 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Prototype Evolution: Learning Online from Non-Stationary Data Streams
Sep 02, 2020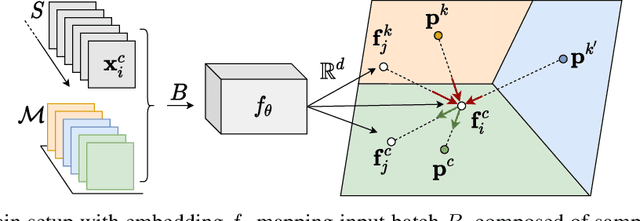
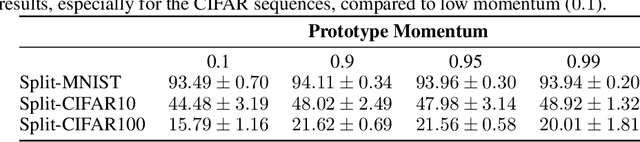

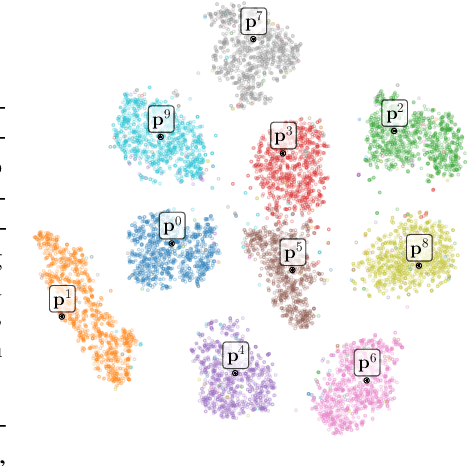
As learning from non-stationary streams of data has been proven a challenging endeavour, current continual learners often strongly relax the problem, assuming balanced datasets, unlimited processing of data stream subsets, and additional availability of task information, sometimes even during inference. In contrast, our continual learner processes the data streams in an online fashion, without additional task-information, and shows solid robustness to imbalanced data streams resembling a real-world setting. Defying such challenging settings is achieved by aggregating prototypes and nearest-neighbour based classification in a shared latent space, where a Continual Prototype Evolution (CoPE) enables learning and prediction at any point in time. As the embedding network continually changes, prototypes inevitably become obsolete, which we prevent by replay of exemplars from memory. We obtain state-of-the-art performance by a significant margin on five benchmarks, including two highly unbalanced data streams.
What My Motion tells me about Your Pose: Self-Supervised Fine-Tuning of Observed Vehicle Orientation Angle
Jul 29, 2020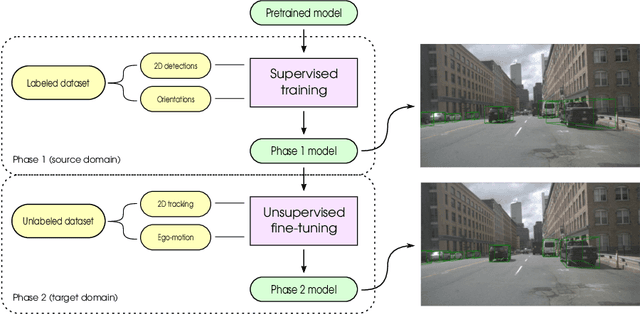
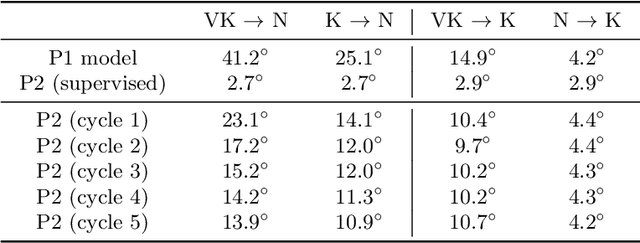
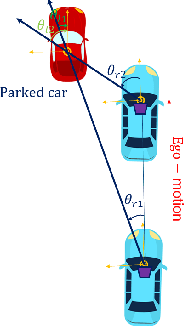
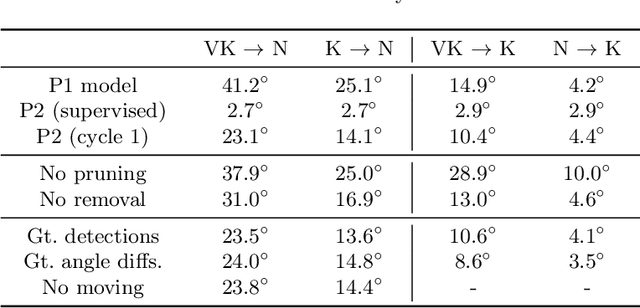
The determination of the relative 6 Degree of Freedom (DoF) pose of vehicles around the ego-vehicle from monocular cameras is an important aspect of the perception problem for Autonomous Vehicles (AVs) and Driver Assist Technology (DAT). Current deep learning techniques used for tackling this problem are data hungry, driving the need for unsupervised or self-supervised methods. In this paper, we consider the domain adaptation task of fine-tuning a vehicle orientation estimator on a new domain without labels. By leveraging the ego-motion consistencies obtained from a monocular SLAM method, we show that our self-supervised fine-tuning scheme consistently improves the accuracy of the resulting network. More specifically, when transitioning from Virtual Kitti to nuScenes, up to 70% of the performance is recovered compared to the 100% of a supervised method. Our self-supervised method hence allows us to safely transfer vehicle orientation estimators to new domains without requiring expensive new labels.
