paper introduces Deep Counterfactual Regret Minimization (Deep CFR), a form of CFR that obviates the need for abstraction by instead using deep neural networks to approximate the behavior of CFR in the full game. We show that Deep CFR is principled and achieves strong performance in the benchmark game of heads-up no-limit Texas hold'em poker. This is the first successful use of function approximation in CFR for large games.
Solving Large Sequential Games with the Excessive Gap Technique
Oct 07, 2018
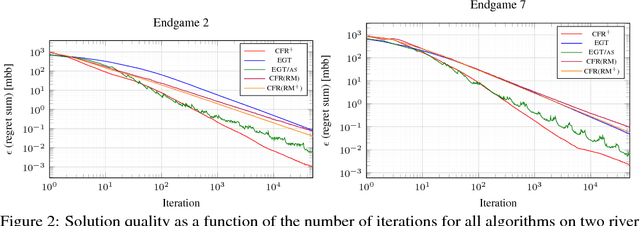
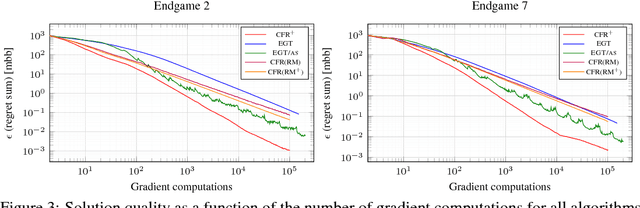
There has been tremendous recent progress on equilibrium-finding algorithms for zero-sum imperfect-information extensive-form games, but there has been a puzzling gap between theory and practice. First-order methods have significantly better theoretical convergence rates than any counterfactual-regret minimization (CFR) variant. Despite this, CFR variants have been favored in practice. Experiments with first-order methods have only been conducted on small- and medium-sized games because those methods are complicated to implement in this setting, and because CFR variants have been enhanced extensively for over a decade they perform well in practice. In this paper we show that a particular first-order method, a state-of-the-art variant of the excessive gap technique---instantiated with the dilated entropy distance function---can efficiently solve large real-world problems competitively with CFR and its variants. We show this on large endgames encountered by the Libratus poker AI, which recently beat top human poker specialist professionals at no-limit Texas hold'em. We show experimental results on our