 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Stochastic Convex Optimization: Optimal Rates in $\ell_1$ Geometry
Mar 02, 2021
Stochastic convex optimization over an $\ell_1$-bounded domain is ubiquitous in machine learning applications such as LASSO but remains poorly understood when learning with differential privacy. We show that, up to logarithmic factors the optimal excess population loss of any $(\varepsilon,\delta)$-differentially private optimizer is $\sqrt{\log(d)/n} + \sqrt{d}/\varepsilon n.$ The upper bound is based on a new algorithm that combines the iterative localization approach of~\citet{FeldmanKoTa20} with a new analysis of private regularized mirror descent. It applies to $\ell_p$ bounded domains for $p\in [1,2]$ and queries at most $n^{3/2}$ gradients improving over the best previously known algorithm for the $\ell_2$ case which needs $n^2$ gradients. Further, we show that when the loss functions satisfy additional smoothness assumptions, the excess loss is upper bounded (up to logarithmic factors) by $\sqrt{\log(d)/n} + (\log(d)/\varepsilon n)^{2/3}.$ This bound is achieved by a new variance-reduced version of the Frank-Wolfe algorithm that requires just a single pass over the data. We also show that the lower bound in this case is the minimum of the two rates mentioned above.
Online Policy Gradient for Model Free Learning of Linear Quadratic Regulators with $\sqrt{T}$ Regret
Feb 25, 2021We consider the task of learning to control a linear dynamical system under fixed quadratic costs, known as the Linear Quadratic Regulator (LQR) problem. While model-free approaches are often favorable in practice, thus far only model-based methods, which rely on costly system identification, have been shown to achieve regret that scales with the optimal dependence on the time horizon T. We present the first model-free algorithm that achieves similar regret guarantees. Our method relies on an efficient policy gradient scheme, and a novel and tighter analysis of the cost of exploration in policy space in this setting.
Multiplicative Reweighting for Robust Neural Network Optimization
Feb 24, 2021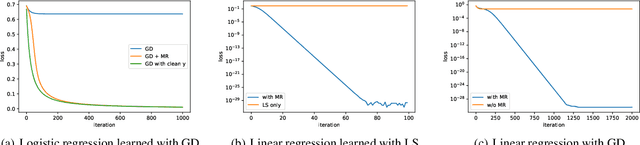
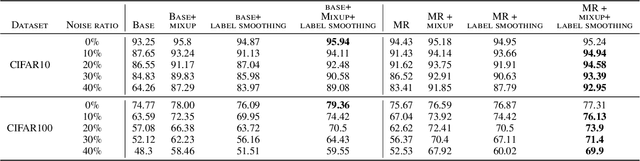
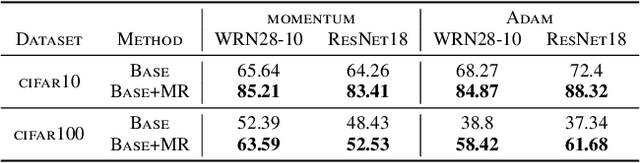
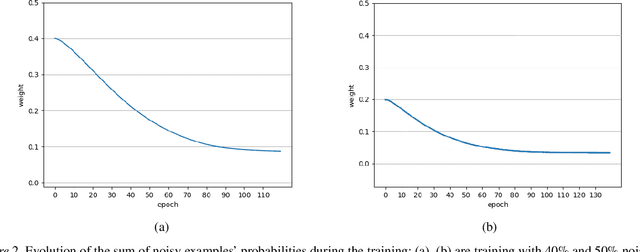
Deep neural networks are widespread due to their powerful performance. Yet, they suffer from degraded performance in the presence of noisy labels at train time or adversarial examples during inference. Inspired by the setting of learning with expert advice, where multiplicative weights (MW) updates were recently shown to be robust to moderate adversarial corruptions, we propose to use MW for reweighting examples during neural networks optimization. We establish the convergence of our method when used with gradient descent and demonstrate its advantage in two simple examples. We then validate empirically our findings by showing that MW improves network's accuracy in the presence of label noise on CIFAR-10, CIFAR-100 and Clothing1M, and that it leads to better robustness to adversarial attacks.
