 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRehearsal revealed: The limits and merits of revisiting samples in continual learning
Apr 15, 2021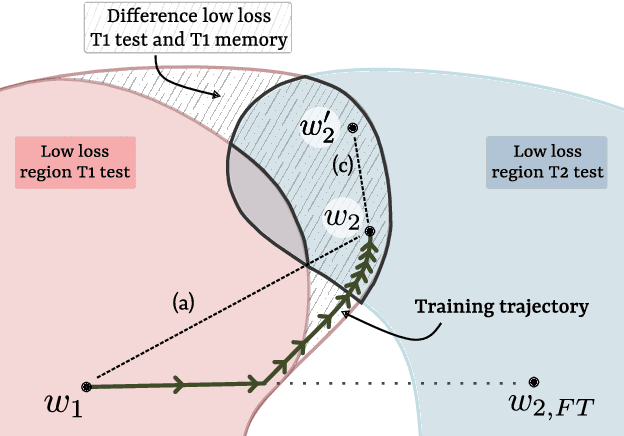

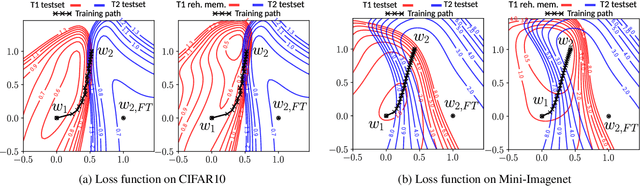

Learning from non-stationary data streams and overcoming catastrophic forgetting still poses a serious challenge for machine learning research. Rather than aiming to improve state-of-the-art, in this work we provide insight into the limits and merits of rehearsal, one of continual learning's most established methods. We hypothesize that models trained sequentially with rehearsal tend to stay in the same low-loss region after a task has finished, but are at risk of overfitting on its sample memory, hence harming generalization. We provide both conceptual and strong empirical evidence on three benchmarks for both behaviors, bringing novel insights into the dynamics of rehearsal and continual learning in general. Finally, we interpret important continual learning works in the light of our findings, allowing for a deeper understanding of their successes.
Reducing Representation Drift in Online Continual Learning
Apr 11, 2021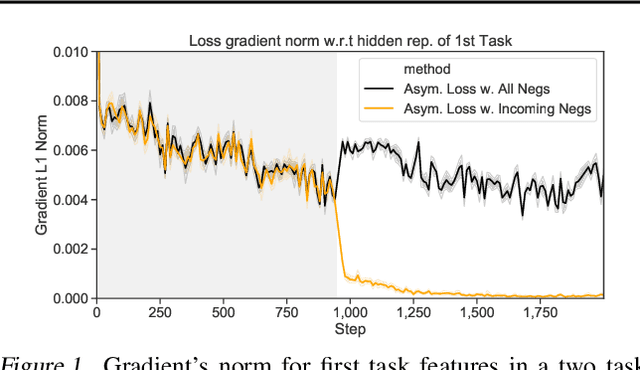
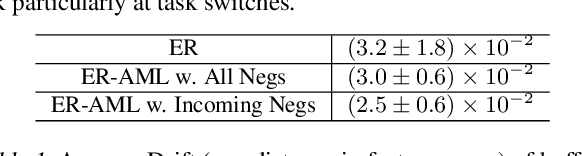
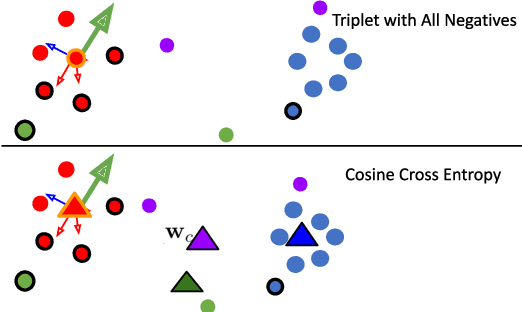
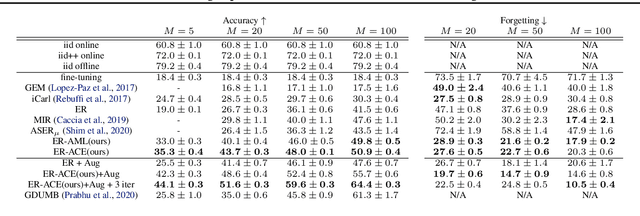
