 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMetric: A Driving Behavior Measure Using Centrality Functions
Mar 09, 2020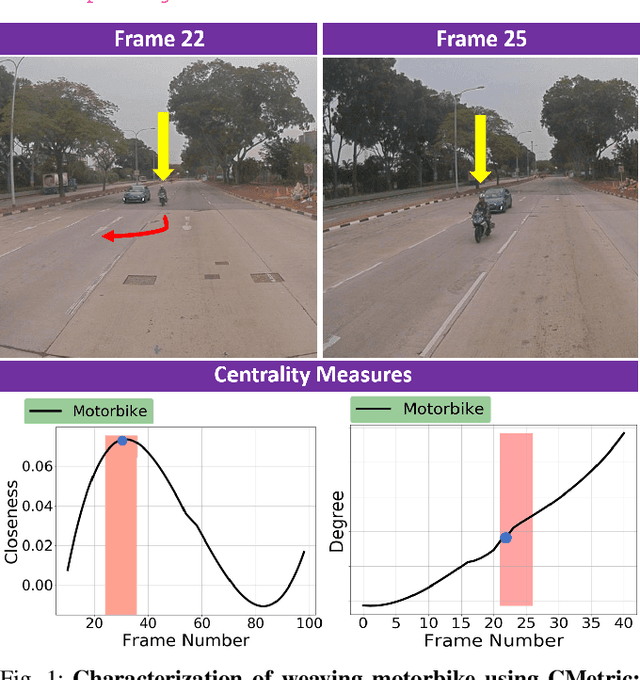
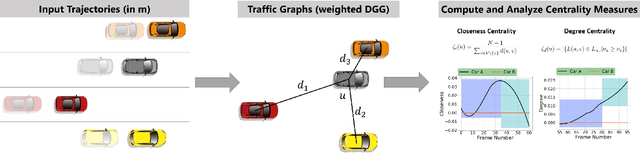
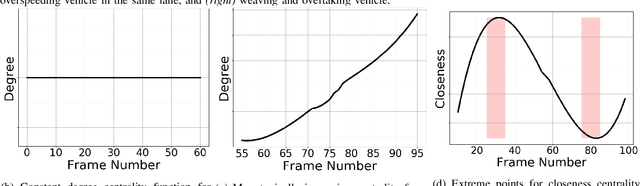
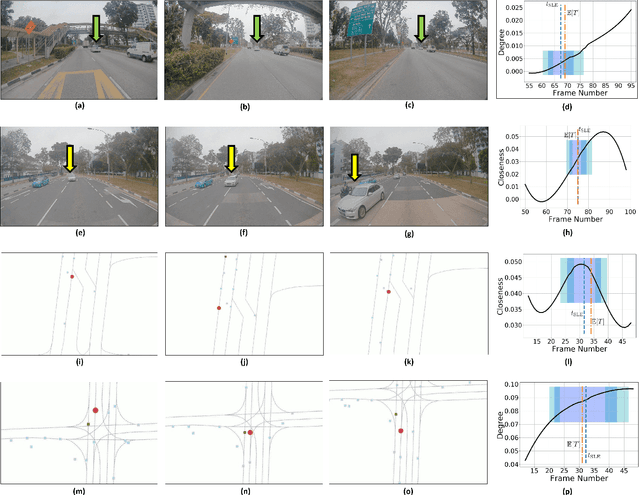
We present a new measure, CMetric, to classify driver behaviors using centrality functions. Our formulation combines concepts from computational graph theory and social traffic psychology to quantify and classify the behavior of human drivers. CMetric is used to compute the probability of a vehicle executing a driving style, as well as the intensity used to execute the style. Our approach is designed for realtime autonomous driving applications, where the trajectory of each vehicle or road-agent is extracted from a video. We compute a dynamic geometric graph (DGG) based on the positions and proximity of the road-agents and centrality functions corresponding to closeness and degree. These functions are used to compute the CMetric based on style likelihood and style intensity estimates. Our approach is general and makes no assumption about traffic density, heterogeneity, or how driving behaviors change over time. We present efficient techniques to compute CMetric and demonstrate its performance on well-known autonomous driving datasets. We evaluate the accuracy of CMetric and compare with ground truth behavior labels and with that of a human observer by performing a user study over over a long vehicle trajectory.
