 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Best of Both Worlds Bounds for Bandits with Switching Costs
Jun 07, 2022We study best-of-both-worlds algorithms for bandits with switching cost, recently addressed by Rouyer, Seldin and Cesa-Bianchi, 2021. We introduce a surprisingly simple and effective algorithm that simultaneously achieves minimax optimal regret bound of $\mathcal{O}(T^{2/3})$ in the oblivious adversarial setting and a bound of $\mathcal{O}(\min\{\log (T)/\Delta^2,T^{2/3}\})$ in the stochastically-constrained regime, both with (unit) switching costs, where $\Delta$ is the gap between the arms. In the stochastically constrained case, our bound improves over previous results due to Rouyer et al., that achieved regret of $\mathcal{O}(T^{1/3}/\Delta)$. We accompany our results with a lower bound showing that, in general, $\tilde{\Omega}(\min\{1/\Delta^2,T^{2/3}\})$ regret is unavoidable in the stochastically-constrained case for algorithms with $\mathcal{O}(T^{2/3})$ worst-case regret.
Rate-Optimal Online Convex Optimization in Adaptive Linear Control
Jun 03, 2022We consider the problem of controlling an unknown linear dynamical system under adversarially changing convex costs and full feedback of both the state and cost function. We present the first computationally-efficient algorithm that attains an optimal $\smash{\sqrt{T}}$-regret rate compared to the best stabilizing linear controller in hindsight, while avoiding stringent assumptions on the costs such as strong convexity. Our approach is based on a careful design of non-convex lower confidence bounds for the online costs, and uses a novel technique for computationally-efficient regret minimization of these bounds that leverages their particular non-convex structure.
Efficient Online Linear Control with Stochastic Convex Costs and Unknown Dynamics
Mar 02, 2022We consider the problem of controlling an unknown linear dynamical system under a stochastic convex cost and full feedback of both the state and cost function. We present a computationally efficient algorithm that attains an optimal $\sqrt{T}$ regret-rate against the best stabilizing linear controller. In contrast to previous work, our algorithm is based on the Optimism in the Face of Uncertainty paradigm. This results in a substantially improved computational complexity and a simpler analysis.
Benign Underfitting of Stochastic Gradient Descent
Mar 01, 2022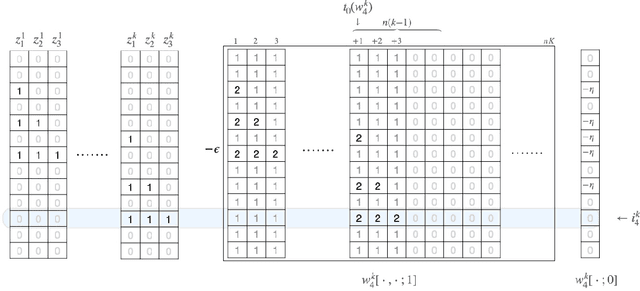
We study to what extent may stochastic gradient descent (SGD) be understood as a "conventional" learning rule that achieves generalization performance by obtaining a good fit to training data. We consider the fundamental stochastic convex optimization framework, where (one pass, without-replacement) SGD is classically known to minimize the population risk at rate $O(1/\sqrt n)$, and prove that, surprisingly, there exist problem instances where the SGD solution exhibits both empirical risk and generalization gap of $\Omega(1)$. Consequently, it turns out that SGD is not algorithmically stable in any sense, and its generalization ability cannot be explained by uniform convergence or any other currently known generalization bound technique for that matter (other than that of its classical analysis). We then continue to analyze the closely related with-replacement SGD, for which we show that an analogous phenomenon does not occur and prove that its population risk does in fact converge at the optimal rate. Finally, we interpret our main results in the context of without-replacement SGD for finite-sum convex optimization problems, and derive upper and lower bounds for the multi-epoch regime that significantly improve upon previously known results.
Stability vs Implicit Bias of Gradient Methods on Separable Data and Beyond
Feb 27, 2022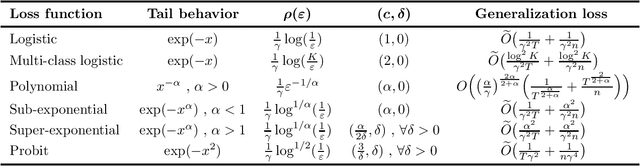
An influential line of recent work has focused on the generalization properties of unregularized gradient-based learning procedures applied to separable linear classification with exponentially-tailed loss functions. The ability of such methods to generalize well has been attributed to the their implicit bias towards large margin predictors, both asymptotically as well as in finite time. We give an additional unified explanation for this generalization and relate it to two simple properties of the optimization objective, that we refer to as realizability and self-boundedness. We introduce a general setting of unconstrained stochastic convex optimization with these properties, and analyze generalization of gradient methods through the lens of algorithmic stability. In this broader setting, we obtain sharp stability bounds for gradient descent and stochastic gradient descent which apply even for a very large number of gradient steps, and use them to derive general generalization bounds for these algorithms. Finally, as direct applications of the general bounds, we return to the setting of linear classification with separable data and establish several novel test loss and test accuracy bounds for gradient descent and stochastic gradient descent for a variety of loss functions with different tail decay rates. In some of these case, our bounds significantly improve upon the existing generalization error bounds in the literature.
