 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSALLIE: Safeguarding Against Latent Language & Image Exploits
Apr 06, 2026Large Language Models (LLMs) and Vision-Language Models (VLMs) remain highly vulnerable to textual and visual jailbreaks, as well as prompt injections (arXiv:2307.15043, Greshake et al., 2023, arXiv:2306.13213). Existing defenses often degrade performance through complex input transformations or treat multimodal threats as isolated problems (arXiv:2309.00614, arXiv:2310.03684, Zhang et al., 2025). To address the critical gap for a unified, modal-agnostic defense that mitigates both textual and visual threats simultaneously without degrading performance or requiring architectural modifications, we introduce SALLIE (Safeguarding Against Latent Language & Image Exploits), a lightweight runtime detection framework rooted in mechanistic interpretability (Lindsey et al., 2025, Ameisen et al., 2025). By integrating seamlessly into standard token-level fusion pipelines (arXiv:2306.13549), SALLIE extracts robust signals directly from the model's internal activations. At inference, SALLIE defends via a three-stage architecture: (1) extracting internal residual stream activations, (2) calculating layer-wise maliciousness scores using a K-Nearest Neighbors (k-NN) classifier, and (3) aggregating these predictions via a layer ensemble module. We evaluate SALLIE on compact, open-source architectures - Phi-3.5-vision-instruct (arXiv:2404.14219), SmolVLM2-2.2B-Instruct (arXiv:2504.05299), and gemma-3-4b-it (arXiv:2503.19786) - prioritized for practical inference times and real-world deployment costs. Our comprehensive evaluation pipeline spans over ten datasets and more than five strong baseline methods from the literature, and SALLIE consistently outperforms these baselines across a wide range of experimental settings.
Self-Improving Customer Review Response Generation Based on LLMs
May 06, 2024



Previous studies have demonstrated that proactive interaction with user reviews has a positive impact on the perception of app users and encourages them to submit revised ratings. Nevertheless, developers encounter challenges in managing a high volume of reviews, particularly in the case of popular apps with a substantial influx of daily reviews. Consequently, there is a demand for automated solutions aimed at streamlining the process of responding to user reviews. To address this, we have developed a new system for generating automatic responses by leveraging user-contributed documents with the help of retrieval-augmented generation (RAG) and advanced Large Language Models (LLMs). Our solution, named SCRABLE, represents an adaptive customer review response automation that enhances itself with self-optimizing prompts and a judging mechanism based on LLMs. Additionally, we introduce an automatic scoring mechanism that mimics the role of a human evaluator to assess the quality of responses generated in customer review domains. Extensive experiments and analyses conducted on real-world datasets reveal that our method is effective in producing high-quality responses, yielding improvement of more than 8.5% compared to the baseline. Further validation through manual examination of the generated responses underscores the efficacy our proposed system.
Better Best of Both Worlds Bounds for Bandits with Switching Costs
Jun 07, 2022We study best-of-both-worlds algorithms for bandits with switching cost, recently addressed by Rouyer, Seldin and Cesa-Bianchi, 2021. We introduce a surprisingly simple and effective algorithm that simultaneously achieves minimax optimal regret bound of $\mathcal{O}(T^{2/3})$ in the oblivious adversarial setting and a bound of $\mathcal{O}(\min\{\log (T)/\Delta^2,T^{2/3}\})$ in the stochastically-constrained regime, both with (unit) switching costs, where $\Delta$ is the gap between the arms. In the stochastically constrained case, our bound improves over previous results due to Rouyer et al., that achieved regret of $\mathcal{O}(T^{1/3}/\Delta)$. We accompany our results with a lower bound showing that, in general, $\tilde{\Omega}(\min\{1/\Delta^2,T^{2/3}\})$ regret is unavoidable in the stochastically-constrained case for algorithms with $\mathcal{O}(T^{2/3})$ worst-case regret.
FLEX: Parameter-free Multi-view 3D Human Motion Reconstruction
May 05, 2021
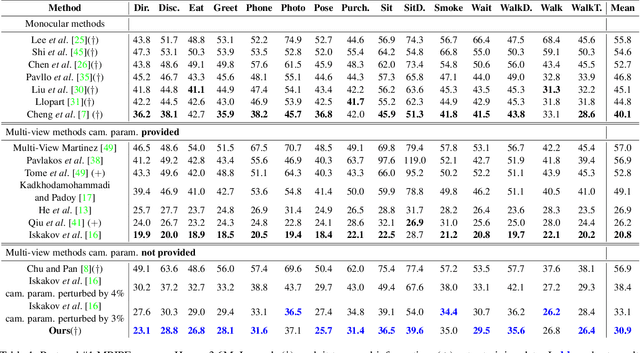
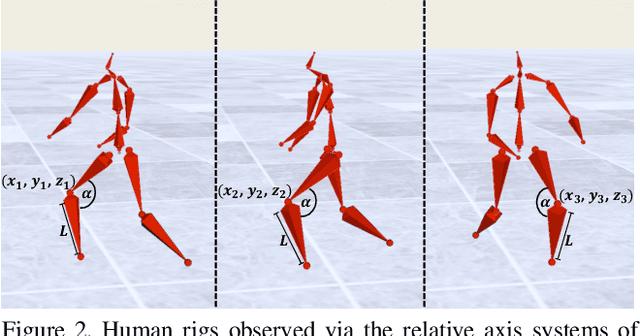
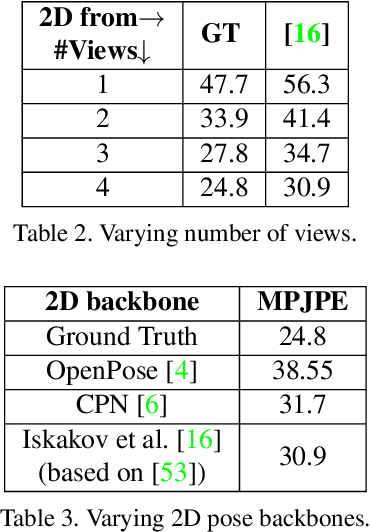
The increasing availability of video recordings made by multiple cameras has offered new means for mitigating occlusion and depth ambiguities in pose and motion reconstruction methods. Yet, multi-view algorithms strongly depend on camera parameters, in particular, the relative positions among the cameras. Such dependency becomes a hurdle once shifting to dynamic capture in uncontrolled settings. We introduce FLEX (Free muLti-view rEconstruXion), an end-to-end parameter-free multi-view model. FLEX is parameter-free in the sense that it does not require any camera parameters, neither intrinsic nor extrinsic. Our key idea is that the 3D angles between skeletal parts, as well as bone lengths, are invariant to the camera position. Hence, learning 3D rotations and bone lengths rather than locations allows predicting common values for all camera views. Our network takes multiple video streams, learns fused deep features through a novel multi-view fusion layer, and reconstructs a single consistent skeleton with temporally coherent joint rotations. We demonstrate quantitative and qualitative results on the Human3.6M and KTH Multi-view Football II datasets. We compare our model to state-of-the-art methods that are not parameter-free and show that in the absence of camera parameters, we outperform them by a large margin while obtaining comparable results when camera parameters are available. Code, trained models, video demonstration, and additional materials will be available on our project page.