 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Head Decoder for End-to-End Speech Recognition
Jul 28, 2018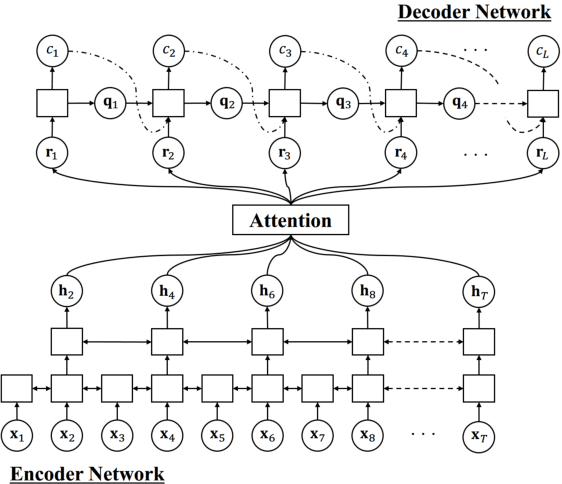
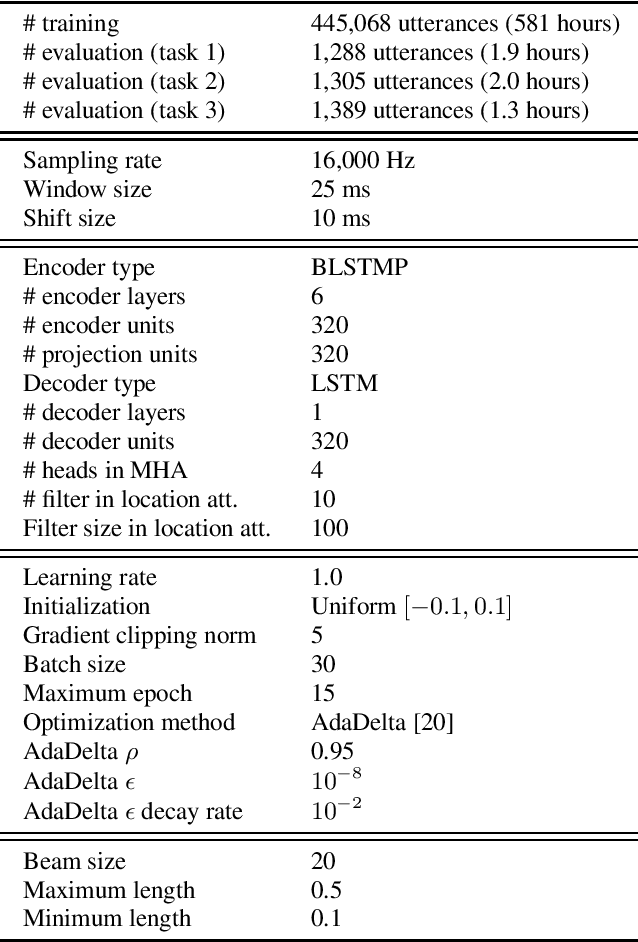
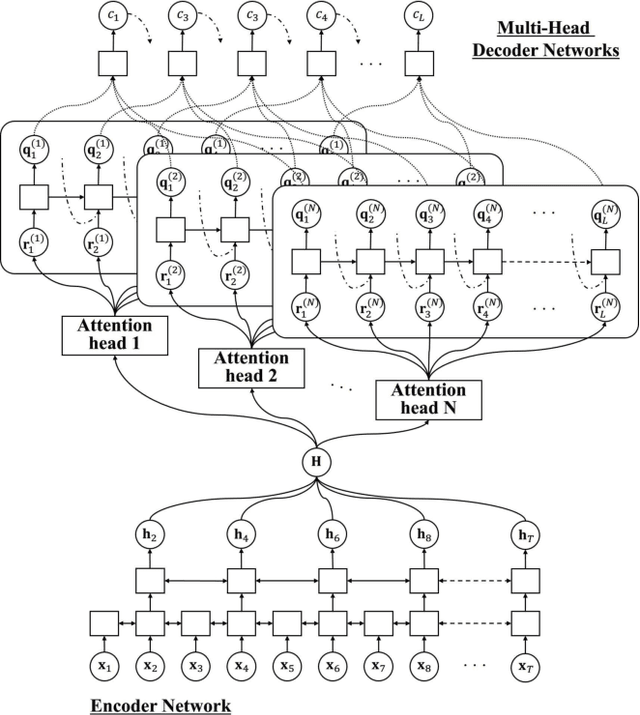
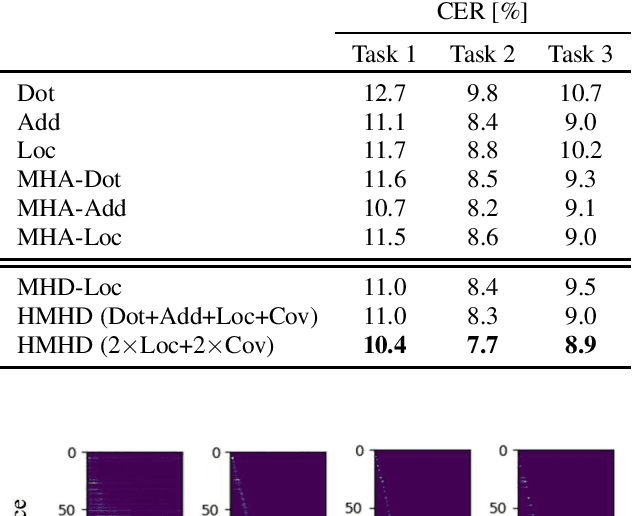
This paper presents a new network architecture called multi-head decoder for end-to-end speech recognition as an extension of a multi-head attention model. In the multi-head attention model, multiple attentions are calculated, and then, they are integrated into a single attention. On the other hand, instead of the integration in the attention level, our proposed method uses multiple decoders for each attention and integrates their outputs to generate a final output. Furthermore, in order to make each head to capture the different modalities, different attention functions are used for each head, leading to the improvement of the recognition performance with an ensemble effect. To evaluate the effectiveness of our proposed method, we conduct an experimental evaluation using Corpus of Spontaneous Japanese. Experimental results demonstrate that our proposed method outperforms the conventional methods such as location-based and multi-head attention models, and that it can capture different speech/linguistic contexts within the attention-based encoder-decoder framework.
