 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlaying 2048 With Reinforcement Learning
Oct 20, 2021
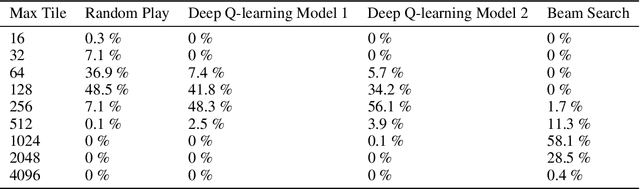
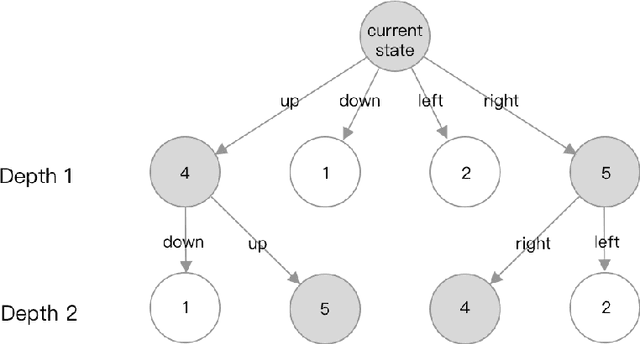
The game of 2048 is a highly addictive game. It is easy to learn the game, but hard to master as the created game revealed that only about 1% games out of hundreds million ever played have been won. In this paper, we would like to explore reinforcement learning techniques to win 2048. The approaches we have took include deep Q-learning and beam search, with beam search reaching 2048 28.5 of time.
Distributionally Robust Classifiers in Sentiment Analysis
Oct 20, 2021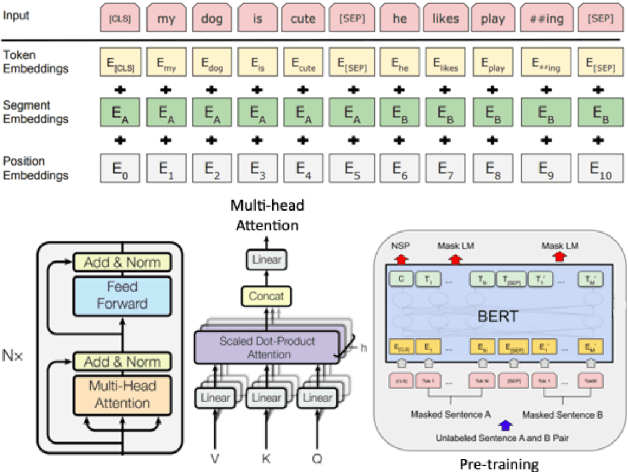


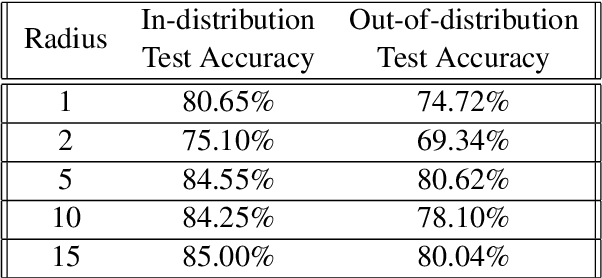
In this paper, we propose sentiment classification models based on BERT integrated with DRO (Distributionally Robust Classifiers) to improve model performance on datasets with distributional shifts. We added 2-Layer Bi-LSTM, projection layer (onto simplex or Lp ball), and linear layer on top of BERT to achieve distributionally robustness. We considered one form of distributional shift (from IMDb dataset to Rotten Tomatoes dataset). We have confirmed through experiments that our DRO model does improve performance on our test set with distributional shift from the training set.