We study the online continual learning paradigm, where agents must learn from a changing distribution with constrained memory and compute. Previous work often tackle catastrophic forgetting by overcoming changes in the space of model parameters. In this work we instead focus on the change in representations of previously observed data due to the introduction of previously unobserved class samples in the incoming data stream. We highlight the issues that arise in the practical setting where new classes must be distinguished between all previous classes. Starting from a popular approach, experience replay, we consider a metric learning based loss function, the triplet loss, which allows us to more explicitly constrain the behavior of representations. We hypothesize and empirically confirm that the selection of negatives used in the triplet loss plays a major role in the representation change, or drift, of previously observed data and can be greatly reduced by appropriate negative selection. Motivated by this we further introduce a simple adjustment to the standard cross entropy loss used in prior experience replay that achieves similar effect. Our approach greatly improves the performance of experience replay and obtains state-of-the-art on several existing benchmarks in online continual learning, while remaining efficient in both memory and compute.
Avalanche: an End-to-End Library for Continual Learning
Apr 01, 2021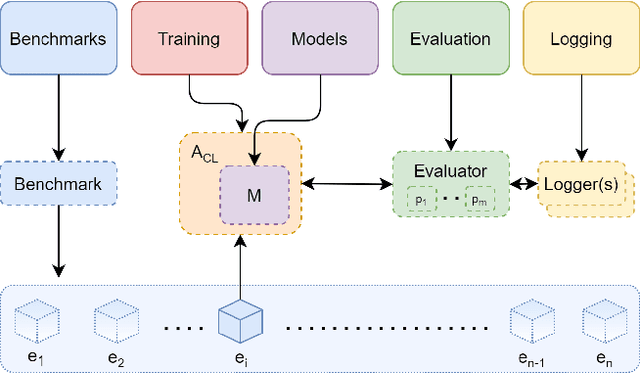

