 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping a Tutoring Dialog Dataset to Optimize LLMs for Educational Use
Oct 25, 2024Recent advances in large language models (LLMs) have shown promise for scalable educational applications, but their use in dialog-based tutoring systems remains challenging due to the need for effective pedagogical strategies and the high costs associated with expert-curated datasets. Our study explores the use of smaller, more affordable LLMs for one-on-one tutoring in the context of solving reading comprehension problems. We developed a synthetic tutoring dialog dataset, evaluated by human teachers, and fine-tuned a smaller LLM using this dataset. Furthermore, we conducted an interactive experiment comparing the performance of the fine-tuned model with a larger model in real-world tutoring scenarios. Our results show that the fine-tuned model performs on par with the larger model but at a lower cost, demonstrating a viable, cost-effective approach for implementing LLM-based tutoring systems in educational settings.
Beyond Scores: A Modular RAG-Based System for Automatic Short Answer Scoring with Feedback
Sep 30, 2024



Automatic short answer scoring (ASAS) helps reduce the grading burden on educators but often lacks detailed, explainable feedback. Existing methods in ASAS with feedback (ASAS-F) rely on fine-tuning language models with limited datasets, which is resource-intensive and struggles to generalize across contexts. Recent approaches using large language models (LLMs) have focused on scoring without extensive fine-tuning. However, they often rely heavily on prompt engineering and either fail to generate elaborated feedback or do not adequately evaluate it. In this paper, we propose a modular retrieval augmented generation based ASAS-F system that scores answers and generates feedback in strict zero-shot and few-shot learning scenarios. We design our system to be adaptable to various educational tasks without extensive prompt engineering using an automatic prompt generation framework. Results show an improvement in scoring accuracy by 9\% on unseen questions compared to fine-tuning, offering a scalable and cost-effective solution.
One Stone, Four Birds: A Comprehensive Solution for QA System Using Supervised Contrastive Learning
Jul 12, 2024



This paper presents a novel and comprehensive solution to enhance both the robustness and efficiency of question answering (QA) systems through supervised contrastive learning (SCL). Training a high-performance QA system has become straightforward with pre-trained language models, requiring only a small amount of data and simple fine-tuning. However, despite recent advances, existing QA systems still exhibit significant deficiencies in functionality and training efficiency. We address the functionality issue by defining four key tasks: user input intent classification, out-of-domain input detection, new intent discovery, and continual learning. We then leverage a unified SCL-based representation learning method to efficiently build an intra-class compact and inter-class scattered feature space, facilitating both known intent classification and unknown intent detection and discovery. Consequently, with minimal additional tuning on downstream tasks, our approach significantly improves model efficiency and achieves new state-of-the-art performance across all tasks.
Balancing Embedding Spectrum for Recommendation
Jun 17, 2024



Modern recommender systems heavily rely on high-quality representations learned from high-dimensional sparse data. While significant efforts have been invested in designing powerful algorithms for extracting user preferences, the factors contributing to good representations have remained relatively unexplored. In this work, we shed light on an issue in the existing pair-wise learning paradigm (i.e., the embedding collapse problem), that the representations tend to span a subspace of the whole embedding space, leading to a suboptimal solution and reducing the model capacity. Specifically, optimization on observed interactions is equivalent to a low pass filter causing users/items to have the same representations and resulting in a complete collapse. While negative sampling acts as a high pass filter to alleviate the collapse by balancing the embedding spectrum, its effectiveness is only limited to certain losses, which still leads to an incomplete collapse. To tackle this issue, we propose a novel method called DirectSpec, acting as a reliable all pass filter to balance the spectrum distribution of the embeddings during training, ensuring that users/items effectively span the entire embedding space. Additionally, we provide a thorough analysis of DirectSpec from a decorrelation perspective and propose an enhanced variant, DirectSpec+, which employs self-paced gradients to optimize irrelevant samples more effectively. Moreover, we establish a close connection between DirectSpec+ and uniformity, demonstrating that contrastive learning (CL) can alleviate the collapse issue by indirectly balancing the spectrum. Finally, we implement DirectSpec and DirectSpec+ on two popular recommender models: MF and LightGCN. Our experimental results demonstrate its effectiveness and efficiency over competitive baselines.
