 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Generative Spoken Language Modeling Encodes Noisy Speech: Investigation from Phonetics to Syntactics
Jun 01, 2023



We examine the speech modeling potential of generative spoken language modeling (GSLM), which involves using learned symbols derived from data rather than phonemes for speech analysis and synthesis. Since GSLM facilitates textless spoken language processing, exploring its effectiveness is critical for paving the way for novel paradigms in spoken-language processing. This paper presents the findings of GSLM's encoding and decoding effectiveness at the spoken-language and speech levels. Through speech resynthesis experiments, we revealed that resynthesis errors occur at the levels ranging from phonology to syntactics and GSLM frequently resynthesizes natural but content-altered speech.
jaCappella Corpus: A Japanese a Cappella Vocal Ensemble Corpus
Dec 09, 2022



We construct a corpus of Japanese a cappella vocal ensembles (jaCappella corpus) for vocal ensemble separation and synthesis. It consists of 35 copyright-cleared vocal ensemble songs and their audio recordings of individual voice parts. These songs were arranged from out-of-copyright Japanese children's songs and have six voice parts (lead vocal, soprano, alto, tenor, bass, and vocal percussion). They are divided into seven subsets, each of which features typical characteristics of a music genre such as jazz and enka. The variety in genre and voice part match vocal ensembles recently widespread in social media services such as YouTube, although the main targets of conventional vocal ensemble datasets are choral singing made up of soprano, alto, tenor, and bass. Experimental evaluation demonstrates that our corpus is a challenging resource for vocal ensemble separation. Our corpus is available on our project page (https://tomohikonakamura.github.io/jaCappella_corpus/).
Hyperbolic Timbre Embedding for Musical Instrument Sound Synthesis Based on Variational Autoencoders
Sep 27, 2022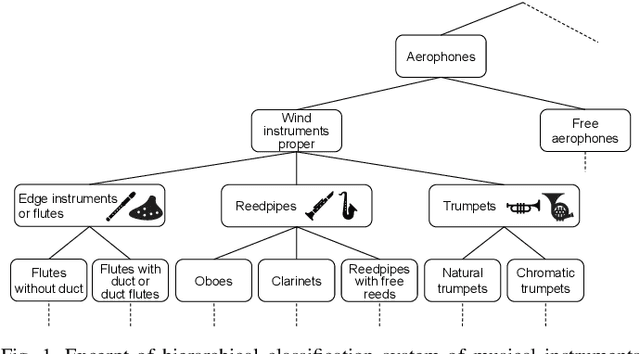
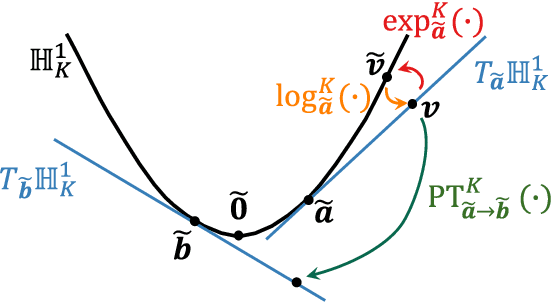
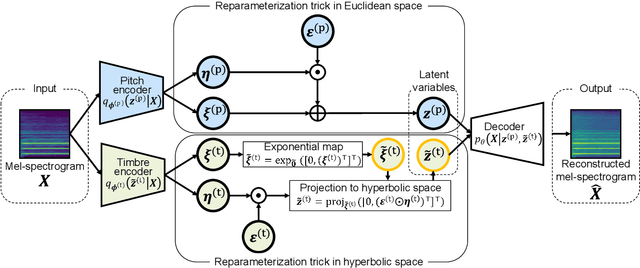
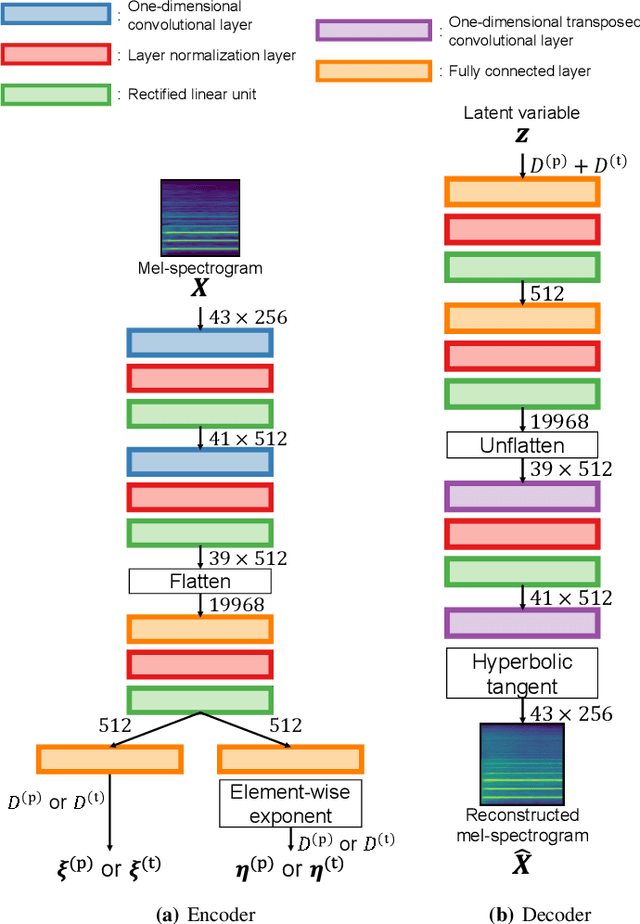
