 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFundamental Limits and Tradeoffs in Invariant Representation Learning
Dec 19, 2020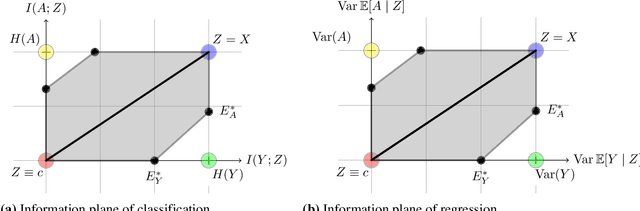
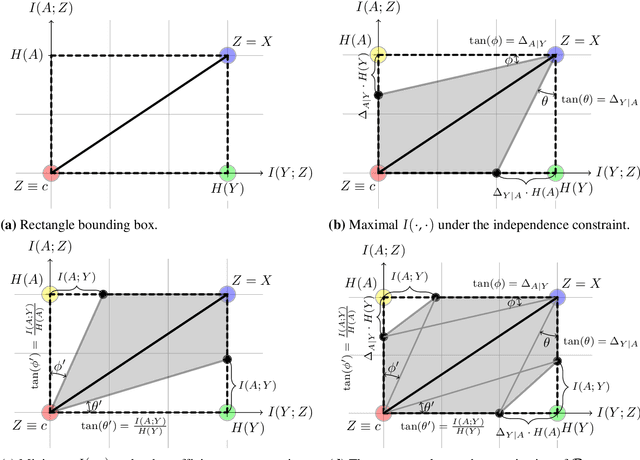
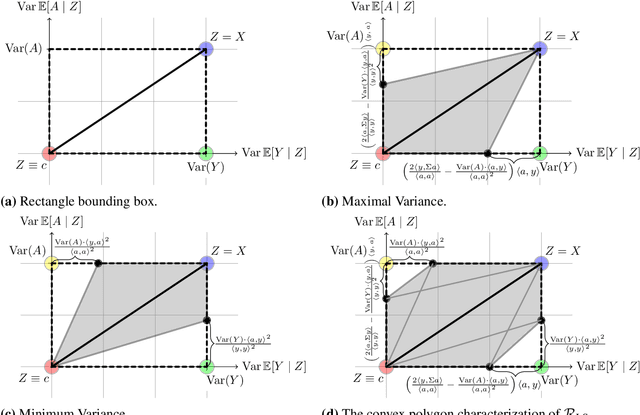
Many machine learning applications involve learning representations that achieve two competing goals: To maximize information or accuracy with respect to a subset of features (e.g.\ for prediction) while simultaneously maximizing invariance or independence with respect to another, potentially overlapping, subset of features (e.g.\ for fairness, privacy, etc). Typical examples include privacy-preserving learning, domain adaptation, and algorithmic fairness, just to name a few. In fact, all of the above problems admit a common minimax game-theoretic formulation, whose equilibrium represents a fundamental tradeoff between accuracy and invariance. Despite its abundant applications in the aforementioned domains, theoretical understanding on the limits and tradeoffs of invariant representations is severely lacking. In this paper, we provide an information-theoretic analysis of this general and important problem under both classification and regression settings. In both cases, we analyze the inherent tradeoffs between accuracy and invariance by providing a geometric characterization of the feasible region in the information plane, where we connect the geometric properties of this feasible region to the fundamental limitations of the tradeoff problem. In the regression setting, we also derive a tight lower bound on the Lagrangian objective that quantifies the tradeoff between accuracy and invariance. This lower bound leads to a better understanding of the tradeoff via the spectral properties of the joint distribution. In both cases, our results shed new light on this fundamental problem by providing insights on the interplay between accuracy and invariance. These results deepen our understanding of this fundamental problem and may be useful in guiding the design of adversarial representation learning algorithms.