Lazy OCO: Online Convex Optimization on a Switching Budget
Feb 07, 2021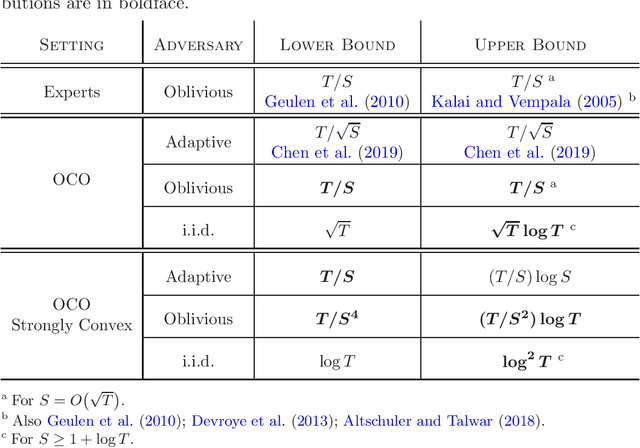
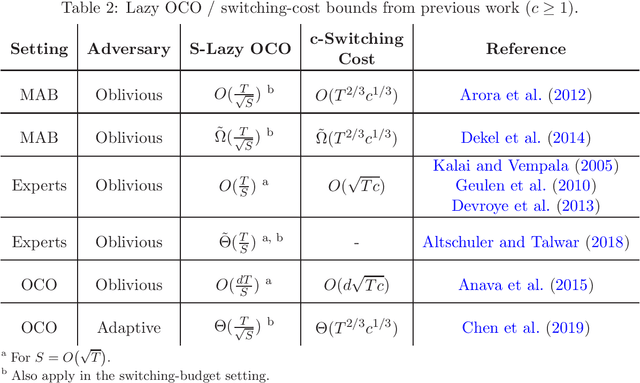
We study a variant of online convex optimization where the player is permitted to switch decisions at most $S$ times in expectation throughout $T$ rounds. Similar problems have been addressed in prior work for the discrete decision set setting, and more recently in the continuous setting but only with an adaptive adversary. In this work, we aim to fill the gap and present computationally efficient algorithms in the more prevalent oblivious setting, establishing a regret bound of $O(T/S)$ for general convex losses and $\widetilde O(T/S^2)$ for strongly convex losses. In addition, for stochastic i.i.d.~losses, we present a simple algorithm that performs $\log T$ switches with only a multiplicative $\log T$ factor overhead in its regret in both the general and strongly convex settings. Finally, we complement our algorithms with lower bounds that match our upper bounds in some of the cases we consider.
The Instability of Accelerated Gradient Descent
Feb 03, 2021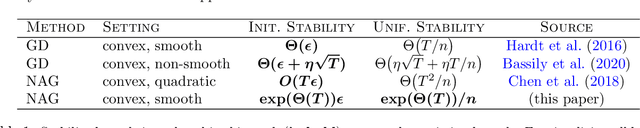
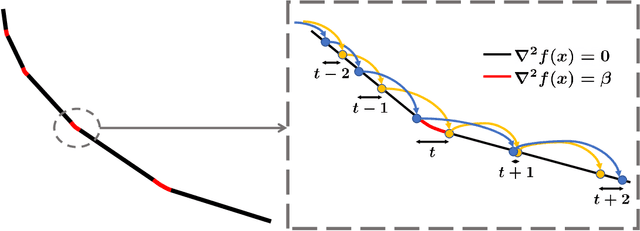
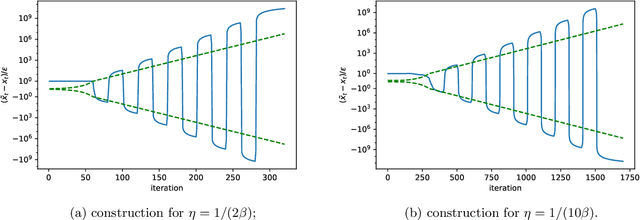
We study the algorithmic stability of Nesterov's accelerated gradient method. For convex quadratic objectives, \citet{chen2018stability} proved that the uniform stability of the method grows quadratically with the number of optimization steps, and conjectured that the same is true for the general convex and smooth case. We disprove this conjecture and show, for two notions of stability, that the stability of Nesterov's accelerated method in fact deteriorates \emph{exponentially fast} with the number of gradient steps. This stands in sharp contrast to the bounds in the quadratic case, but also to known results for non-accelerated gradient methods where stability typically grows linearly with the number of steps.