In this paper, we propose a musical instrument sound synthesis (MISS) method based on a variational autoencoder (VAE) that has a hierarchy-inducing latent space for timbre. VAE-based MISS methods embed an input signal into a low-dimensional latent representation that captures the characteristics of the input. Adequately manipulating this representation leads to sound morphing and timbre replacement. Although most VAE-based MISS methods seek a disentangled representation of pitch and timbre, how to capture an underlying structure in timbre remains an open problem. To address this problem, we focus on the fact that musical instruments can be hierarchically classified on the basis of their physical mechanisms. Motivated by this hierarchy, we propose a VAE-based MISS method by introducing a hyperbolic space for timbre. The hyperbolic space can represent treelike data more efficiently than the Euclidean space owing to its exponential growth property. Results of experiments show that the proposed method provides an efficient latent representation of timbre compared with the method using the Euclidean space.
Head-Related Transfer Function Interpolation from Spatially Sparse Measurements Using Autoencoder with Source Position Conditioning
Jul 22, 2022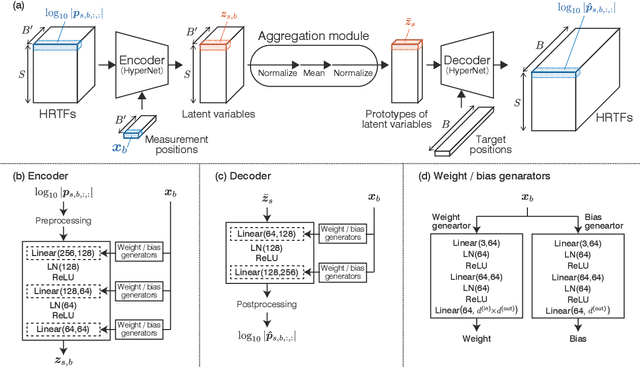
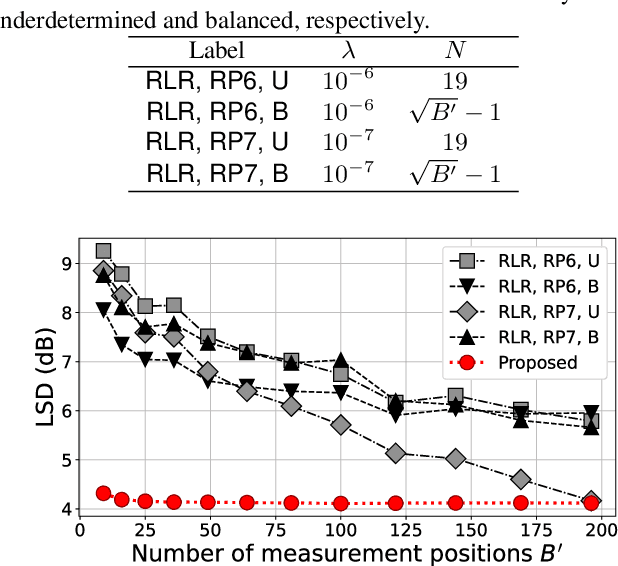
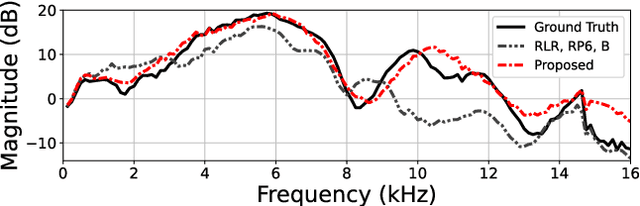
We propose a method of head-related transfer function (HRTF) interpolation from sparsely measured HRTFs using an autoencoder with source position conditioning. The proposed method is drawn from an analogy between an HRTF interpolation method based on regularized linear regression (RLR) and an autoencoder. Through this analogy, we found the key feature of the RLR-based method that HRTFs are decomposed into source-position-dependent and source-position-independent factors. On the basis of this finding, we design the encoder and decoder so that their weights and biases are generated from source positions. Furthermore, we introduce an aggregation module that reduces the dependence of latent variables on source position for obtaining a source-position-independent representation of each subject. Numerical experiments show that the proposed method can work well for unseen subjects and achieve an interpolation performance with only one-eighth measurements comparable to that of the RLR-based method.