Attend and Segment: Attention Guided Active Semantic Segmentation
Jul 22, 2020
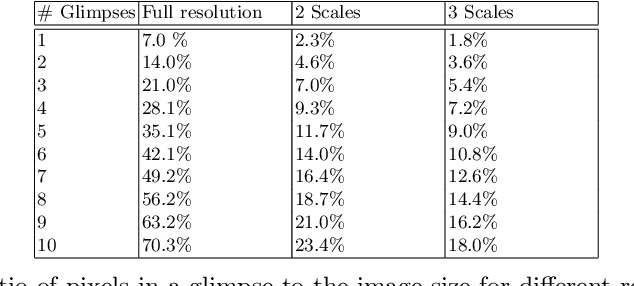
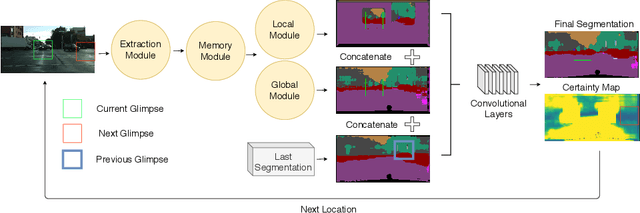
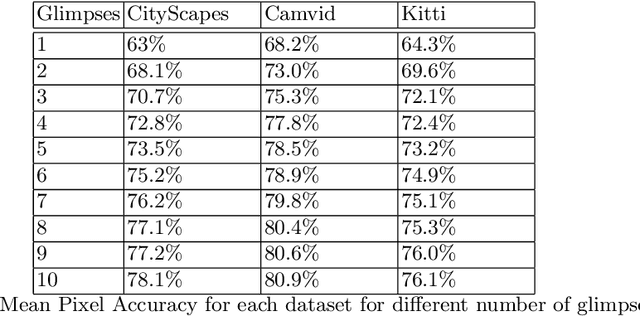
In a dynamic environment, an agent with a limited field of view/resource cannot fully observe the scene before attempting to parse it. The deployment of common semantic segmentation architectures is not feasible in such settings. In this paper we propose a method to gradually segment a scene given a sequence of partial observations. The main idea is to refine an agent's understanding of the environment by attending the areas it is most uncertain about. Our method includes a self-supervised attention mechanism and a specialized architecture to maintain and exploit spatial memory maps for filling-in the unseen areas in the environment. The agent can select and attend an area while relying on the cues coming from the visited areas to hallucinate the other parts. We reach a mean pixel-wise accuracy of 78.1%, 80.9% and 76.5% on CityScapes, CamVid, and Kitti datasets by processing only 18% of the image pixels (10 retina-like glimpses). We perform an ablation study on the number of glimpses, input image size and effectiveness of retina-like glimpses. We compare our method to several baselines and show that the optimal results are achieved by having access to a very low resolution view of the scene at the first timestep.
