 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Punctuation in Ancient Chinese Texts: A Multi-Layered LSTM and Attention-Based Approach
Sep 16, 2024It was only until the 20th century when the Chinese language began using punctuation. In fact, many ancient Chinese texts contain thousands of lines with no distinct punctuation marks or delimiters in sight. The lack of punctuation in such texts makes it difficult for humans to identify when there pauses or breaks between particular phrases and understand the semantic meaning of the written text (Mogahed, 2012). As a result, unless one was educated in the ancient time period, many readers of ancient Chinese would have significantly different interpretations of the texts. We propose an approach to predict the location (and type) of punctuation in ancient Chinese texts that extends the work of Oh et al (2017) by leveraging a bidirectional multi-layered LSTM with a multi-head attention mechanism as inspired by Luong et al.'s (2015) discussion of attention-based architectures. We find that the use of multi-layered LSTMs and multi-head attention significantly outperforms RNNs that don't incorporate such components when evaluating ancient Chinese texts.
Trajectory Prediction using Generative Adversarial Network in Multi-Class Scenarios
Oct 18, 2021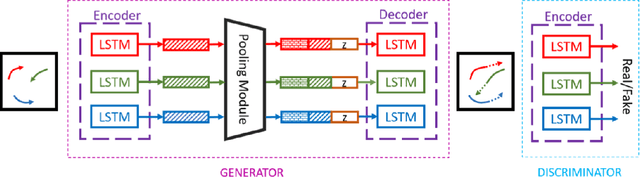
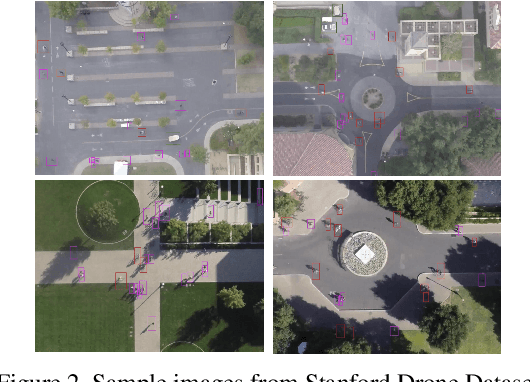
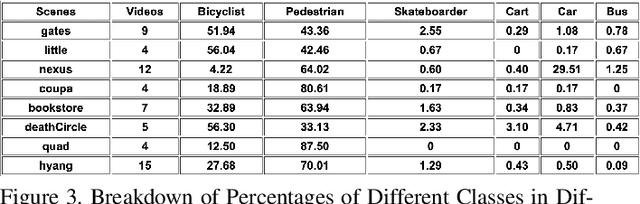
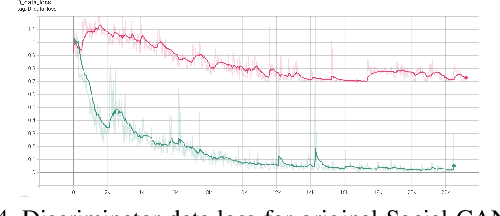
Predicting traffic agents' trajectories is an important task for auto-piloting. Most previous work on trajectory prediction only considers a single class of road agents. We use a sequence-to-sequence model to predict future paths from observed paths and we incorporate class information into the model by concatenating extracted label representations with traditional location inputs. We experiment with both LSTM and transformer encoders and we use generative adversarial network as introduced in Social GAN to learn the multi-modal behavior of traffic agents. We train our model on Stanford Drone dataset which includes 6 classes of road agents and evaluate the impact of different model components on the prediction performance in multi-class scenes.
Did the Model Change? Efficiently Assessing Machine Learning API Shifts
Jul 29, 2021
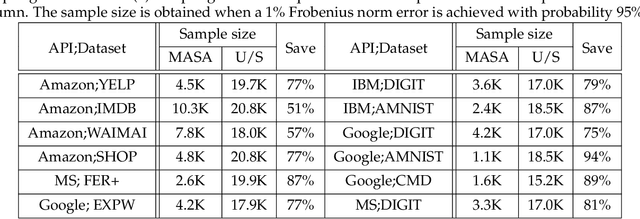
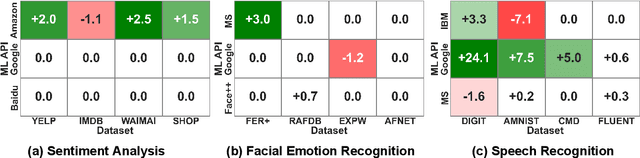
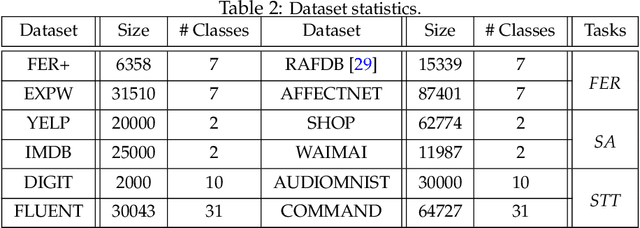
Machine learning (ML) prediction APIs are increasingly widely used. An ML API can change over time due to model updates or retraining. This presents a key challenge in the usage of the API because it is often not clear to the user if and how the ML model has changed. Model shifts can affect downstream application performance and also create oversight issues (e.g. if consistency is desired). In this paper, we initiate a systematic investigation of ML API shifts. We first quantify the performance shifts from 2020 to 2021 of popular ML APIs from Google, Microsoft, Amazon, and others on a variety of datasets. We identified significant model shifts in 12 out of 36 cases we investigated. Interestingly, we found several datasets where the API's predictions became significantly worse over time. This motivated us to formulate the API shift assessment problem at a more fine-grained level as estimating how the API model's confusion matrix changes over time when the data distribution is constant. Monitoring confusion matrix shifts using standard random sampling can require a large number of samples, which is expensive as each API call costs a fee. We propose a principled adaptive sampling algorithm, MASA, to efficiently estimate confusion matrix shifts. MASA can accurately estimate the confusion matrix shifts in commercial ML APIs using up to 90% fewer samples compared to random sampling. This work establishes ML API shifts as an important problem to study and provides a cost-effective approach to monitor such shifts.