Physics-informed convolutional neural network with bicubic spline interpolation for sound field estimation
Jul 22, 2022
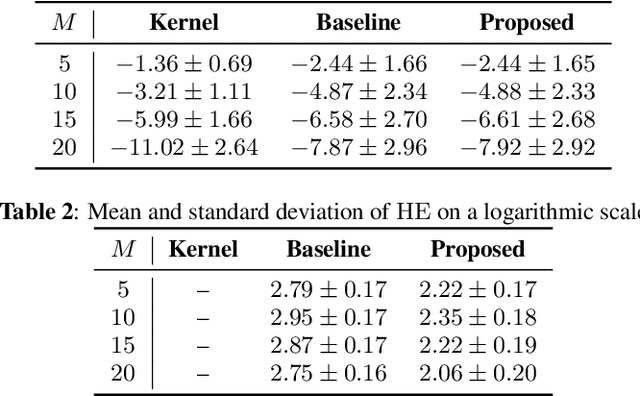
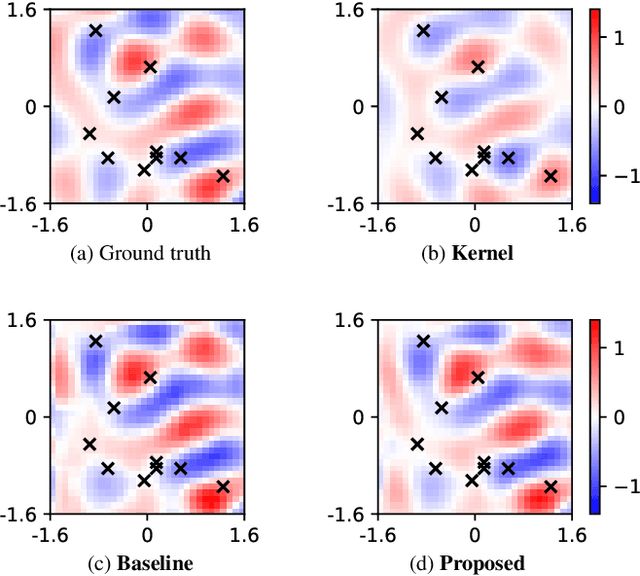
A sound field estimation method based on a physics-informed convolutional neural network (PICNN) using spline interpolation is proposed. Most of the sound field estimation methods are based on wavefunction expansion, making the estimated function satisfy the Helmholtz equation. However, these methods rely only on physical properties; thus, they suffer from a significant deterioration of accuracy when the number of measurements is small. Recent learning-based methods based on neural networks have advantages in estimating from sparse measurements when training data are available. However, since physical properties are not taken into consideration, the estimated function can be a physically infeasible solution. We propose the application of PICNN to the sound field estimation problem by using a loss function that penalizes deviation from the Helmholtz equation. Since the output of CNN is a spatially discretized pressure distribution, it is difficult to directly evaluate the Helmholtz-equation loss function. Therefore, we incorporate bicubic spline interpolation in the PICNN framework. Experimental results indicated that accurate and physically feasible estimation from sparse measurements can be achieved with the proposed method.