MIX'EM: Unsupervised Image Classification using a Mixture of Embeddings
Jul 18, 2020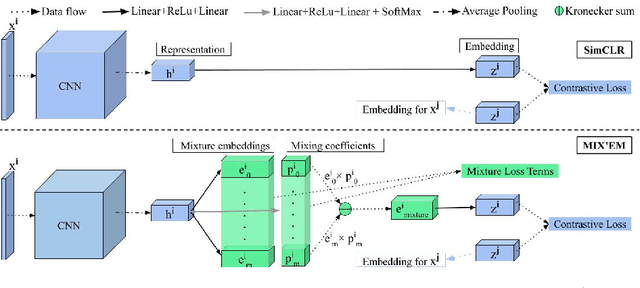
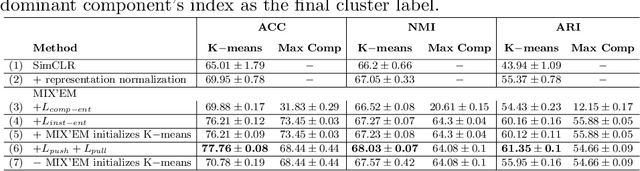
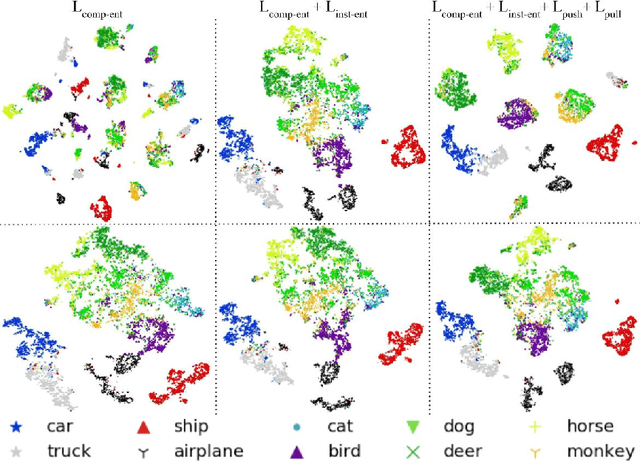
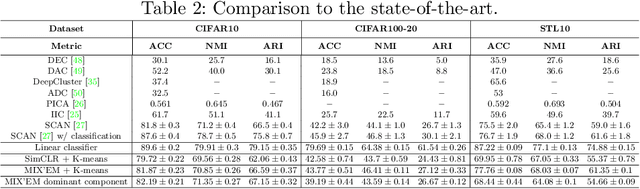
We present MIX'EM, a novel solution for unsupervised image classification. Our model generates representations that by themselves are sufficient to drive a general-purpose clustering method to deliver high-quality classification without supervision. MIX'EM integrates an internal mixture of embeddings module into the contrastive visual representation learning framework to disentangle the representation space at the category level. It generates a set of embeddings from a visual representation and mixes them to construct the contrastive loss input. Parallel to the contrastive loss, we introduce three techniques to train MIX'EM and avoid a degenerate solution; (i) we maximize entropy across mixture components to diversify them, and (ii) minimize component entropy conditioned on instances to enforce a clustered embedding space. Applying (i) and (ii) lead to the emergence of semantic categories through the mixture coefficients, making it possible to (iii) apply an associative embedding loss to enforce semantic separability directly. Subsequently, we run K-means on the representations to acquire semantic classification, which outperforms the state-of-the-art by a large margin. We conduct extensive experiments and analyses on STL10, CIFAR10, and CIFAR100-20 datasets, achieving 78\%, 82\%, and 44\% accuracy, respectively. Essential to robust high accuracy is using MIX'EM to initialize K-means. Finally, we report impressively high accuracy baselines (70\% on STL10) achieved solely by applying K-means to the "normalized" representations learned using the contrastive loss.