variant of the excessive gap technique as well as a prior version. We introduce a numerically friendly implementation of the smoothed best response computation associated with first-order methods for extensive-form game solving. We present, to our knowledge, the first GPU implementation of a first-order method for extensive-form games. We present comparisons of several excessive gap technique and CFR variants.
Solving Imperfect-Information Games via Discounted Regret Minimization
Sep 11, 2018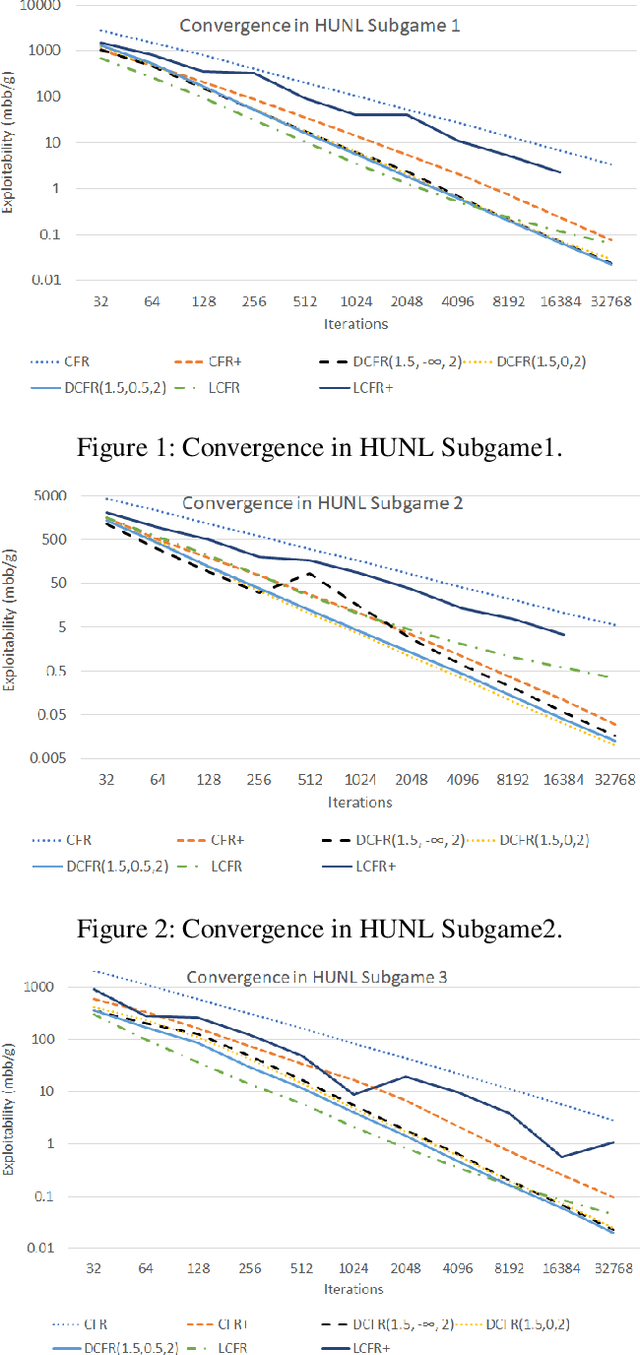
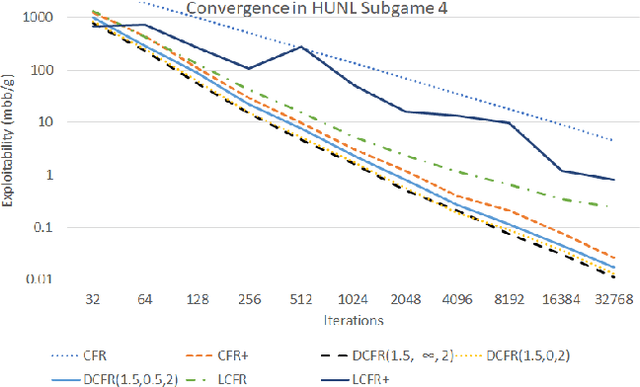
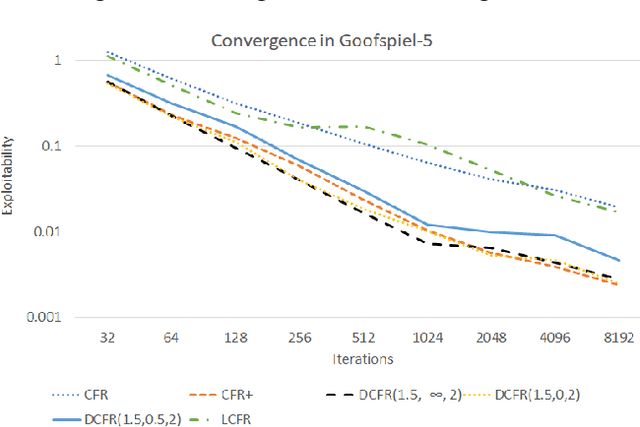
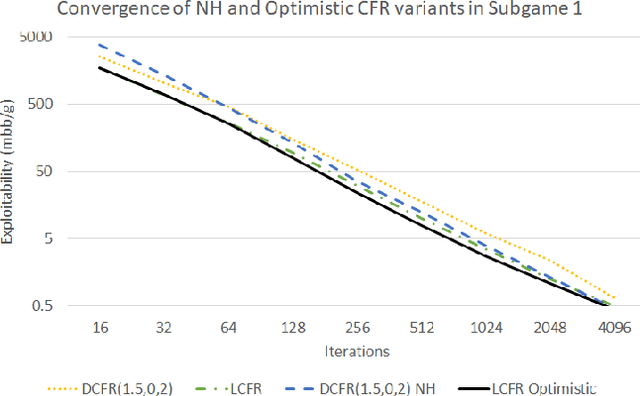
Counterfactual regret minimization (CFR) is a family of iterative algorithms that are the most popular and, in practice, fastest approach to approximately solving large imperfect-information games. In this paper we introduce novel CFR variants that 1) discount regrets from earlier iterations in various ways (in some cases differently for positive and negative regrets), 2) reweight iterations in various ways to obtain the output strategies, 3) use a non-standard regret minimizer and/or 4) leverage "optimistic regret matching". They lead to dramatically improved performance in many settings. For one, we introduce a variant that outperforms CFR+, the prior state-of-the-art algorithm, in every game tested, including large-scale realistic settings. CFR+ is a formidable benchmark: no other algorithm has been able to outperform it. Finally, we show that, unlike CFR+, many of the important new variants are compatible with modern imperfect-information-game pruning techniques and one is also compatible with sampling in the game tree.