SelfRemaster: Self-Supervised Speech Restoration with Analysis-by-Synthesis Approach Using Channel Modeling
Mar 24, 2022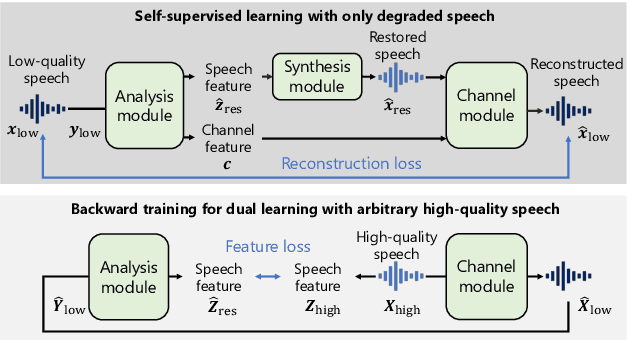
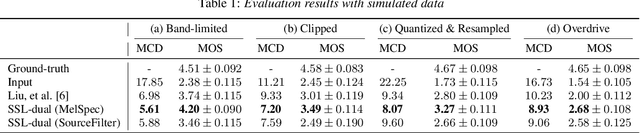
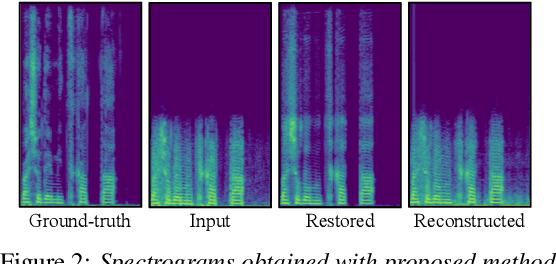
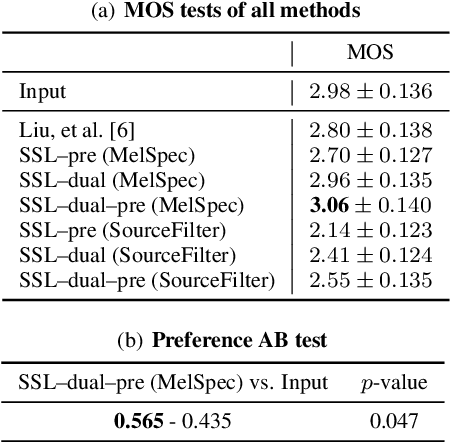
We present a self-supervised speech restoration method without paired speech corpora. Because the previous general speech restoration method uses artificial paired data created by applying various distortions to high-quality speech corpora, it cannot sufficiently represent acoustic distortions of real data, limiting the applicability. Our model consists of analysis, synthesis, and channel modules that simulate the recording process of degraded speech and is trained with real degraded speech data in a self-supervised manner. The analysis module extracts distortionless speech features and distortion features from degraded speech, while the synthesis module synthesizes the restored speech waveform, and the channel module adds distortions to the speech waveform. Our model also enables audio effect transfer, in which only acoustic distortions are extracted from degraded speech and added to arbitrary high-quality audio. Experimental evaluations with both simulated and real data show that our method achieves significantly higher-quality speech restoration than the previous supervised method, suggesting its applicability to real degraded speech materials.