SGD Generalizes Better Than GD (And Regularization Doesn't Help)
Feb 01, 2021We give a new separation result between the generalization performance of stochastic gradient descent (SGD) and of full-batch gradient descent (GD) in the fundamental stochastic convex optimization model. While for SGD it is well-known that $O(1/\epsilon^2)$ iterations suffice for obtaining a solution with $\epsilon$ excess expected risk, we show that with the same number of steps GD may overfit and emit a solution with $\Omega(1)$ generalization error. Moreover, we show that in fact $\Omega(1/\epsilon^4)$ iterations are necessary for GD to match the generalization performance of SGD, which is also tight due to recent work by Bassily et al. (2020). We further discuss how regularizing the empirical risk minimized by GD essentially does not change the above result, and revisit the concepts of stability, implicit bias and the role of the learning algorithm in generalization.
Online Markov Decision Processes with Aggregate Bandit Feedback
Jan 31, 2021We study a novel variant of online finite-horizon Markov Decision Processes with adversarially changing loss functions and initially unknown dynamics. In each episode, the learner suffers the loss accumulated along the trajectory realized by the policy chosen for the episode, and observes aggregate bandit feedback: the trajectory is revealed along with the cumulative loss suffered, rather than the individual losses encountered along the trajectory. Our main result is a computationally efficient algorithm with $O(\sqrt{K})$ regret for this setting, where $K$ is the number of episodes. We establish this result via an efficient reduction to a novel bandit learning setting we call Distorted Linear Bandits (DLB), which is a variant of bandit linear optimization where actions chosen by the learner are adversarially distorted before they are committed. We then develop a computationally-efficient online algorithm for DLB for which we prove an $O(\sqrt{T})$ regret bound, where $T$ is the number of time steps. Our algorithm is based on online mirror descent with a self-concordant barrier regularization that employs a novel increasing learning rate schedule.
Adversarial Dueling Bandits
Oct 27, 2020We introduce the problem of regret minimization in Adversarial Dueling Bandits. As in classic Dueling Bandits, the learner has to repeatedly choose a pair of items and observe only a relative binary `win-loss' feedback for this pair, but here this feedback is generated from an arbitrary preference matrix, possibly chosen adversarially. Our main result is an algorithm whose $T$-round regret compared to the \emph{Borda-winner} from a set of $K$ items is $\tilde{O}(K^{1/3}T^{2/3})$, as well as a matching $\Omega(K^{1/3}T^{2/3})$ lower bound. We also prove a similar high probability regret bound. We further consider a simpler \emph{fixed-gap} adversarial setup, which bridges between two extreme preference feedback models for dueling bandits: stationary preferences and an arbitrary sequence of preferences. For the fixed-gap adversarial setup we give an $\smash{ \tilde{O}((K/\Delta^2)\log{T}) }$ regret algorithm, where $\Delta$ is the gap in Borda scores between the best item and all other items, and show a lower bound of $\Omega(K/\Delta^2)$ indicating that our dependence on the main problem parameters $K$ and $\Delta$ is tight (up to logarithmic factors).