Ensemble ALBERT on SQuAD 2.0
Oct 19, 2021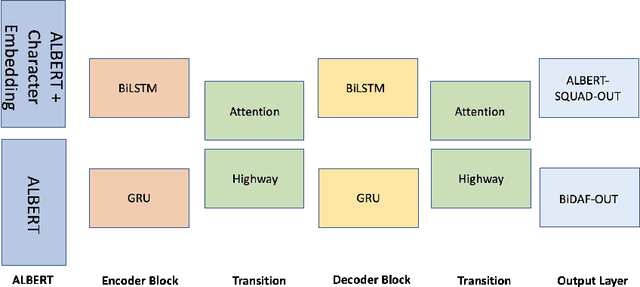

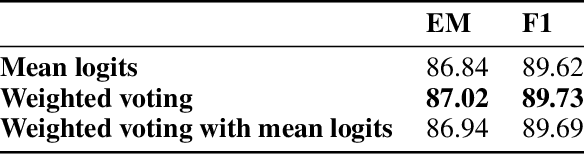
Machine question answering is an essential yet challenging task in natural language processing. Recently, Pre-trained Contextual Embeddings (PCE) models like Bidirectional Encoder Representations from Transformers (BERT) and A Lite BERT (ALBERT) have attracted lots of attention due to their great performance in a wide range of NLP tasks. In our Paper, we utilized the fine-tuned ALBERT models and implemented combinations of additional layers (e.g. attention layer, RNN layer) on top of them to improve model performance on Stanford Question Answering Dataset (SQuAD 2.0). We implemented four different models with different layers on top of ALBERT-base model, and two other models based on ALBERT-xlarge and ALBERT-xxlarge. We compared their performance to our baseline model ALBERT-base-v2 + ALBERT-SQuAD-out with details. Our best-performing individual model is ALBERT-xxlarge + ALBERT-SQuAD-out, which achieved an F1 score of 88.435 on the dev set. Furthermore, we have implemented three different ensemble algorithms to boost overall performance. By passing in several best-performing models' results into our weighted voting ensemble algorithm, our final result ranks first on the Stanford CS224N Test PCE SQuAD Leaderboard with F1 = 90.123.
Trajectory Prediction using Generative Adversarial Network in Multi-Class Scenarios
Oct 18, 2021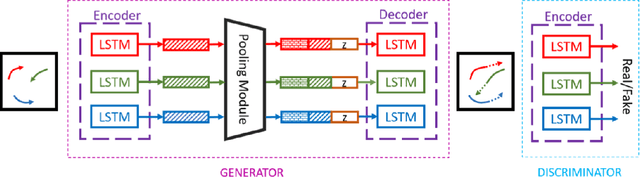
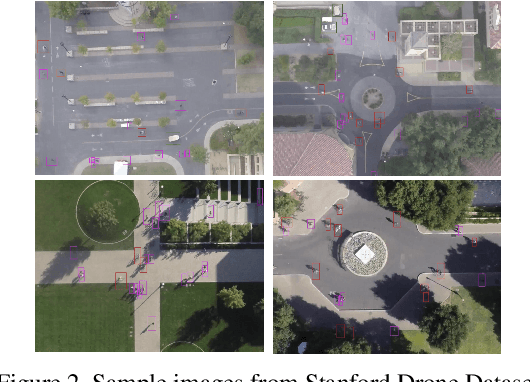
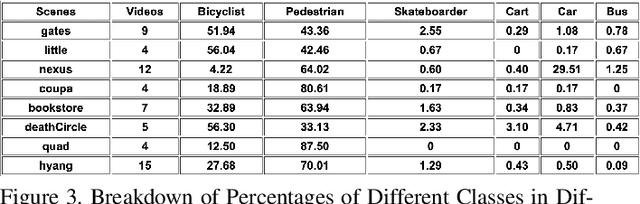
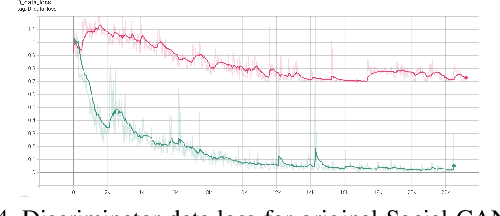
Predicting traffic agents' trajectories is an important task for auto-piloting. Most previous work on trajectory prediction only considers a single class of road agents. We use a sequence-to-sequence model to predict future paths from observed paths and we incorporate class information into the model by concatenating extracted label representations with traditional location inputs. We experiment with both LSTM and transformer encoders and we use generative adversarial network as introduced in Social GAN to learn the multi-modal behavior of traffic agents. We train our model on Stanford Drone dataset which includes 6 classes of road agents and evaluate the impact of different model components on the prediction performance in multi-class scenes.