Differentiable Digital Signal Processing Mixture Model for Synthesis Parameter Extraction from Mixture of Harmonic Sounds
Feb 01, 2022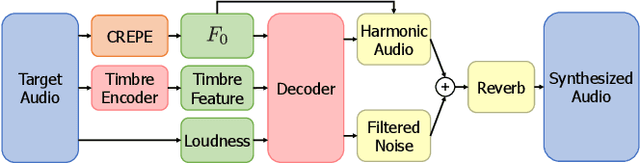
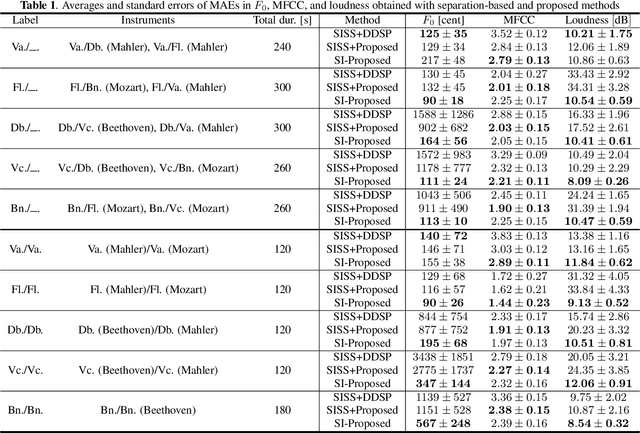
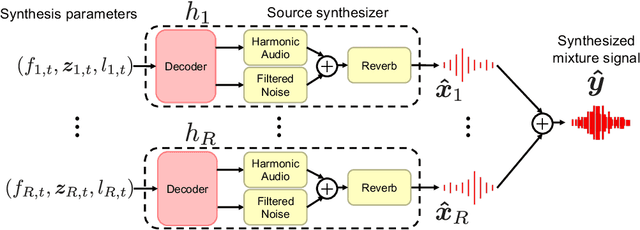
A differentiable digital signal processing (DDSP) autoencoder is a musical sound synthesizer that combines a deep neural network (DNN) and spectral modeling synthesis. It allows us to flexibly edit sounds by changing the fundamental frequency, timbre feature, and loudness (synthesis parameters) extracted from an input sound. However, it is designed for a monophonic harmonic sound and cannot handle mixtures of harmonic sounds. In this paper, we propose a model (DDSP mixture model) that represents a mixture as the sum of the outputs of multiple pretrained DDSP autoencoders. By fitting the output of the proposed model to the observed mixture, we can directly estimate the synthesis parameters of each source. Through synthesis parameter extraction experiments, we show that the proposed method has high and stable performance compared with a straightforward method that applies the DDSP autoencoder to the signals separated by an audio source separation method.
Speech Enhancement by Noise Self-Supervised Rank-Constrained Spatial Covariance Matrix Estimation via Independent Deeply Learned Matrix Analysis
Sep 10, 2021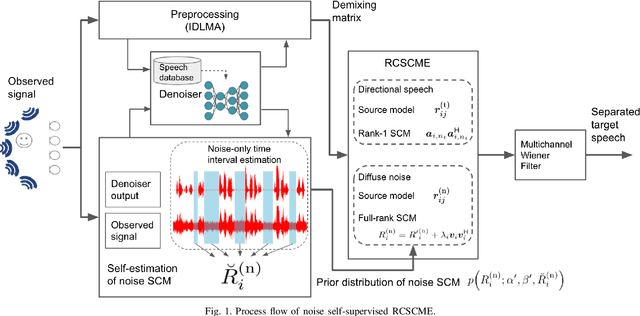
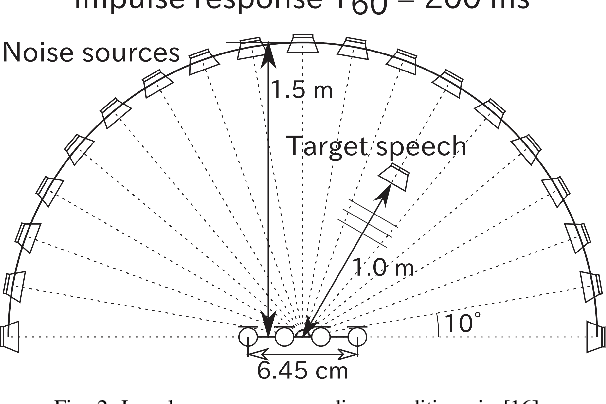
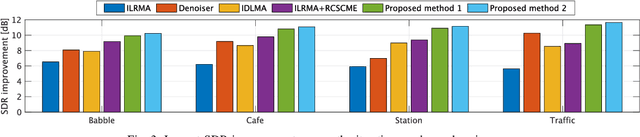
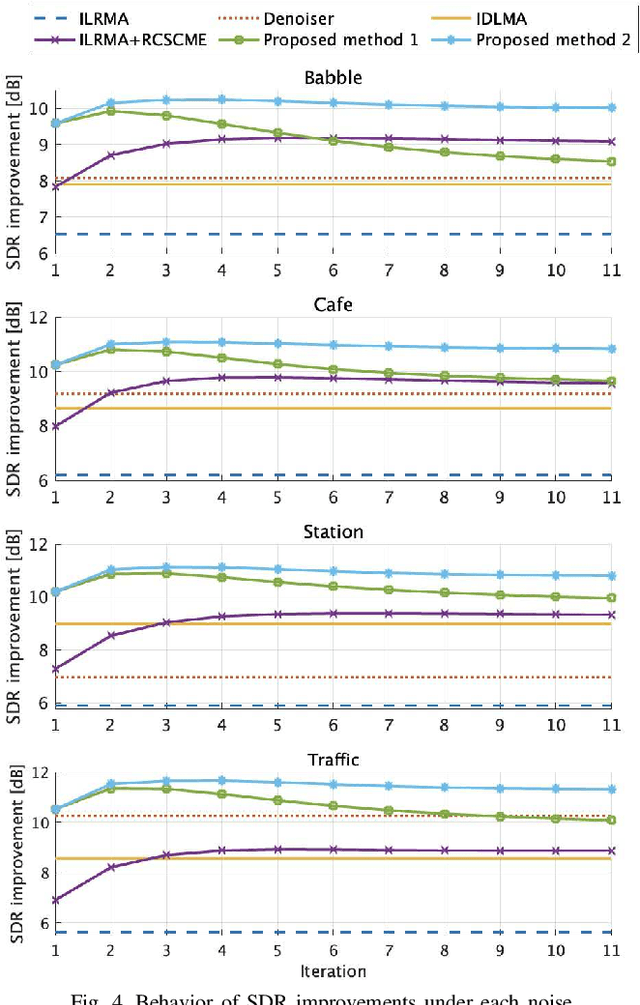
Rank-constrained spatial covariance matrix estimation (RCSCME) is a method for the situation that the directional target speech and the diffuse noise are mixed. In conventional RCSCME, independent low-rank matrix analysis (ILRMA) is used as the preprocessing method. We propose RCSCME using independent deeply learned matrix analysis (IDLMA), which is a supervised extension of ILRMA. In this method, IDLMA requires deep neural networks (DNNs) to separate the target speech and the noise. We use Denoiser, which is a single-channel speech enhancement DNN, in IDLMA to estimate not only the target speech but also the noise. We also propose noise self-supervised RCSCME, in which we estimate the noise-only time intervals using the output of Denoiser and design the prior distribution of the noise spatial covariance matrix for RCSCME. We confirm that the proposed methods outperform the conventional methods under several noise conditions.
Multichannel Audio Source Separation with Independent Deeply Learned Matrix Analysis Using Product of Source Models
Sep 02, 2021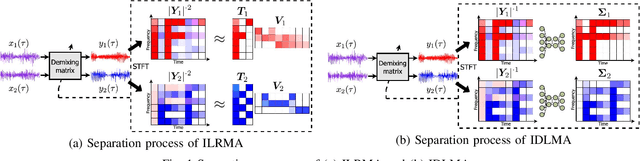
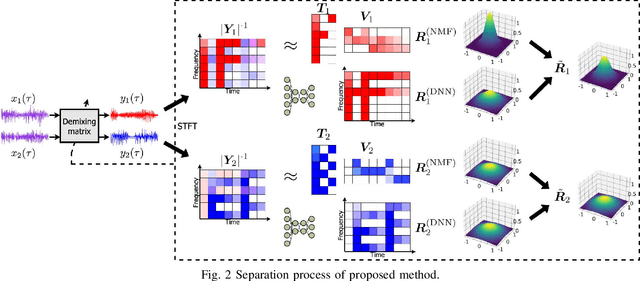
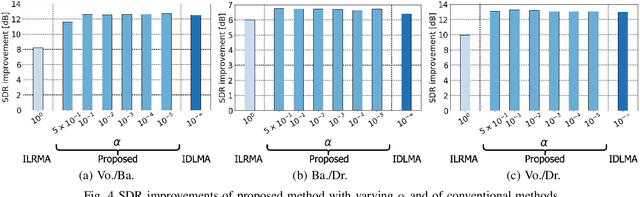
Independent deeply learned matrix analysis (IDLMA) is one of the state-of-the-art multichannel audio source separation methods using the source power estimation based on deep neural networks (DNNs). The DNN-based power estimation works well for sounds having timbres similar to the DNN training data. However, the sounds to which IDLMA is applied do not always have such timbres, and the timbral mismatch causes the performance degradation of IDLMA. To tackle this problem, we focus on a blind source separation counterpart of IDLMA, independent low-rank matrix analysis. It uses nonnegative matrix factorization (NMF) as the source model, which can capture source spectral components that only appear in the target mixture, using the low-rank structure of the source spectrogram as a clue. We thus extend the DNN-based source model to encompass the NMF-based source model on the basis of the product-of-expert concept, which we call the product of source models (PoSM). For the proposed PoSM-based IDLMA, we derive a computationally efficient parameter estimation algorithm based on an optimization principle called the majorization-minimization algorithm. Experimental evaluations show the effectiveness of the proposed method.