Automatic Recall Machines: Internal Replay, Continual Learning and the Brain
Jul 15, 2020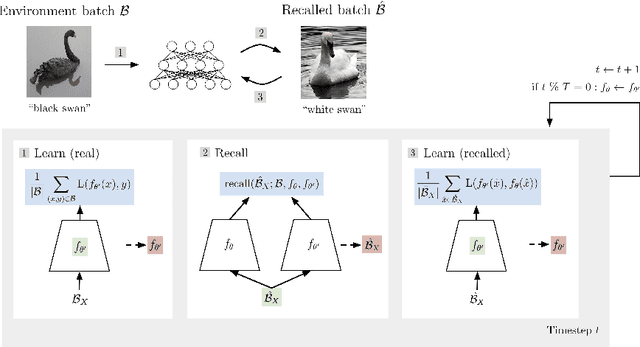
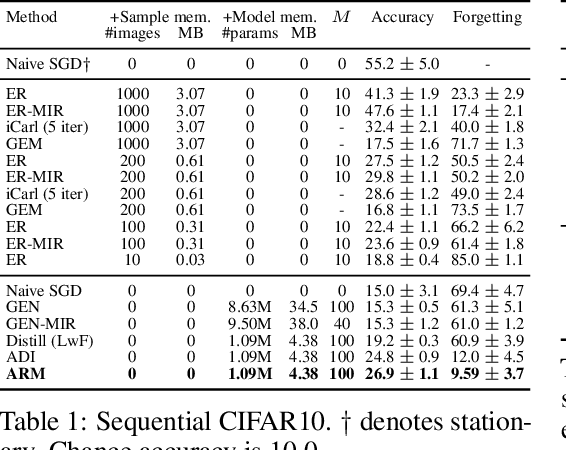

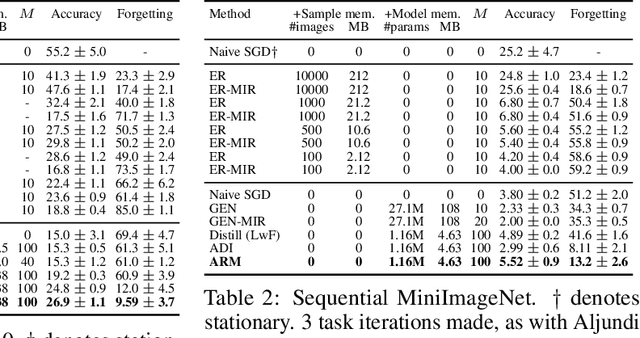
Replay in neural networks involves training on sequential data with memorized samples, which counteracts forgetting of previous behavior caused by non-stationarity. We present a method where these auxiliary samples are generated on the fly, given only the model that is being trained for the assessed objective, without extraneous buffers or generator networks. Instead the implicit memory of learned samples within the assessed model itself is exploited. Furthermore, whereas existing work focuses on reinforcing the full seen data distribution, we show that optimizing for not forgetting calls for the generation of samples that are specialized to each real training batch, which is more efficient and scalable. We consider high-level parallels with the brain, notably the use of a single model for inference and recall, the dependency of recalled samples on the current environment batch, top-down modulation of activations and learning, abstract recall, and the dependency between the degree to which a task is learned and the degree to which it is recalled. These characteristics emerge naturally from the method without being controlled for.
Unsupervised Model Personalization while Preserving Privacy and Scalability: An Open Problem
Mar 30, 2020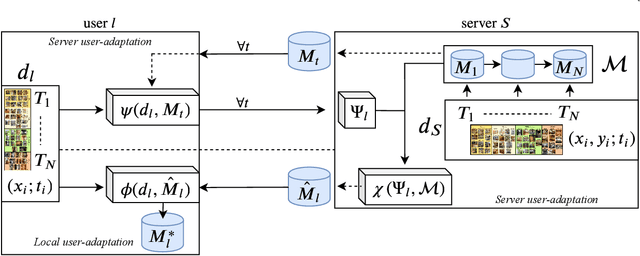
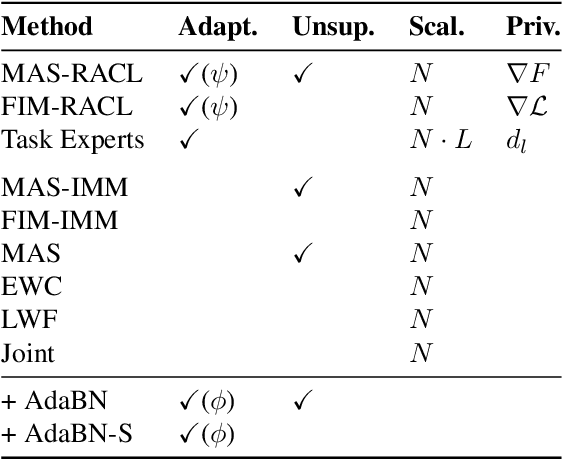

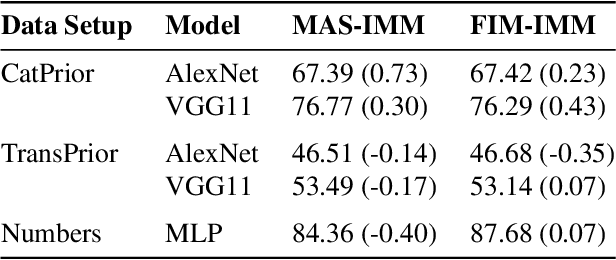
This work investigates the task of unsupervised model personalization, adapted to continually evolving, unlabeled local user images. We consider the practical scenario where a high capacity server interacts with a myriad of resource-limited edge devices, imposing strong requirements on scalability and local data privacy. We aim to address this challenge within the continual learning paradigm and provide a novel Dual User-Adaptation framework (DUA) to explore the problem. This framework flexibly disentangles user-adaptation into model personalization on the server and local data regularization on the user device, with desirable properties regarding scalability and privacy constraints. First, on the server, we introduce incremental learning of task-specific expert models, subsequently