Forecasting Trajectory and Behavior of Road-Agents Using Spectral Clustering in Graph-LSTMs
Dec 02, 2019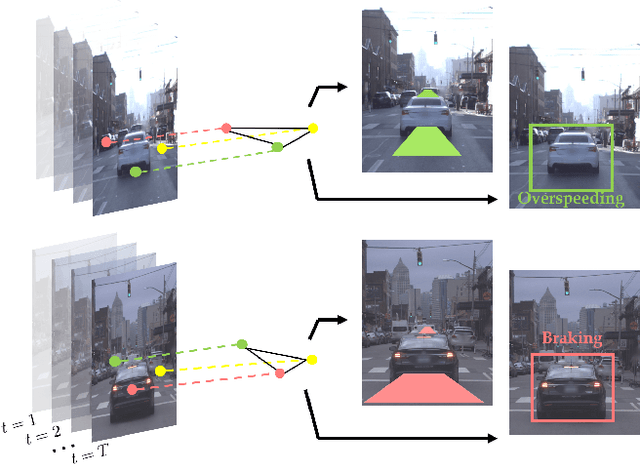

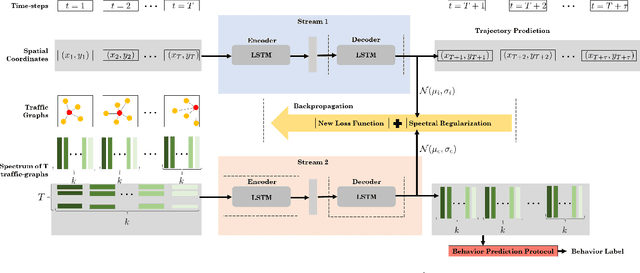

We present a novel approach for traffic forecasting in urban traffic scenarios using a combination of spectral graph analysis and deep learning. We predict both the low-level information (future trajectories) as well as the high-level information (road-agent behavior) from the extracted trajectory of each road-agent. Our formulation represents the proximity between the road agents using a dynamic weighted traffic-graph. We use a two-stream graph convolutional LSTM network to perform traffic forecasting using these weighted traffic-graphs. The first stream predicts the spatial coordinates of road-agents, while the second stream predicts whether a road-agent is going to exhibit aggressive, conservative, or normal behavior. We introduce spectral cluster regularization to reduce the error margin in long-term prediction (3-5 seconds) and improve the accuracy of the predicted trajectories. We evaluate our approach on the Argoverse, Lyft, and Apolloscape datasets and highlight the benefits over prior trajectory prediction methods. In practice, our approach reduces the average prediction error by more than 54% over prior algorithms and achieves a weighted average accuracy of 91.2% for behavior prediction.
M3ER: Multiplicative Multimodal Emotion Recognition Using Facial, Textual, and Speech Cues
Nov 22, 2019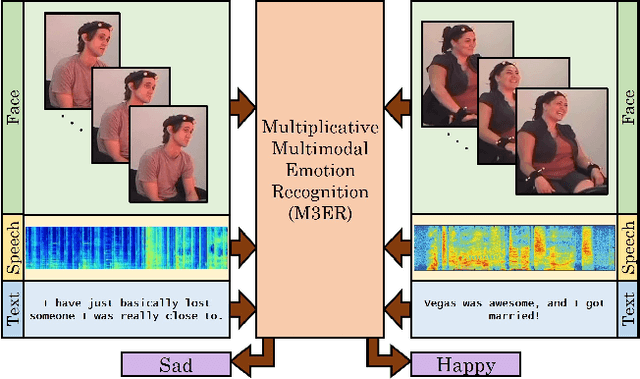
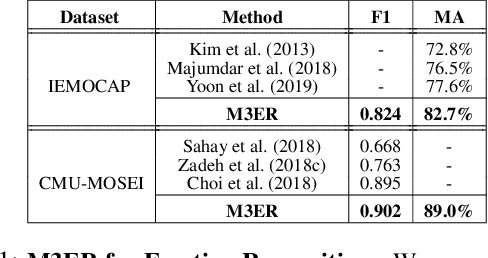
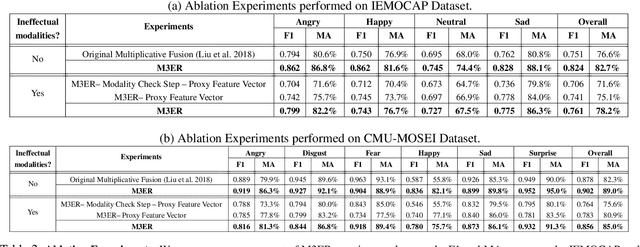
We present M3ER, a learning-based method for emotion recognition from multiple input modalities. Our approach combines cues from multiple co-occurring modalities (such as face, text, and speech) and also is more robust than other methods to sensor noise in any of the individual modalities. M3ER models a novel, data-driven multiplicative fusion method to combine the modalities, which learn to emphasize the more reliable cues and suppress others on a per-sample basis. By introducing a check step which uses Canonical Correlational Analysis to differentiate between ineffective and effective modalities, M3ER is robust to sensor noise. M3ER also generates proxy features in place of the ineffectual modalities. We demonstrate the efficiency of our network through experimentation on two benchmark datasets, IEMOCAP and CMU-MOSEI. We report a mean accuracy of 82.7% on IEMOCAP and 89.0% on CMU-MOSEI, which, collectively, is an improvement of about 5% over prior work.