Invariant Rationalization
Mar 22, 2020

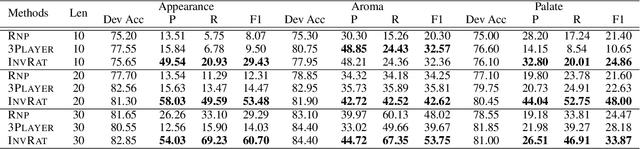
Selective rationalization improves neural network interpretability by identifying a small subset of input features -- the rationale -- that best explains or supports the prediction. A typical rationalization criterion, i.e. maximum mutual information (MMI), finds the rationale that maximizes the prediction performance based only on the rationale. However, MMI can be problematic because it picks up spurious correlations between the input features and the output. Instead, we introduce a game-theoretic invariant rationalization criterion where the rationales are constrained to enable the same predictor to be optimal across different environments. We show both theoretically and empirically that the proposed rationales can rule out spurious correlations, generalize better to different test scenarios, and align better with human judgments. Our data and code are available.
Unsupervised Hierarchy Matching with Optimal Transport over Hyperbolic Spaces
Nov 06, 2019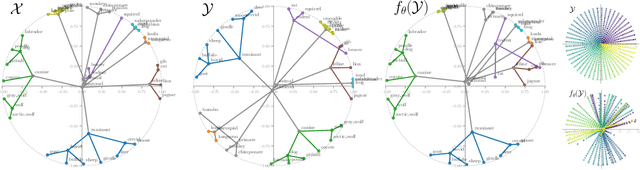
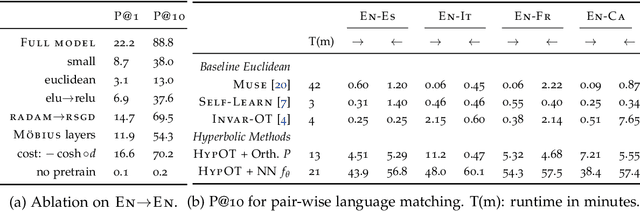
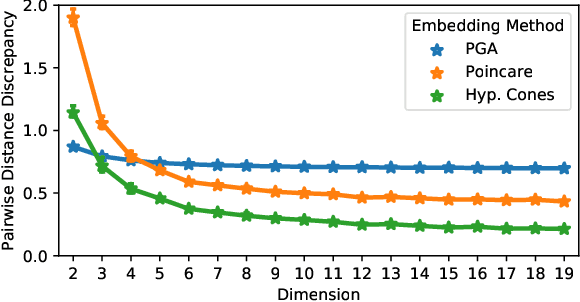
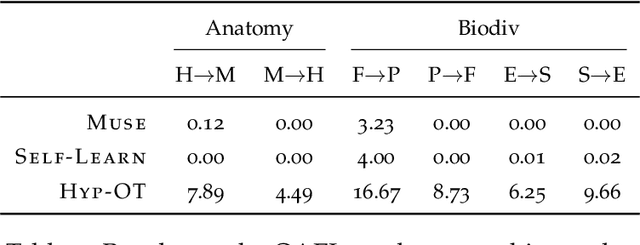
This paper focuses on the problem of unsupervised alignment of hierarchical data such as ontologies or lexical databases. This is a problem that appears across areas, from natural language processing to bioinformatics, and is typically solved by appeal to outside knowledge bases and label-textual similarity. In contrast, we approach the problem from a purely geometric perspective: given only a vector-space representation of the items in the two hierarchies, we seek to infer correspondences across them. Our work derives from and interweaves hyperbolic-space representations for hierarchical data, on one hand, and unsupervised word-alignment methods, on the other. We first provide a set of negative results showing how and why Euclidean methods fail in this hyperbolic setting. We then propose a novel approach based on optimal transport over hyperbolic spaces, and show that it outperforms standard embedding alignment techniques in various experiments on cross-lingual WordNet alignment and ontology matching tasks.