aggregated using a concealed unsupervised user prior. Aggregation avoids retraining, whereas the user prior conceals sensitive raw user data, and grants unsupervised adaptation. Second, local user-adaptation incorporates a domain adaptation point of view, adapting regularizing batch normalization parameters to the user data. We explore various empirical user configurations with different priors in categories and a tenfold of transforms for MIT Indoor Scene recognition, and classify numbers in a combined MNIST and SVHN setup. Extensive experiments yield promising results for data-driven local adaptation and elicit user priors for server adaptation to depend on the model rather than user data. Hence, although user-adaptation remains a challenging open problem, the DUA framework formalizes a principled foundation for personalizing both on server and user device, while maintaining privacy and scalability.
Deep-Geometric 6 DoF Localization from a Single Image in Topo-metric Maps
Feb 04, 2020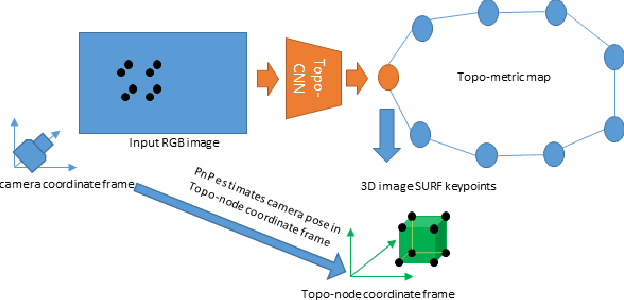
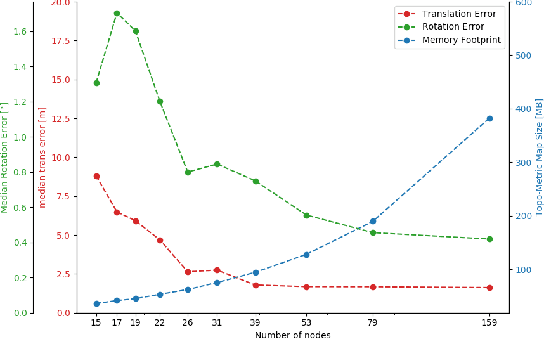
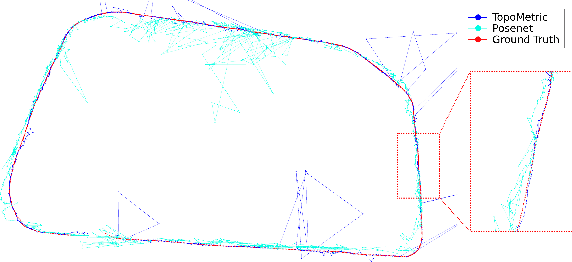

We describe a Deep-Geometric Localizer that is able to estimate the full 6 Degree of Freedom (DoF) global pose of the camera from a single image in a previously mapped environment. Our map is a topo-metric one, with discrete topological nodes whose 6 DoF poses are known. Each topo-node in our map also comprises of a set of points, whose 2D features and 3D locations are stored as part of the mapping process. For the mapping phase, we utilise a stereo camera and a regular stereo visual SLAM pipeline. During the localization phase, we take a single camera image, localize it to a topological node using Deep Learning, and use a geometric algorithm (PnP) on the matched 2D features (and their 3D positions in the topo map) to determine the full 6 DoF globally consistent pose of the camera. Our method divorces the mapping and the localization algorithms and sensors (stereo and mono), and allows accurate 6 DoF pose estimation in a previously mapped environment using a single camera. With potential VR/AR and localization applications in single camera devices such as mobile phones and drones, our hybrid algorithm compares favourably with the fully Deep-Learning based Pose-Net that regresses pose from a single image in simulated as well as real environments.