ESPnet: End-to-End Speech Processing Toolkit
Mar 30, 2018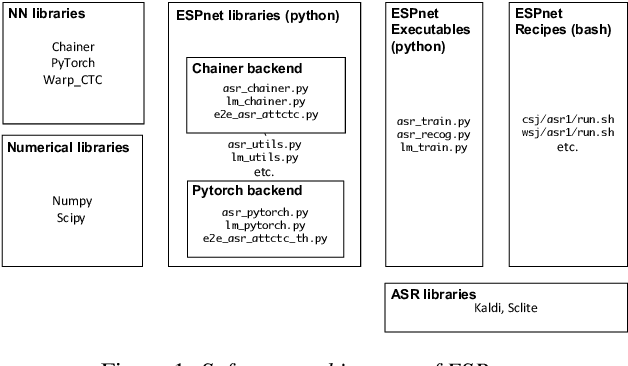
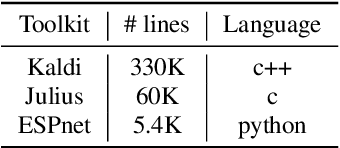
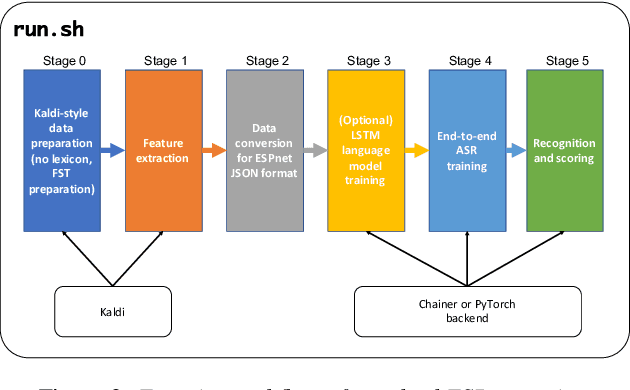
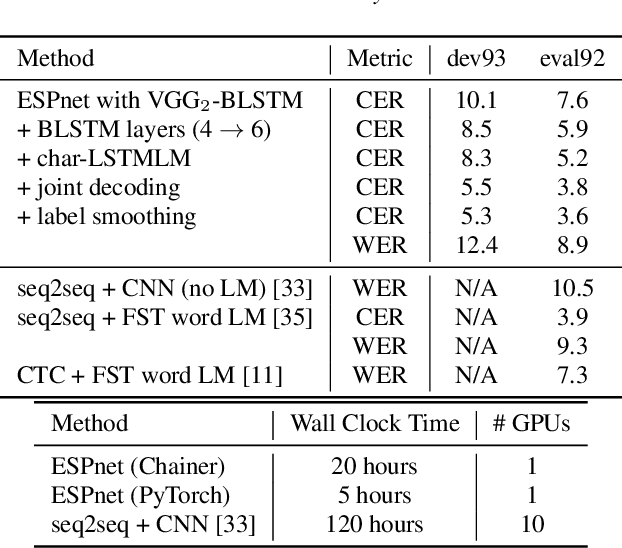
This paper introduces a new open source platform for end-to-end speech processing named ESPnet. ESPnet mainly focuses on end-to-end automatic speech recognition (ASR), and adopts widely-used dynamic neural network toolkits, Chainer and PyTorch, as a main deep learning engine. ESPnet also follows the Kaldi ASR toolkit style for data processing, feature extraction/format, and recipes to provide a complete setup for speech recognition and other speech processing experiments. This paper explains a major architecture of this software platform, several important functionalities, which differentiate ESPnet from other open source ASR toolkits, and experimental results with major ASR benchmarks.