Rethinking Cooperative Rationalization: Introspective Extraction and Complement Control
Oct 29, 2019
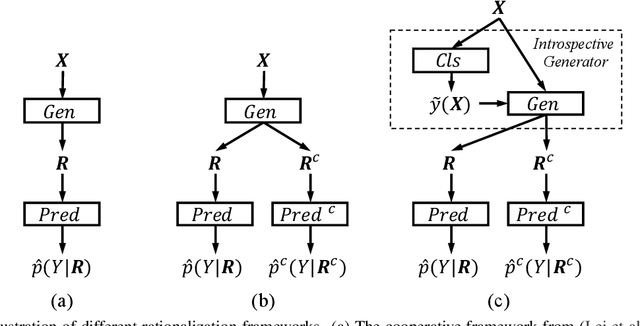
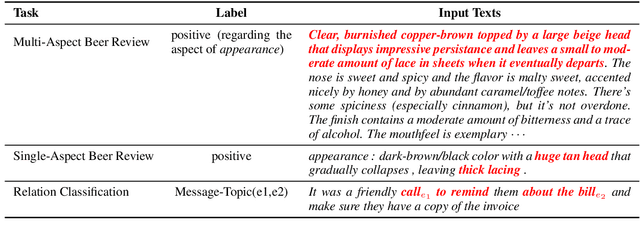
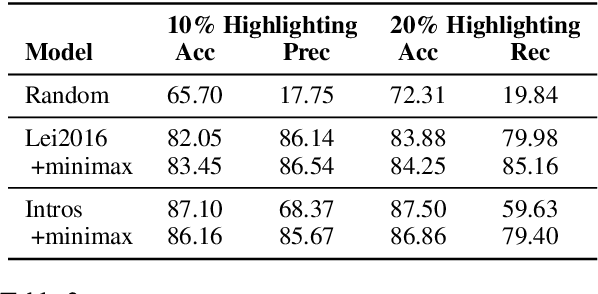
Selective rationalization has become a common mechanism to ensure that predictive models reveal how they use any available features. The selection may be soft or hard, and identifies a subset of input features relevant for prediction. The setup can be viewed as a co-operate game between the selector (aka rationale generator) and the predictor making use of only the selected features. The co-operative setting may, however, be compromised for two reasons. First, the generator typically has no direct access to the outcome it aims to justify, resulting in poor performance. Second, there's typically no control exerted on the information left outside the selection. We revise the overall co-operative framework to address these challenges. We introduce an introspective model which explicitly predicts and incorporates the outcome into the selection process. Moreover, we explicitly control the rationale complement via an adversary so as not to leave any useful information out of the selection. We show that the two complementary mechanisms maintain both high predictive accuracy and lead to comprehensive rationales.
A Game Theoretic Approach to Class-wise Selective Rationalization
Oct 28, 2019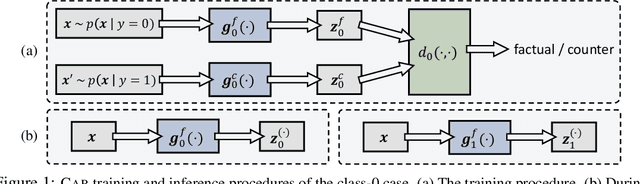

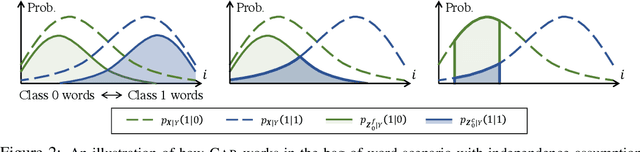
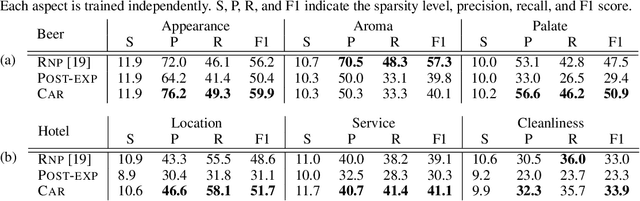
Selection of input features such as relevant pieces of text has become a common technique of highlighting how complex neural predictors operate. The selection can be optimized post-hoc for trained models or incorporated directly into the method itself (self-explaining). However, an overall selection does not properly capture the multi-faceted nature of useful rationales such as pros and cons for decisions. To this end, we propose a new game theoretic approach to class-dependent rationalization, where the method is specifically trained to highlight evidence supporting alternative conclusions. Each class involves three players set up competitively to find evidence for factual and counterfactual scenarios. We show theoretically in a simplified scenario how the game drives the solution towards meaningful class-dependent rationales. We evaluate the method in single- and multi-aspect sentiment classification tasks and demonstrate that the proposed method is able to identify both factual (justifying the ground truth label) and counterfactual (countering the ground truth label) rationales consistent with human rationalization. The code for our method is publicly available.