Take an Emotion Walk: Perceiving Emotions from Gaits Using Hierarchical Attention Pooling and Affective Mapping
Nov 20, 2019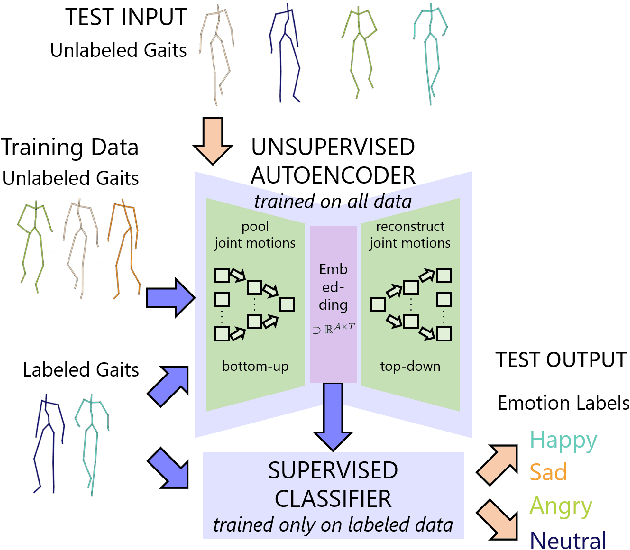

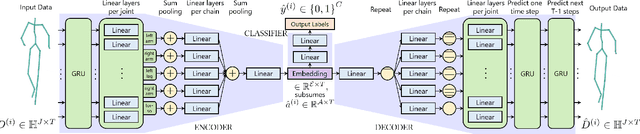
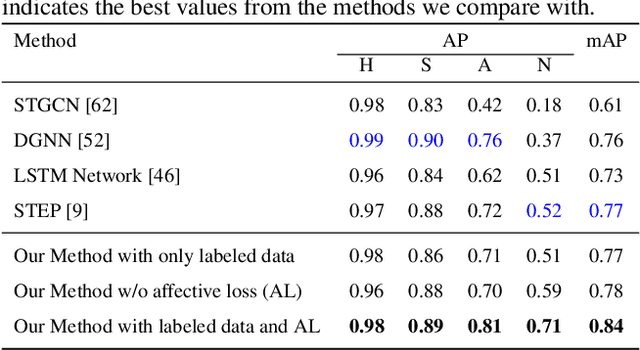
We present an autoencoder-based semi-supervised approach to classify perceived human emotions from walking styles obtained from videos or from motion-captured data and represented as sequences of 3D poses. Given the motion on each joint in the pose at each time step extracted from 3D pose sequences, we hierarchically pool these joint motions in a bottom-up manner in the encoder, following the kinematic chains in the human body. We also constrain the latent embeddings of the encoder to contain the space of psychologically-motivated affective features underlying the gaits. We train the decoder to reconstruct the motions per joint per time step in a top-down manner from the latent embeddings. For the annotated data, we also train a classifier to map the latent embeddings to emotion labels. Our semi-supervised approach achieves a mean average precision of 0.84 on the Emotion-Gait benchmark dataset, which contains gaits collected from multiple sources. We outperform current state-of-art algorithms for both emotion recognition and action recognition from 3D gaits by 7% -- 23% on the absolute.
STEP: Spatial Temporal Graph Convolutional Networks for Emotion Perception from Gaits
Oct 28, 2019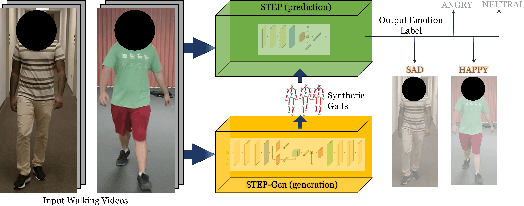
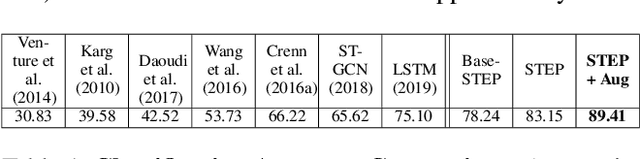
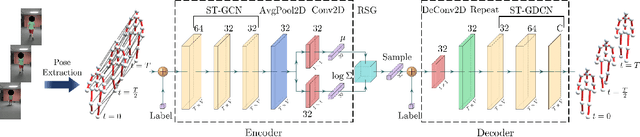

We present a novel classifier network called STEP, to classify perceived human emotion from gaits, based on a Spatial Temporal Graph Convolutional Network (ST-GCN) architecture. Given an RGB video of an individual walking, our formulation implicitly exploits the gait features to classify the emotional state of the human into one of four emotions: happy, sad, angry, or neutral. We use hundreds of annotated real-world gait videos and augment them with thousands of annotated synthetic gaits generated using a novel generative network called STEP-Gen, built on an ST-GCN based Conditional Variational Autoencoder (CVAE). We incorporate a novel push-pull regularization loss in the CVAE formulation of STEP-Gen to generate realistic gaits and improve the classification accuracy of STEP. We also release a novel dataset (E-Gait), which consists of $2,177$ human gaits annotated with perceived emotions along with thousands of synthetic gaits. In practice, STEP can learn the affective features and exhibits classification accuracy of 89% on E-Gait, which is 14 - 30% more accurate over prior methods.