Best-of-All-Worlds Bounds for Online Learning with Feedback Graphs
Jul 20, 2021
We study the online learning with feedback graphs framework introduced by Mannor and Shamir (2011), in which the feedback received by the online learner is specified by a graph $G$ over the available actions. We develop an algorithm that simultaneously achieves regret bounds of the form: $\smash{\mathcal{O}(\sqrt{\theta(G) T})}$ with adversarial losses; $\mathcal{O}(\theta(G)\operatorname{polylog}{T})$ with stochastic losses; and $\mathcal{O}(\theta(G)\operatorname{polylog}{T} + \smash{\sqrt{\theta(G) C})}$ with stochastic losses subject to $C$ adversarial corruptions. Here, $\theta(G)$ is the clique covering number of the graph $G$. Our algorithm is an instantiation of Follow-the-Regularized-Leader with a novel regularization that can be seen as a product of a Tsallis entropy component (inspired by Zimmert and Seldin (2019)) and a Shannon entropy component (analyzed in the corrupted stochastic case by Amir et al. (2020)), thus subtly interpolating between the two forms of entropies. One of our key technical contributions is in establishing the convexity of this regularizer and controlling its inverse Hessian, despite its complex product structure.
Never Go Full Batch (in Stochastic Convex Optimization)
Jun 29, 2021We study the generalization performance of $\text{full-batch}$ optimization algorithms for stochastic convex optimization: these are first-order methods that only access the exact gradient of the empirical risk (rather than gradients with respect to individual data points), that include a wide range of algorithms such as gradient descent, mirror descent, and their regularized and/or accelerated variants. We provide a new separation result showing that, while algorithms such as stochastic gradient descent can generalize and optimize the population risk to within $\epsilon$ after $O(1/\epsilon^2)$ iterations, full-batch methods either need at least $\Omega(1/\epsilon^4)$ iterations or exhibit a dimension-dependent sample complexity.
Optimal Rates for Random Order Online Optimization
Jun 29, 2021We study online convex optimization in the random order model, recently proposed by \citet{garber2020online}, where the loss functions may be chosen by an adversary, but are then presented to the online algorithm in a uniformly random order. Focusing on the scenario where the cumulative loss function is (strongly) convex, yet individual loss functions are smooth but might be non-convex, we give algorithms that achieve the optimal bounds and significantly outperform the results of \citet{garber2020online}, completely removing the dimension dependence and improving their scaling with respect to the strong convexity parameter. Our analysis relies on novel connections between algorithmic stability and generalization for sampling without-replacement analogous to those studied in the with-replacement i.i.d.~setting, as well as on a refined average stability analysis of stochastic gradient descent.
Asynchronous Stochastic Optimization Robust to Arbitrary Delays
Jun 22, 2021
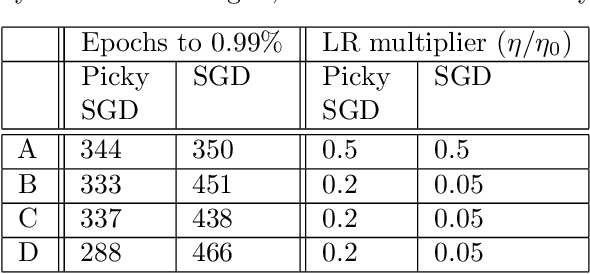
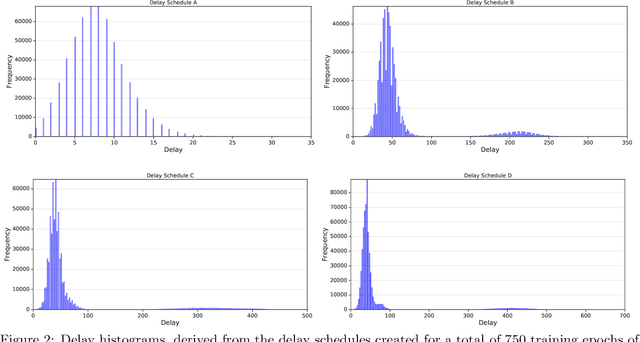
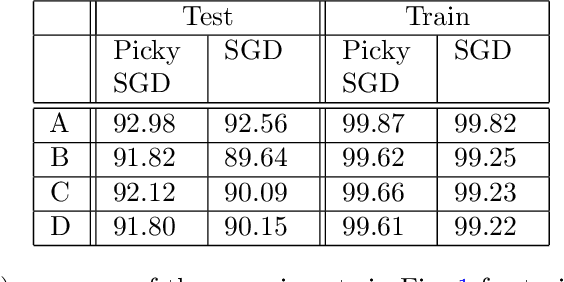
We consider stochastic optimization with delayed gradients where, at each time step $t$, the algorithm makes an update using a stale stochastic gradient from step $t - d_t$ for some arbitrary delay $d_t$. This setting abstracts asynchronous distributed optimization where a central server receives gradient updates computed by worker machines. These machines can experience computation and communication loads that might vary significantly over time. In the general non-convex smooth optimization setting, we give a simple and efficient algorithm that requires $O( \sigma^2/\epsilon^4 + \tau/\epsilon^2 )$ steps for finding an $\epsilon$-stationary point $x$, where $\tau$ is the \emph{average} delay $\smash{\frac{1}{T}\sum_{t=1}^T d_t}$ and $\sigma^2$ is the variance of the stochastic gradients. This improves over previous work, which showed that stochastic gradient decent achieves the same rate but with respect to the \emph{maximal} delay $\max_{t} d_t$, that can be significantly larger than the average delay especially in heterogeneous distributed systems. Our experiments demonstrate the efficacy and robustness of our algorithm in cases where the delay distribution is skewed or heavy-tailed.