Learning to Make Generalizable and Diverse Predictions for Retrosynthesis
Oct 21, 2019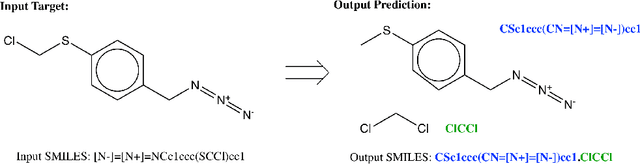
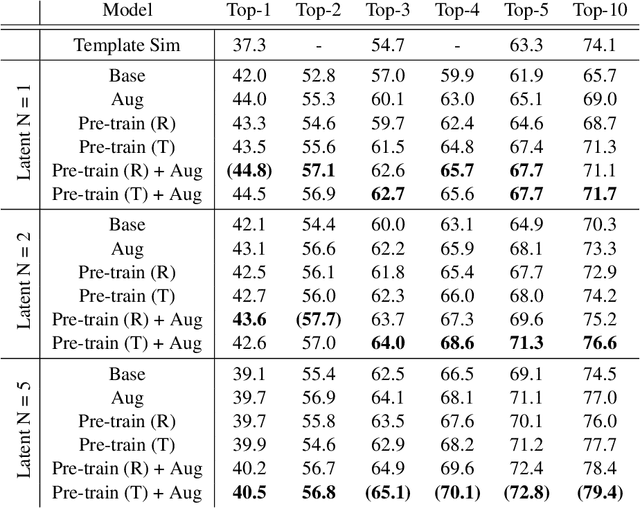
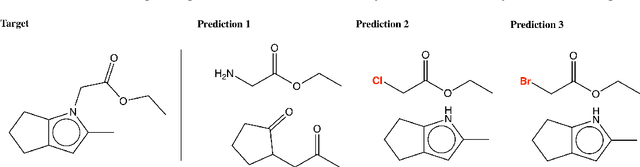

We propose a new model for making generalizable and diverse retrosynthetic reaction predictions. Given a target compound, the task is to predict the likely chemical reactants to produce the target. This generative task can be framed as a sequence-to-sequence problem by using the SMILES representations of the molecules. Building on top of the popular Transformer architecture, we propose two novel pre-training methods that construct relevant auxiliary tasks (plausible reactions) for our problem. Furthermore, we incorporate a discrete latent variable model into the architecture to encourage the model to produce a diverse set of alternative predictions. On the 50k subset of reaction examples from the United States patent literature (USPTO-50k) benchmark dataset, our model greatly improves performance over the baseline, while also generating predictions that are more diverse.