Prior Distribution Design for Music Bleeding-Sound Reduction Based on Nonnegative Matrix Factorization
Sep 01, 2021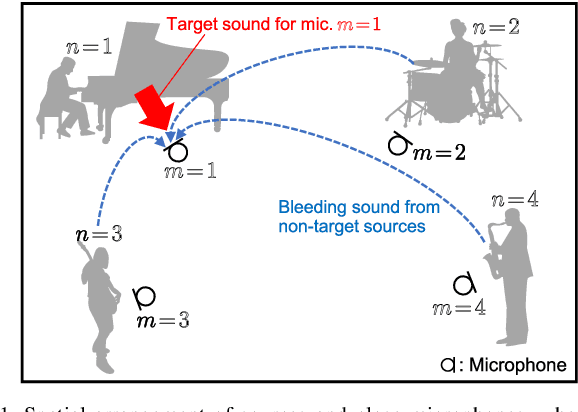
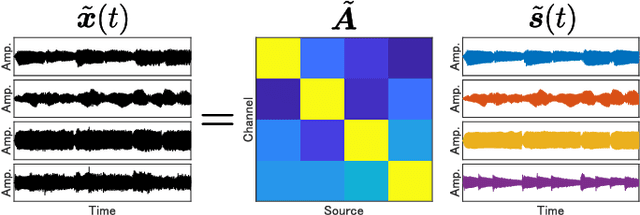
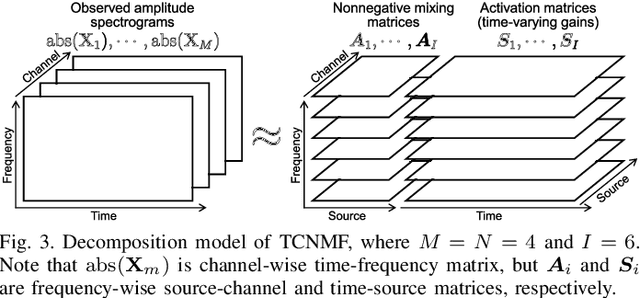
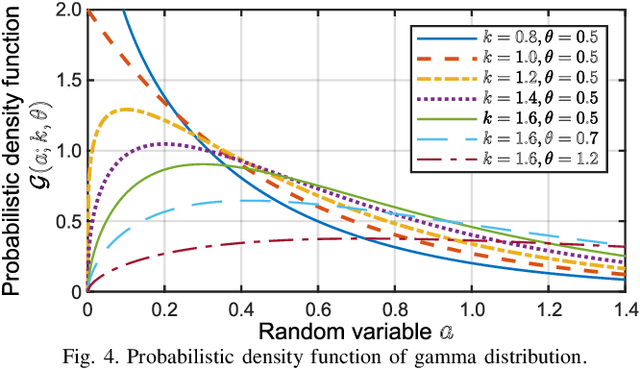
When we place microphones close to a sound source near other sources in audio recording, the obtained audio signal includes undesired sound from the other sources, which is often called cross-talk or bleeding sound. For many audio applications including onstage sound reinforcement and sound editing after a live performance, it is important to reduce the bleeding sound in each recorded signal. However, since microphones are spatially apart from each other in this situation, typical phase-aware blind source separation (BSS) methods cannot be used. We propose a phase-insensitive method for blind bleeding-sound reduction. This method is based on time-channel nonnegative matrix factorization, which is a BSS method using only amplitude spectrograms. With the proposed method, we introduce the gamma-distribution-based prior for leakage levels of bleeding sounds. Its optimization can be interpreted as maximum a posteriori estimation. The experimental results of music bleeding-sound reduction indicate that the proposed method is more effective for bleeding-sound reduction of music signals compared with other BSS methods.