 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocally Optimal Descent for Dynamic Stepsize Scheduling
Nov 23, 2023



We introduce a novel dynamic learning-rate scheduling scheme grounded in theory with the goal of simplifying the manual and time-consuming tuning of schedules in practice. Our approach is based on estimating the locally-optimal stepsize, guaranteeing maximal descent in the direction of the stochastic gradient of the current step. We first establish theoretical convergence bounds for our method within the context of smooth non-convex stochastic optimization, matching state-of-the-art bounds while only assuming knowledge of the smoothness parameter. We then present a practical implementation of our algorithm and conduct systematic experiments across diverse datasets and optimization algorithms, comparing our scheme with existing state-of-the-art learning-rate schedulers. Our findings indicate that our method needs minimal tuning when compared to existing approaches, removing the need for auxiliary manual schedules and warm-up phases and achieving comparable performance with drastically reduced parameter tuning.
Rate-Optimal Policy Optimization for Linear Markov Decision Processes
Aug 28, 2023We study regret minimization in online episodic linear Markov Decision Processes, and obtain rate-optimal $\widetilde O (\sqrt K)$ regret where $K$ denotes the number of episodes. Our work is the first to establish the optimal (w.r.t.~$K$) rate of convergence in the stochastic setting with bandit feedback using a policy optimization based approach, and the first to establish the optimal (w.r.t.~$K$) rate in the adversarial setup with full information feedback, for which no algorithm with an optimal rate guarantee is currently known.
Tight Risk Bounds for Gradient Descent on Separable Data
Mar 02, 2023We study the generalization properties of unregularized gradient methods applied to separable linear classification -- a setting that has received considerable attention since the pioneering work of Soudry et al. (2018). We establish tight upper and lower (population) risk bounds for gradient descent in this setting, for any smooth loss function, expressed in terms of its tail decay rate. Our bounds take the form $\Theta(r_{\ell,T}^2 / \gamma^2 T + r_{\ell,T}^2 / \gamma^2 n)$, where $T$ is the number of gradient steps, $n$ is size of the training set, $\gamma$ is the data margin, and $r_{\ell,T}$ is a complexity term that depends on the (tail decay rate) of the loss function (and on $T$). Our upper bound matches the best known upper bounds due to Shamir (2021); Schliserman and Koren (2022), while extending their applicability to virtually any smooth loss function and relaxing technical assumptions they impose. Our risk lower bounds are the first in this context and establish the tightness of our upper bounds for any given tail decay rate and in all parameter regimes. The proof technique used to show these results is also markedly simpler compared to previous work, and is straightforward to extend to other gradient methods; we illustrate this by providing analogous results for Stochastic Gradient Descent.
Near-Optimal Algorithms for Private Online Optimization in the Realizable Regime
Feb 27, 2023
We consider online learning problems in the realizable setting, where there is a zero-loss solution, and propose new Differentially Private (DP) algorithms that obtain near-optimal regret bounds. For the problem of online prediction from experts, we design new algorithms that obtain near-optimal regret ${O} \big( \varepsilon^{-1} \log^{1.5}{d} \big)$ where $d$ is the number of experts. This significantly improves over the best existing regret bounds for the DP non-realizable setting which are ${O} \big( \varepsilon^{-1} \min\big\{d, T^{1/3}\log d\big\} \big)$. We also develop an adaptive algorithm for the small-loss setting with regret $O(L^\star\log d + \varepsilon^{-1} \log^{1.5}{d})$ where $L^\star$ is the total loss of the best expert. Additionally, we consider DP online convex optimization in the realizable setting and propose an algorithm with near-optimal regret $O \big(\varepsilon^{-1} d^{1.5} \big)$, as well as an algorithm for the smooth case with regret $O \big( \varepsilon^{-2/3} (dT)^{1/3} \big)$, both significantly improving over existing bounds in the non-realizable regime.
SGD with AdaGrad Stepsizes: Full Adaptivity with High Probability to Unknown Parameters, Unbounded Gradients and Affine Variance
Feb 17, 2023We study Stochastic Gradient Descent with AdaGrad stepsizes: a popular adaptive (self-tuning) method for first-order stochastic optimization. Despite being well studied, existing analyses of this method suffer from various shortcomings: they either assume some knowledge of the problem parameters, impose strong global Lipschitz conditions, or fail to give bounds that hold with high probability. We provide a comprehensive analysis of this basic method without any of these limitations, in both the convex and non-convex (smooth) cases, that additionally supports a general ``affine variance'' noise model and provides sharp rates of convergence in both the low-noise and high-noise~regimes.
Improved Regret for Efficient Online Reinforcement Learning with Linear Function Approximation
Jan 30, 2023We study reinforcement learning with linear function approximation and adversarially changing cost functions, a setup that has mostly been considered under simplifying assumptions such as full information feedback or exploratory conditions.We present a computationally efficient policy optimization algorithm for the challenging general setting of unknown dynamics and bandit feedback, featuring a combination of mirror-descent and least squares policy evaluation in an auxiliary MDP used to compute exploration bonuses.Our algorithm obtains an $\widetilde O(K^{6/7})$ regret bound, improving significantly over previous state-of-the-art of $\widetilde O (K^{14/15})$ in this setting. In addition, we present a version of the same algorithm under the assumption a simulator of the environment is available to the learner (but otherwise no exploratory assumptions are made), and prove it obtains state-of-the-art regret of $\widetilde O (K^{2/3})$.