How Powerful is Graph Filtering for Recommendation
Jun 13, 2024



It has been shown that the effectiveness of graph convolutional network (GCN) for recommendation is attributed to the spectral graph filtering. Most GCN-based methods consist of a graph filter or followed by a low-rank mapping optimized based on supervised training. However, we show two limitations suppressing the power of graph filtering: (1) Lack of generality. Due to the varied noise distribution, graph filters fail to denoise sparse data where noise is scattered across all frequencies, while supervised training results in worse performance on dense data where noise is concentrated in middle frequencies that can be removed by graph filters without training. (2) Lack of expressive power. We theoretically show that linear GCN (LGCN) that is effective on collaborative filtering (CF) cannot generate arbitrary embeddings, implying the possibility that optimal data representation might be unreachable. To tackle the first limitation, we show close relation between noise distribution and the sharpness of spectrum where a sharper spectral distribution is more desirable causing data noise to be separable from important features without training. Based on this observation, we propose a generalized graph normalization G^2N to adjust the sharpness of spectral distribution in order to redistribute data noise to assure that it can be removed by graph filtering without training. As for the second limitation, we propose an individualized graph filter (IGF) adapting to the different confidence levels of the user preference that interactions can reflect, which is proved to be able to generate arbitrary embeddings. By simplifying LGCN, we further propose a simplified graph filtering (SGFCF) which only requires the top-K singular values for recommendation. Finally, experimental results on four datasets with different density settings demonstrate the effectiveness and efficiency of our proposed methods.
Privacy-Preserving Sequential Recommendation with Collaborative Confusion
Jan 09, 2024Sequential recommendation has attracted a lot of attention from both academia and industry, however the privacy risks associated to gathering and transferring users' personal interaction data are often underestimated or ignored. Existing privacy-preserving studies are mainly applied to traditional collaborative filtering or matrix factorization rather than sequential recommendation. Moreover, these studies are mostly based on differential privacy or federated learning, which often leads to significant performance degradation, or has high requirements for communication. In this work, we address privacy-preserving from a different perspective. Unlike existing research, we capture collaborative signals of neighbor interaction sequences and directly inject indistinguishable items into the target sequence before the recommendation process begins, thereby increasing the perplexity of the target sequence. Even if the target interaction sequence is obtained by attackers, it is difficult to discern which ones are the actual user interaction records. To achieve this goal, we propose a CoLlaborative-cOnfusion seqUential recommenDer, namely CLOUD, which incorporates a collaborative confusion mechanism to edit the raw interaction sequences before conducting recommendation. Specifically, CLOUD first calculates the similarity between the target interaction sequence and other neighbor sequences to find similar sequences. Then, CLOUD considers the shared representation of the target sequence and similar sequences to determine the operation to be performed: keep, delete, or insert. We design a copy mechanism to make items from similar sequences have a higher probability to be inserted into the target sequence. Finally, the modified sequence is used to train the recommender and predict the next item.