Stochastic Optimization with Laggard Data Pipelines
Oct 26, 2020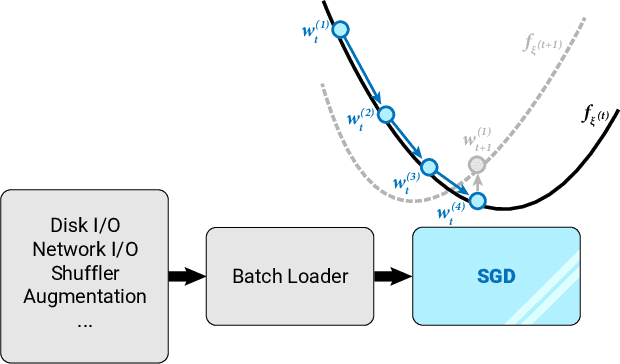
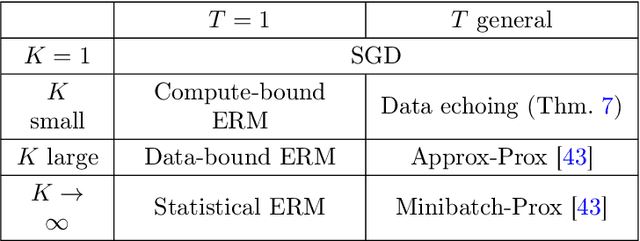
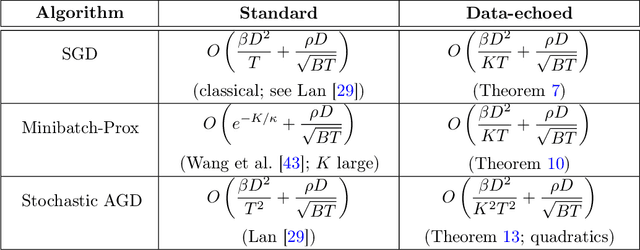
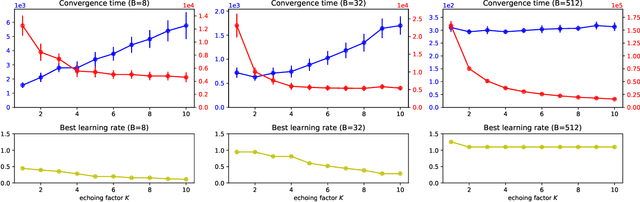
State-of-the-art optimization is steadily shifting towards massively parallel pipelines with extremely large batch sizes. As a consequence, CPU-bound preprocessing and disk/memory/network operations have emerged as new performance bottlenecks, as opposed to hardware-accelerated gradient computations. In this regime, a recently proposed approach is data echoing (Choi et al., 2019), which takes repeated gradient steps on the same batch while waiting for fresh data to arrive from upstream. We provide the first convergence analyses of "data-echoed" extensions of common optimization methods, showing that they exhibit provable improvements over their synchronous counterparts. Specifically, we show that in convex optimization with stochastic minibatches, data echoing affords speedups on the curvature-dominated part of the convergence rate, while maintaining the optimal statistical rate.
Holdout SGD: Byzantine Tolerant Federated Learning
Aug 11, 2020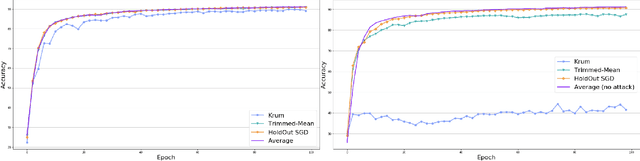
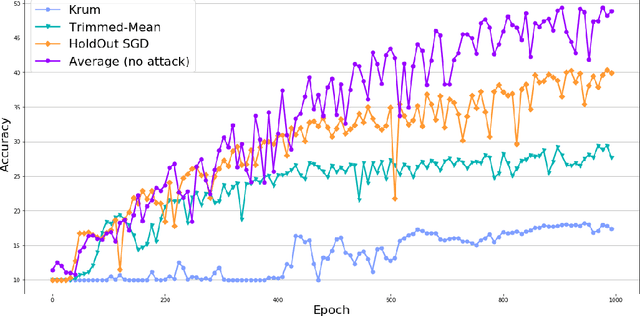
This work presents a new distributed Byzantine tolerant federated learning algorithm, HoldOut SGD, for Stochastic Gradient Descent (SGD) optimization. HoldOut SGD uses the well known machine learning technique of holdout estimation, in a distributed fashion, in order to select parameter updates that are likely to lead to models with low loss values. This makes it more effective at discarding Byzantine workers inputs than existing methods that eliminate outliers in the parameter-space of the learned model. HoldOut SGD first randomly selects a set of workers that use their private data in order to propose gradient updates. Next, a voting committee of workers is randomly selected, and each voter uses its private data as holdout data, in order to select the best proposals via a voting scheme. We propose two possible mechanisms for the coordination of workers in the distributed computation of HoldOut SGD. The first uses a truthful central server and corresponds to the typical setting of current federated learning. The second is fully distributed and requires no central server, paving the way to fully decentralized federated learning. The fully distributed version implements HoldOut SGD via ideas from the blockchain domain, and specifically the Algorand committee selection and consensus processes. We provide formal guarantees for the HoldOut SGD process in terms of its convergence to the optimal model, and its level of resilience to the fraction of Byzantine workers. Empirical evaluation shows that HoldOut SGD is Byzantine-resilient and efficiently converges to an effectual model for deep-learning tasks, as long as the total number of participating workers is large and the fraction of Byzantine workers is less than half (<1/3 for the fully distributed variant).