Information Compensation for Deep Conditional Generative Networks
Jan 24, 2020
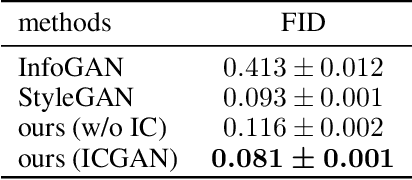
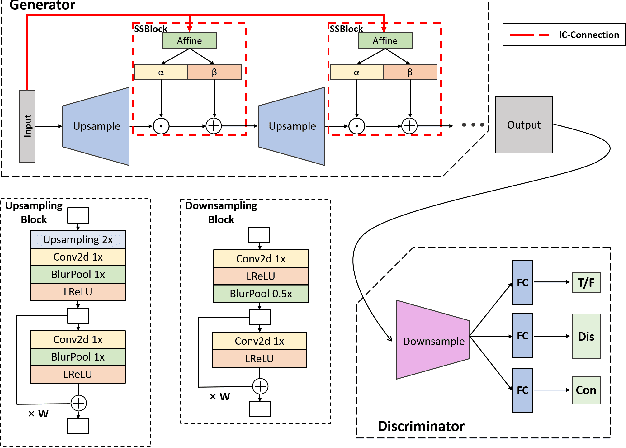
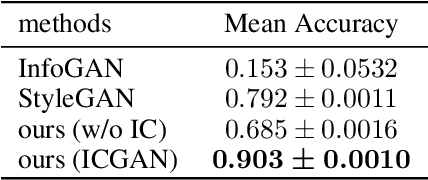
In recent years, unsupervised/weakly-supervised conditional generative adversarial networks (GANs) have achieved many successes on the task of modeling and generating data. However, one of their weaknesses lies in their poor ability to separate, or disentangle, the different factors that characterize the representation encoded in their latent space. To address this issue, we propose a novel structure for unsupervised conditional GANs powered by a novel Information Compensation Connection (IC-Connection). The proposed IC-Connection enables GANs to compensate for information loss incurred during deconvolution operations. In addition, to quantify the degree of disentanglement on both discrete and continuous latent variables, we design a novel evaluation procedure. Our empirical results suggest that our method achieves better disentanglement compared to the state-of-the-art GANs in a conditional generation setting.
Ternary Feature Masks: continual learning without any forgetting
Jan 23, 2020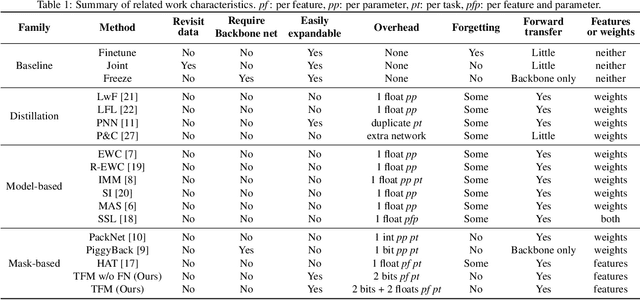
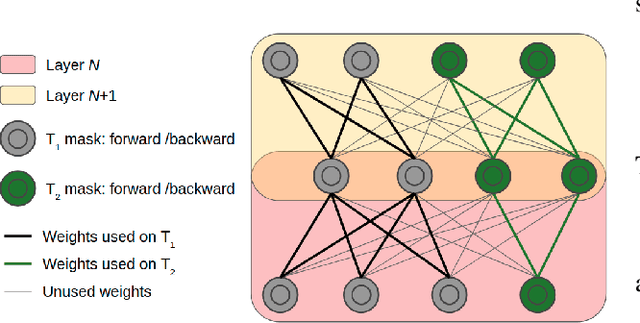
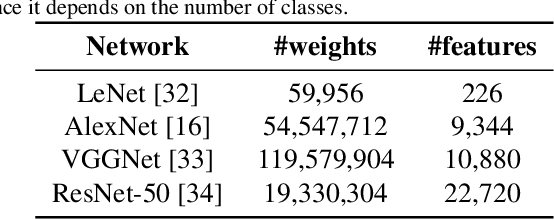
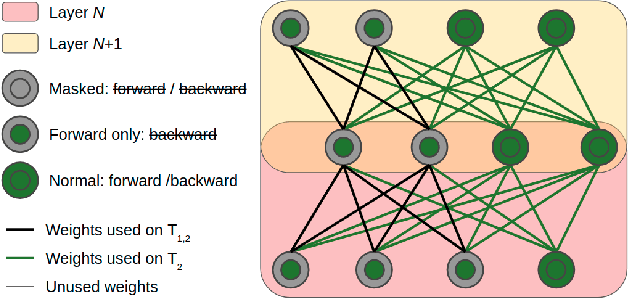
In this paper, we propose an approach without any forgetting to continual learning for the task-aware regime, where at inference the task-label is known. By using ternary masks we can upgrade a model to new tasks, reusing knowledge from previous tasks while not forgetting anything about them. Using masks prevents both catastrophic forgetting and backward transfer. We argue -- and show experimentally -- that avoiding the former largely compensates for the lack of the latter, which is rarely observed in practice. In contrast to earlier works, our masks are applied to the features (activations) of each layer instead of the weights. This considerably reduces