Private Online Prediction from Experts: Separations and Faster Rates
Oct 24, 2022Online prediction from experts is a fundamental problem in machine learning and several works have studied this problem under privacy constraints. We propose and analyze new algorithms for this problem that improve over the regret bounds of the best existing algorithms for non-adaptive adversaries. For approximate differential privacy, our algorithms achieve regret bounds of $\tilde{O}(\sqrt{T \log d} + \log d/\varepsilon)$ for the stochastic setting and $\tilde O(\sqrt{T \log d} + T^{1/3} \log d/\varepsilon)$ for oblivious adversaries (where $d$ is the number of experts). For pure DP, our algorithms are the first to obtain sub-linear regret for oblivious adversaries in the high-dimensional regime $d \ge T$. Moreover, we prove new lower bounds for adaptive adversaries. Our results imply that unlike the non-private setting, there is a strong separation between the optimal regret for adaptive and non-adaptive adversaries for this problem. Our lower bounds also show a separation between pure and approximate differential privacy for adaptive adversaries where the latter is necessary to achieve the non-private $O(\sqrt{T})$ regret.
Dueling Convex Optimization with General Preferences
Sep 27, 2022We address the problem of \emph{convex optimization with dueling feedback}, where the goal is to minimize a convex function given a weaker form of \emph{dueling} feedback. Each query consists of two points and the dueling feedback returns a (noisy) single-bit binary comparison of the function values of the two queried points. The translation of the function values to the single comparison bit is through a \emph{transfer function}. This problem has been addressed previously for some restricted classes of transfer functions, but here we consider a very general transfer function class which includes all functions that can be approximated by a finite polynomial with a minimal degree $p$. Our main contribution is an efficient algorithm with convergence rate of $\smash{\widetilde O}(\epsilon^{-4p})$ for a smooth convex objective function, and an optimal rate of $\smash{\widetilde O}(\epsilon^{-2p})$ when the objective is smooth and strongly convex.
Regret Minimization and Convergence to Equilibria in General-sum Markov Games
Aug 08, 2022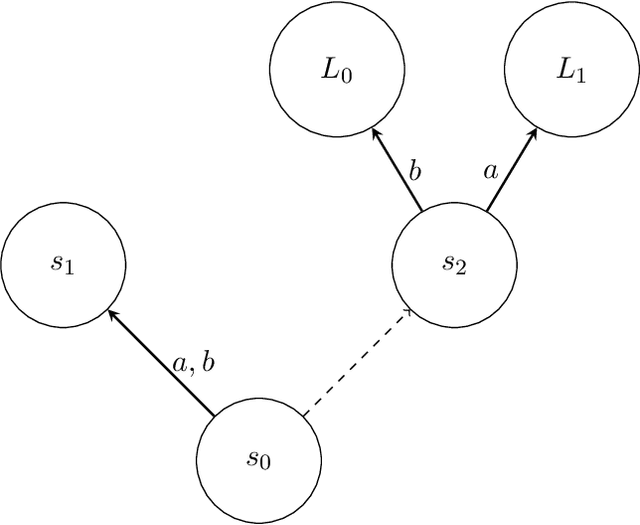
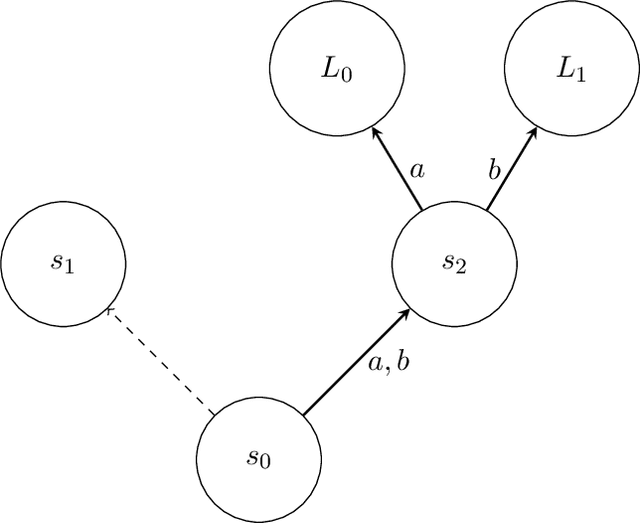
An abundance of recent impossibility results establish that regret minimization in Markov games with adversarial opponents is both statistically and computationally intractable. Nevertheless, none of these results preclude the possibility of regret minimization under the assumption that all parties adopt the same learning procedure. In this work, we present the first (to our knowledge) algorithm for learning in general-sum Markov games that provides sublinear regret guarantees when executed by all agents. The bounds we obtain are for swap regret, and thus, along the way, imply convergence to a correlated equilibrium. Our algorithm is decentralized, computationally efficient, and does not require any communication between agents. Our key observation is that online learning via policy optimization in Markov games essentially reduces to a form of weighted regret minimization, with unknown weights determined by the path length of the agents' policy sequence. Consequently, controlling the path length leads to weighted regret objectives for which sufficiently adaptive algorithms provide sublinear regret guarantees.
Uniform Stability for First-Order Empirical Risk Minimization
Jul 17, 2022We consider the problem of designing uniformly stable first-order optimization algorithms for empirical risk minimization. Uniform stability is often used to obtain generalization error bounds for optimization algorithms, and we are interested in a general approach to achieve it. For Euclidean geometry, we suggest a black-box conversion which given a smooth optimization algorithm, produces a uniformly stable version of the algorithm while maintaining its convergence rate up to logarithmic factors. Using this reduction we obtain a (nearly) optimal algorithm for smooth optimization with convergence rate $\widetilde{O}(1/T^2)$ and uniform stability $O(T^2/n)$, resolving an open problem of Chen et al. (2018); Attia and Koren (2021). For more general geometries, we develop a variant of Mirror Descent for smooth optimization with convergence rate $\widetilde{O}(1/T)$ and uniform stability $O(T/n)$, leaving open the question of devising a general conversion method as in the Euclidean case.