Locally Constant Networks
Sep 30, 2019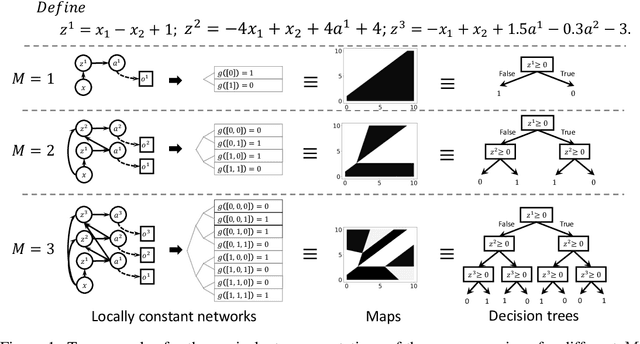
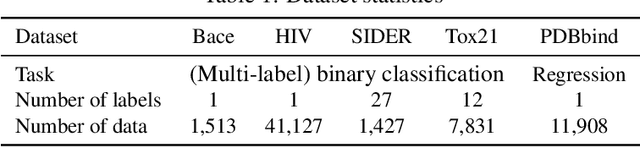
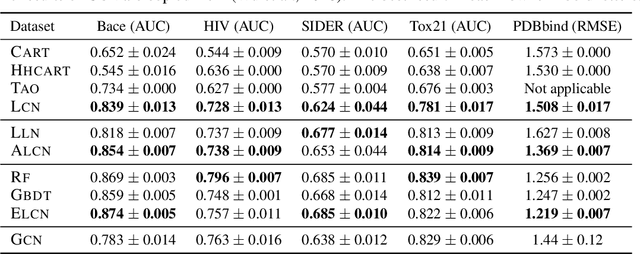
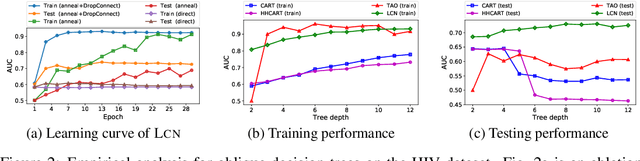
We show how neural models can be used to realize piece-wise constant functions such as decision trees. Our approach builds on ReLU networks that are piece-wise linear and hence their associated gradients with respect to the inputs are locally constant. We formally establish the equivalence between the classes of locally constant networks and decision trees. Moreover, we highlight several advantageous properties of locally constant networks, including how they realize decision trees with parameter sharing across branching / leaves. Indeed, only $M$ neurons suffice to implicitly model an oblique decision tree with $2^M$ leaf nodes. The neural representation also enables us to adopt many tools developed for deep networks (e.g., DropConnect (Wan et al. 2013)) while implicitly training decision trees. We demonstrate that our method outperforms alternative techniques for training oblique decision trees in the context of molecular property classification and regression tasks.
Towards Robust, Locally Linear Deep Networks
Jul 07, 2019

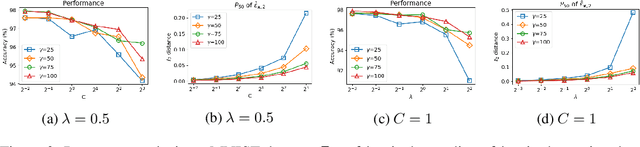

Deep networks realize complex mappings that are often understood by their locally linear behavior at or around points of interest. For example, we use the derivative of the mapping with respect to its inputs for sensitivity analysis, or to explain (obtain coordinate relevance for) a prediction. One key challenge is that such derivatives are themselves inherently unstable. In this paper, we propose a new learning problem to encourage deep networks to have stable derivatives over larger regions. While the problem is challenging in general, we focus on networks with piecewise linear activation functions. Our algorithm consists of an inference step that identifies a region around a point where linear approximation is provably stable, and an optimization step to expand such regions. We propose a novel relaxation to scale the algorithm to realistic models. We illustrate our method with residual and recurrent networks on image and sequence datasets.
A Stratified Approach to Robustness for Randomly Smoothed Classifiers
Jun 12, 2019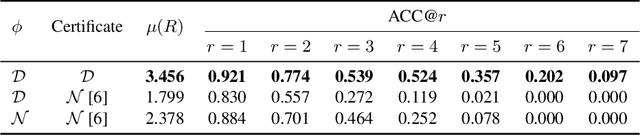
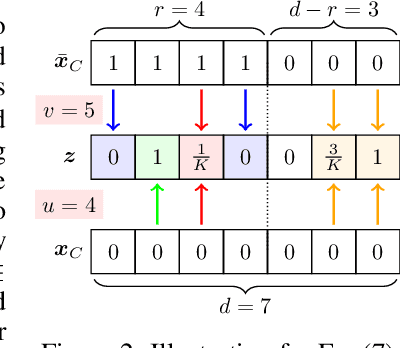

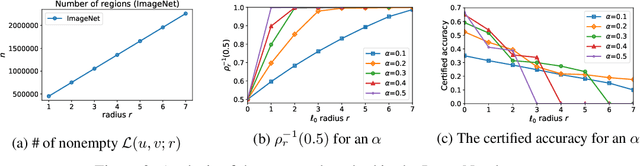
Strong theoretical guarantees of robustness can be given for ensembles of classifiers generated by input randomization. Specifically, an $\ell_2$ bounded adversary cannot alter the ensemble prediction generated by an isotropic Gaussian perturbation, where the radius for the adversary depends on both the variance of the perturbation as well as the ensemble margin at the point of interest. We build on and considerably expand this work across broad classes of perturbations. In particular, we offer guarantees and develop algorithms for the discrete case where the adversary is $\ell_0$ bounded. Moreover, we exemplify how the guarantees can be tightened with specific assumptions about the function class of the classifier such as a decision tree. We empirically illustrate these results with and without functional restrictions across image and molecule datasets.