GraphRQI: Classifying Driver Behaviors Using Graph Spectrums
Oct 05, 2019
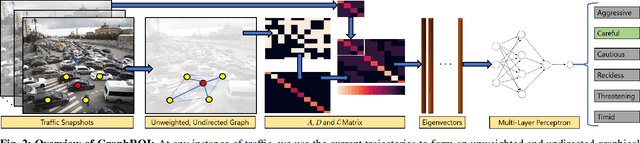
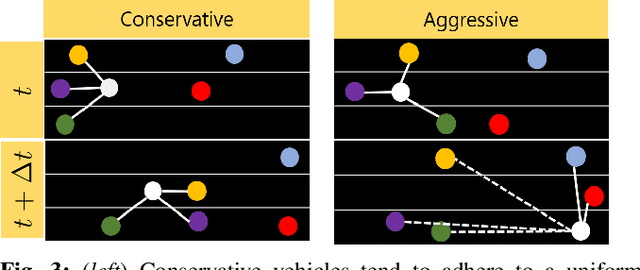

We present a novel algorithm (GraphRQI) to identify driver behaviors from road-agent trajectories. Our approach assumes that the road-agents exhibit a range of driving traits, such as aggressive or conservative driving. Moreover, these traits affect the trajectories of nearby road-agents as well as the interactions between road-agents. We represent these inter-agent interactions using unweighted and undirected traffic graphs. Our algorithm classifies the driver behavior using a supervised learning algorithm by reducing the computation to the spectral analysis of the traffic graph. Moreover, we present a novel eigenvalue algorithm to compute the spectrum efficiently. We provide theoretical guarantees for the running time complexity of our eigenvalue algorithm and show that it is faster than previous methods by 2 times. We evaluate the classification accuracy of our approach on traffic videos and autonomous driving datasets corresponding to urban traffic. In practice, GraphRQI achieves an accuracy improvement of up to 25% over prior driver behavior classification algorithms. We also use our classification algorithm to predict the future trajectories of road-agents.
Game of Sketches: Deep Recurrent Models of Pictionary-style Word Guessing
Jan 29, 2018
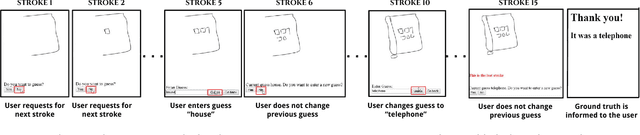
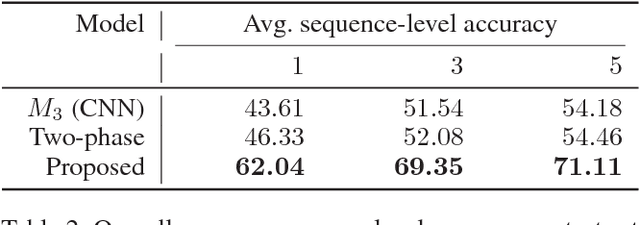
The ability of intelligent agents to play games in human-like fashion is popularly considered a benchmark of progress in Artificial Intelligence. Similarly, performance on multi-disciplinary tasks such as Visual Question Answering (VQA) is considered a marker for gauging progress in Computer Vision. In our work, we bring games and VQA together. Specifically, we introduce the first computational model aimed at Pictionary, the popular word-guessing social game. We first introduce Sketch-QA, an elementary version of Visual Question Answering task. Styled after Pictionary, Sketch-QA uses incrementally accumulated sketch stroke sequences as visual data. Notably, Sketch-QA involves asking a fixed question ("What object is being drawn?") and gathering open-ended guess-words from human guessers. We analyze the resulting dataset and present many interesting findings therein. To mimic Pictionary-style guessing, we subsequently propose a deep neural model which generates guess-words in response to temporally evolving human-drawn sketches. Our model even makes human-like mistakes while guessing, thus amplifying the human mimicry factor. We evaluate our model on the large-scale guess-word dataset generated via Sketch-QA task and compare with various baselines. We also conduct a Visual Turing Test to obtain human impressions of the guess-words generated by humans and our model. Experimental results demonstrate the promise of our approach for Pictionary and similarly themed games.