SVD-GCN: A Simplified Graph Convolution Paradigm for Recommendation
Aug 26, 2022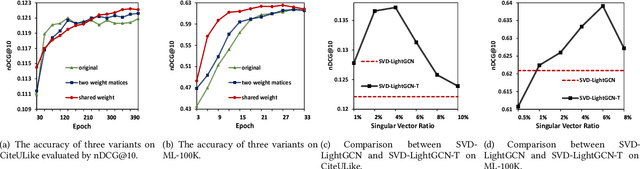
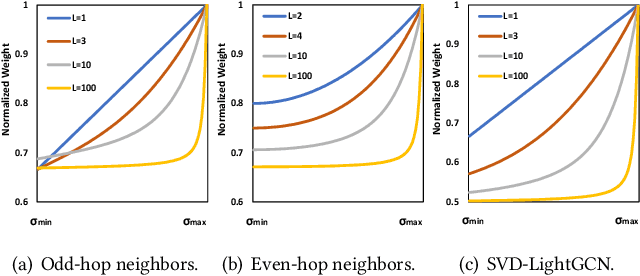
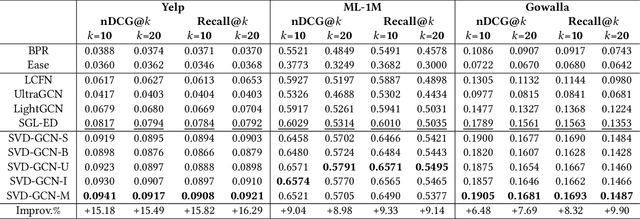
With the tremendous success of Graph Convolutional Networks (GCNs), they have been widely applied to recommender systems and have shown promising performance. However, most GCN-based methods rigorously stick to a common GCN learning paradigm and suffer from two limitations: (1) the limited scalability due to the high computational cost and slow training convergence; (2) the notorious over-smoothing issue which reduces performance as stacking graph convolution layers. We argue that the above limitations are due to the lack of a deep understanding of GCN-based methods. To this end, we first investigate what design makes GCN effective for recommendation. By simplifying LightGCN, we show the close connection between GCN-based and low-rank methods such as Singular Value Decomposition (SVD) and Matrix Factorization (MF), where stacking graph convolution layers is to learn a low-rank representation by emphasizing (suppressing) components with larger (smaller) singular values. Based on this observation, we replace the core design of GCN-based methods with a flexible truncated SVD and propose a simplified GCN learning paradigm dubbed SVD-GCN, which only exploits $K$-largest singular vectors for recommendation. To alleviate the over-smoothing issue, we propose a renormalization trick to adjust the singular value gap, resulting in significant improvement. Extensive experiments on three real-world datasets show that our proposed SVD-GCN not only significantly outperforms state-of-the-arts but also achieves over 100x and 10x speedups over LightGCN and MF, respectively.
Less is More: Reweighting Important Spectral Graph Features for Recommendation
Apr 24, 2022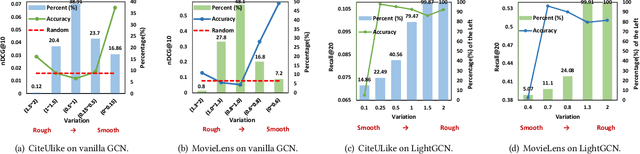
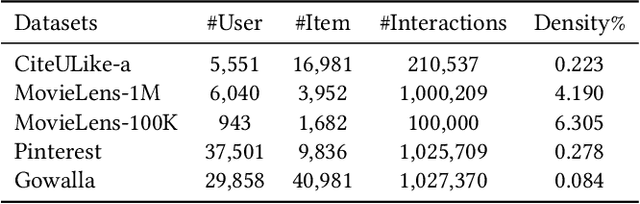
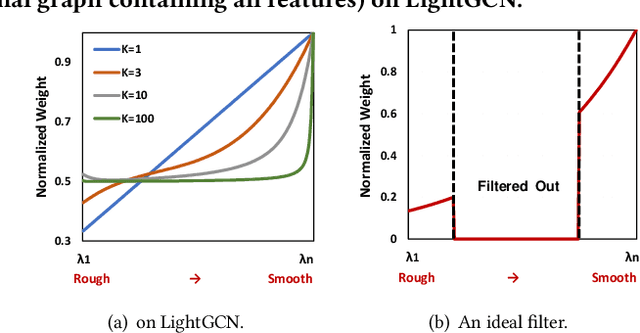
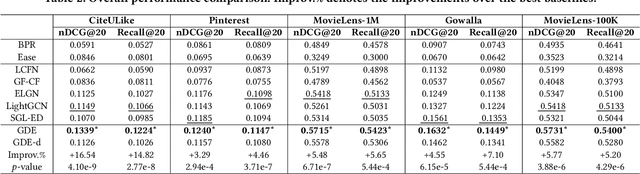
As much as Graph Convolutional Networks (GCNs) have shown tremendous success in recommender systems and collaborative filtering (CF), the mechanism of how they, especially the core components (\textit{i.e.,} neighborhood aggregation) contribute to recommendation has not been well studied. To unveil the effectiveness of GCNs for recommendation, we first analyze them in a spectral perspective and discover two important findings: (1) only a small portion of spectral graph features that emphasize the neighborhood smoothness and difference contribute to the recommendation accuracy, whereas most graph information can be considered as noise that even reduces the performance, and (2) repetition of the neighborhood aggregation emphasizes smoothed features and filters out noise information in an ineffective way. Based on the two findings above, we propose a new GCN learning scheme for recommendation by replacing neihgborhood aggregation with a simple yet effective Graph Denoising Encoder (GDE), which acts as a band pass filter to capture important graph features. We show that our proposed method alleviates the over-smoothing and is comparable to an indefinite-layer GCN that can take any-hop neighborhood into consideration. Finally, we dynamically adjust the gradients over the negative samples to expedite model training without introducing additional complexity. Extensive experiments on five real-world datasets show that our proposed method not only outperforms state-of-the-arts but also achieves 12x speedup over LightGCN.