the number of mask parameters to be added for each new task; with more than three orders of magnitude for most networks. The encoding of the ternary masks into two bits per feature creates very little overhead to the network, avoiding scalability issues. Our masks do not permit any changes to features which are used by previous tasks. As this may be too restrictive to allow learning of new tasks, we add task-specific feature normalization. This way, already learned features can adapt to the current task without changing the behavior of these features for previous tasks. Extensive experiments on several finegrained datasets and ImageNet show that our method outperforms current state-of-the-art while reducing memory overhead in comparison to weight-based approaches.
Dynamic Convolutions: Exploiting Spatial Sparsity for Faster Inference
Dec 06, 2019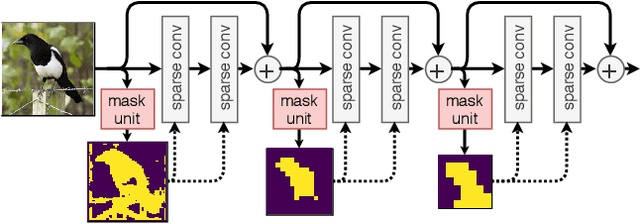
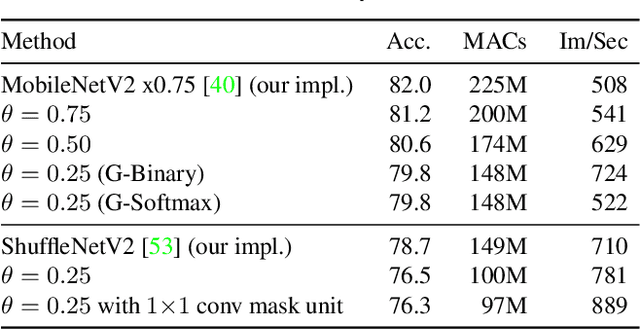
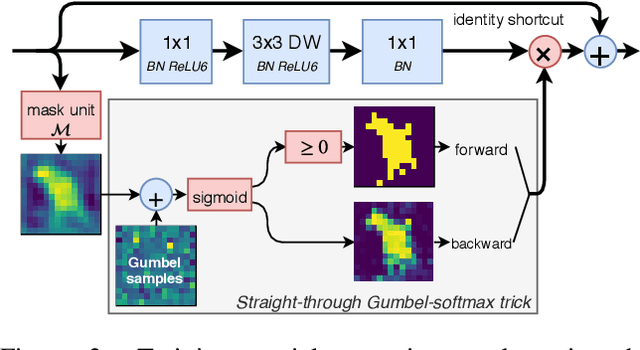

Modern convolutional neural networks apply the same operations on every pixel in an image. However, not all image regions are equally important. To address this inefficiency, we propose a method to dynamically apply convolutions conditioned on the input image. We introduce a residual block where a small gating branch learns which spatial positions should be evaluated. These discrete gating decisions are trained end-to-end using the Gumbel-Softmax trick, in combination with a sparsity criterion. Our experiments on Food-101, CIFAR and ImageNet show that our method has better focus on the region of interest and better accuracy than existing methods, at a lower computational complexity. Moreover, we provide an efficient CUDA implementation of our dynamic convolutions using a gather-scatter approach, achieving a significant improvement in inference speed on MobileNetV2 and ShuffleNetV2. On human pose estimation, a task that is inherently spatially sparse, the processing speed is increased by 45% with less than 0.1% loss in accuracy.