Stochastic Multi-Armed Bandits with Unrestricted Delay Distributions
Jun 04, 2021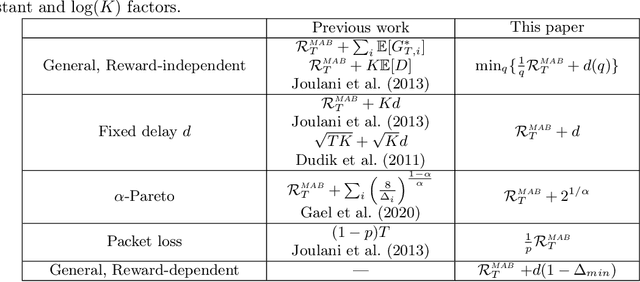
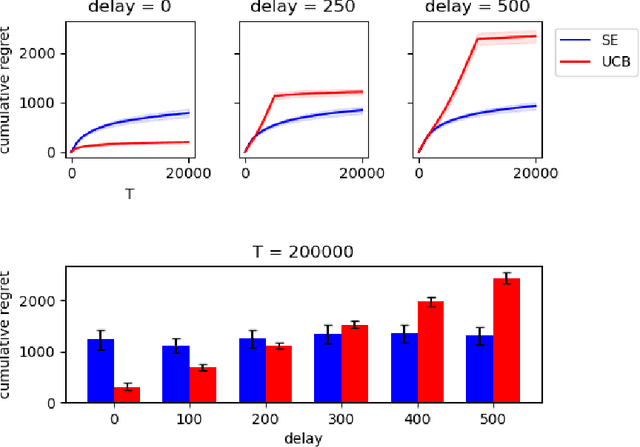
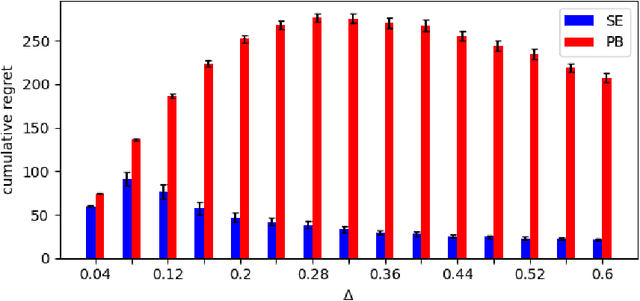
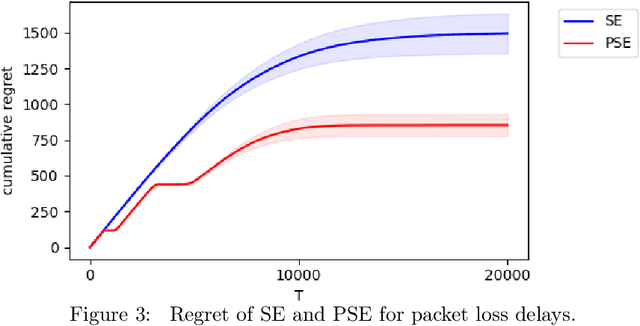
We study the stochastic Multi-Armed Bandit (MAB) problem with random delays in the feedback received by the algorithm. We consider two settings: the reward-dependent delay setting, where realized delays may depend on the stochastic rewards, and the reward-independent delay setting. Our main contribution is algorithms that achieve near-optimal regret in each of the settings, with an additional additive dependence on the quantiles of the delay distribution. Our results do not make any assumptions on the delay distributions: in particular, we do not assume they come from any parametric family of distributions and allow for unbounded support and expectation; we further allow for infinite delays where the algorithm might occasionally not observe any feedback.