A Robust Hierarchical Graph Convolutional Network Model for Collaborative Filtering
Apr 30, 2020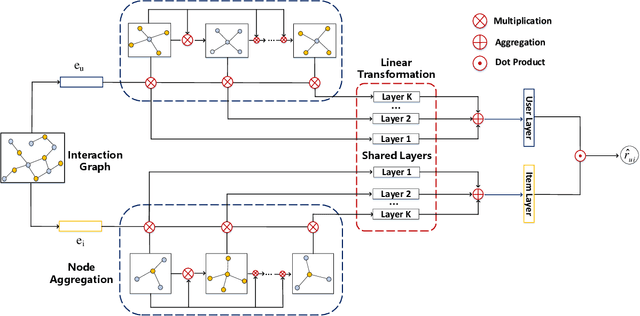
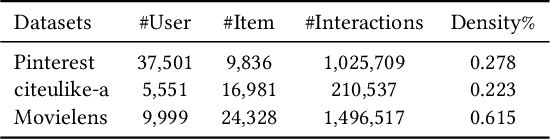
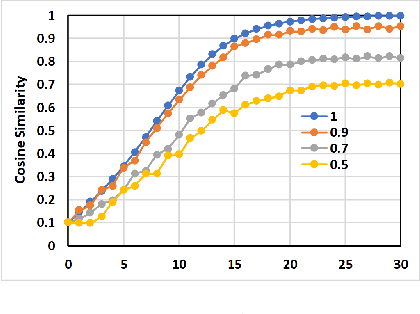
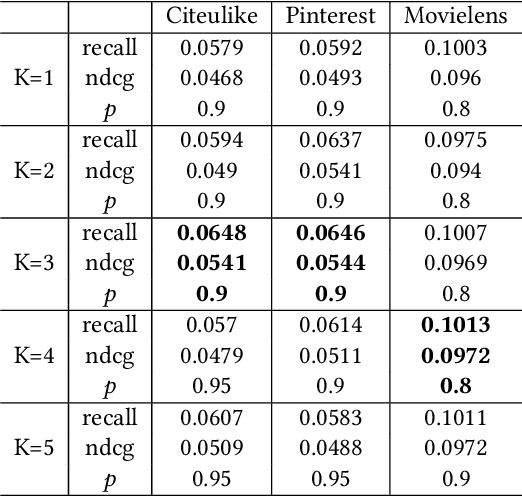
Graph Convolutional Network (GCN) has achieved great success and has been applied in various fields including recommender systems. However, GCN still suffers from many issues such as training difficulties, over-smoothing, vulnerable to adversarial attacks, etc. Distinct from current GCN-based methods which simply employ GCN for recommendation, in this paper we are committed to build a robust GCN model for collaborative filtering. Firstly, we argue that recursively incorporating messages from different order neighborhood mixes distinct node messages indistinguishably, which increases the training difficulty; instead we choose to separately aggregate different order neighbor messages with a simple GCN model which has been shown effective; then we accumulate them together in a hierarchical way without introducing additional model parameters. Secondly, we propose a solution to alleviate over-smoothing by randomly dropping out neighbor messages at each layer, which also well prevents over-fitting and enhances the robustness. Extensive experiments on three real-world datasets demonstrate the effectiveness and robustness of our model.