Functional Transparency for Structured Data: a Game-Theoretic Approach
Feb 26, 2019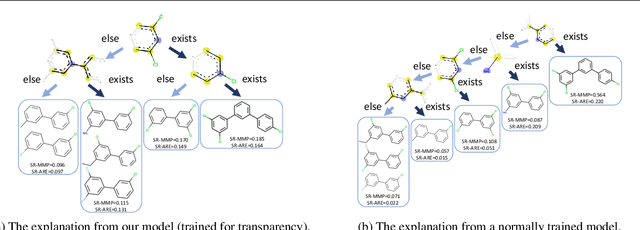
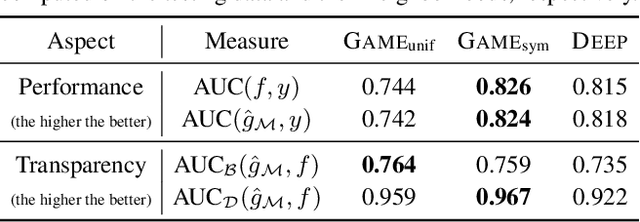
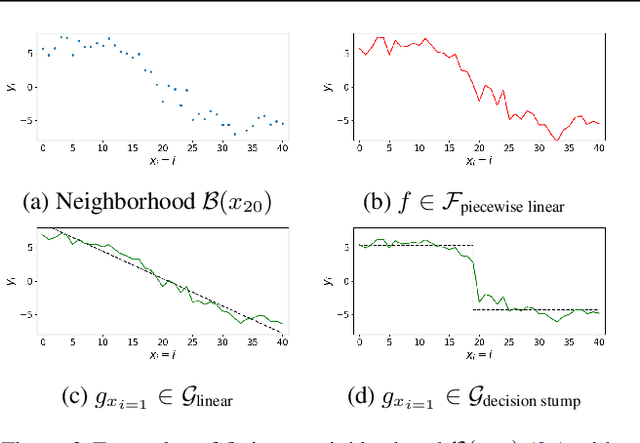
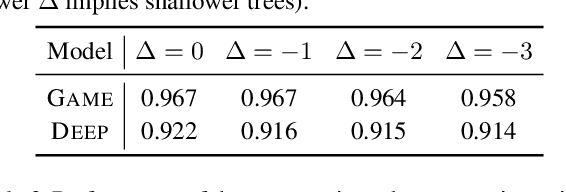
We provide a new approach to training neural models to exhibit transparency in a well-defined, functional manner. Our approach naturally operates over structured data and tailors the predictor, functionally, towards a chosen family of (local) witnesses. The estimation problem is setup as a co-operative game between an unrestricted predictor such as a neural network, and a set of witnesses chosen from the desired transparent family. The goal of the witnesses is to highlight, locally, how well the predictor conforms to the chosen family of functions, while the predictor is trained to minimize the highlighted discrepancy. We emphasize that the predictor remains globally powerful as it is only encouraged to agree locally with locally adapted witnesses. We analyze the effect of the proposed approach, provide example formulations in the context of deep graph and sequence models, and empirically illustrate the idea in chemical property prediction, temporal modeling, and molecule representation learning.