Online Convex Optimization for Sequential Decision Processes and Extensive-Form Games
Sep 10, 2018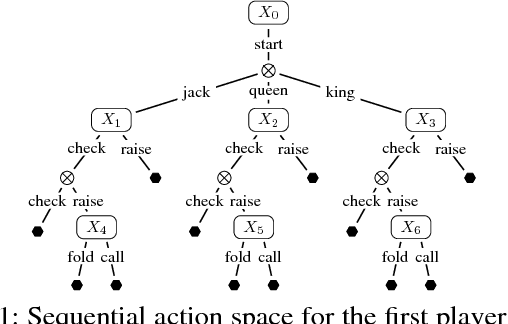
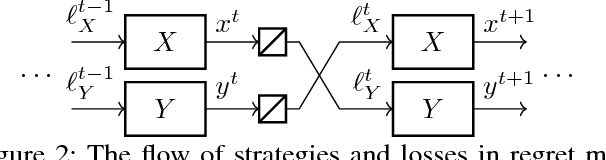
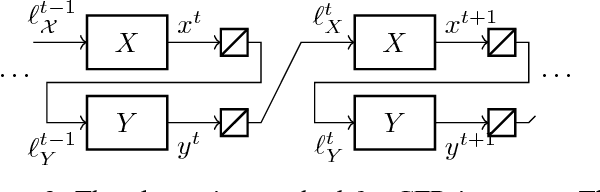
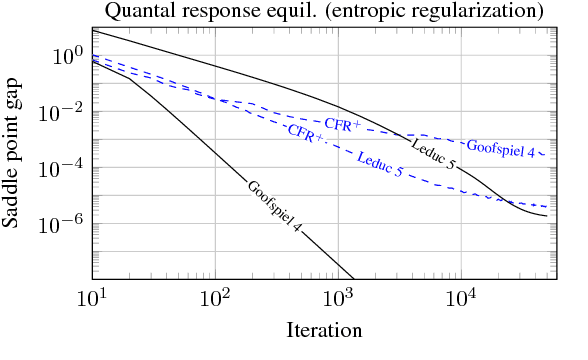
Regret minimization is a powerful tool for solving large-scale extensive-form games. State-of-the-art methods rely on minimizing regret locally at each decision point. In this work we derive a new framework for regret minimization on sequential decision problems and extensive-form games with general compact convex sets at each decision point and general convex losses, as opposed to prior work which has been for simplex decision points and linear losses. We call our framework laminar regret decomposition. It generalizes the CFR algorithm to this more general setting. Furthermore, our framework enables a new proof of CFR even in the known setting, which is derived from a perspective of decomposing polytope regret, thereby leading to an arguably simpler interpretation of the algorithm. Our generalization to convex compact sets and convex losses allows us to develop new algorithms for several problems: regularized sequential decision making, regularized Nash equilibria in extensive-form games, and computing approximate extensive-form perfect equilibria. Our generalization also leads to the first regret-minimization algorithm for computing reduced-normal-form quantal response equilibria based on minimizing local regrets. Experiments show that our framework leads to algorithms that scale at a rate comparable to the fastest variants of counterfactual regret minimization for computing Nash equilibrium, and therefore our approach leads to the first algorithm for computing quantal response equilibria in extremely large games. Finally we show that our framework enables a new kind of scalable opponent exploitation approach.