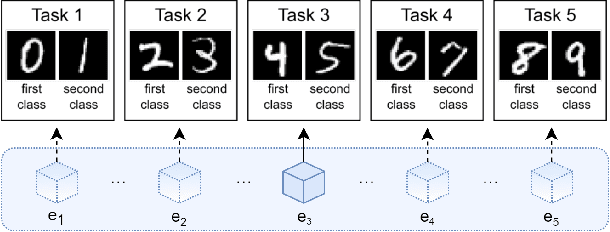

Learning continually from non-stationary data streams is a long-standing goal and a challenging problem in machine learning. Recently, we have witnessed a renewed and fast-growing interest in continual learning, especially within the deep learning community. However, algorithmic solutions are often difficult to re-implement, evaluate and port across different settings, where even results on standard benchmarks are hard to reproduce. In this work, we propose Avalanche, an open-source end-to-end library for continual learning research based on PyTorch. Avalanche is designed to provide a shared and collaborative codebase for fast prototyping, training, and reproducible evaluation of continual learning algorithms.
SegBlocks: Block-Based Dynamic Resolution Networks for Real-Time Segmentation
Nov 24, 2020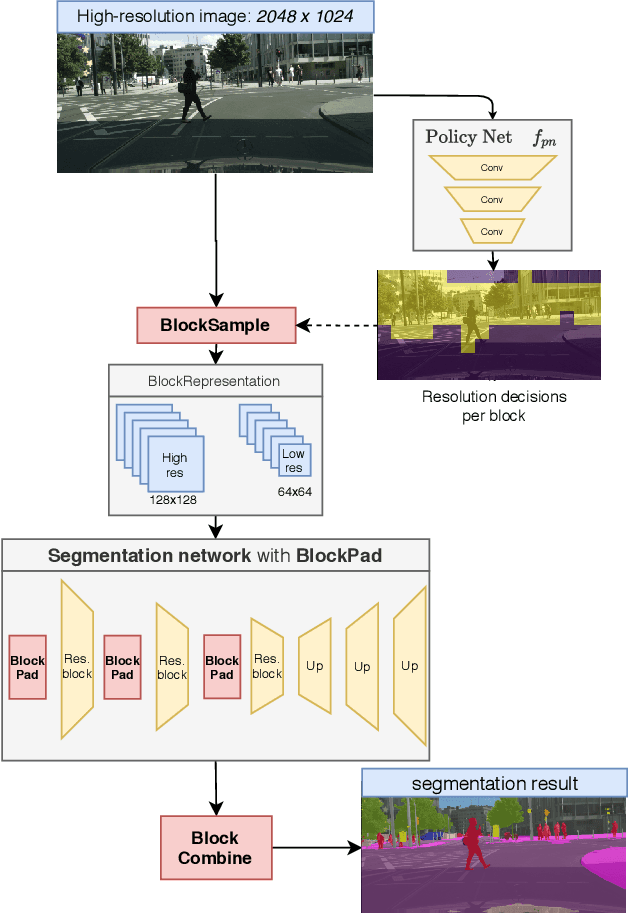
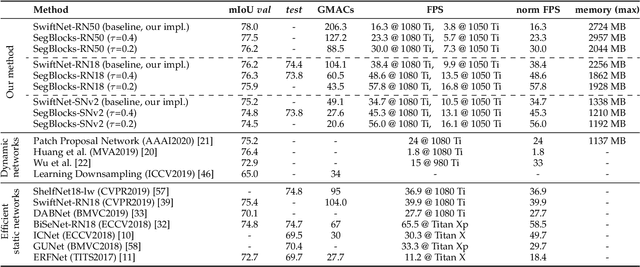
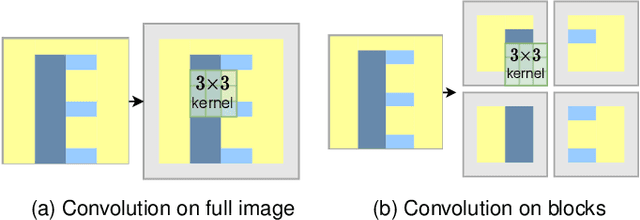

SegBlocks reduces the computational cost of existing neural networks, by dynamically adjusting the processing resolution of image regions based on their complexity. Our method splits an image into blocks and downsamples blocks of low complexity, reducing the number of operations and memory consumption. A lightweight policy network, selecting the complex regions, is trained using reinforcement learning. In addition, we introduce several modules implemented in CUDA to process images in blocks. Most important, our novel BlockPad module prevents the feature discontinuities at block borders of which existing methods suffer, while keeping memory consumption under control. Our experiments on Cityscapes and Mapillary Vistas semantic segmentation show that dynamically processing images offers a better accuracy versus complexity trade-off compared to static baselines of similar complexity. For instance, our method reduces the number of floating-point operations of SwiftNet-RN18 by 60% and increases the inference speed by 50%, with only 0.3% decrease in mIoU accuracy on Cityscapes.
Can the state of relevant neurons in a deep neural networks serve as indicators for detecting adversarial attacks?
Oct 29, 2020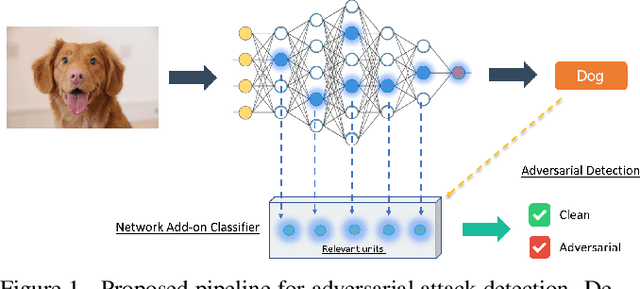
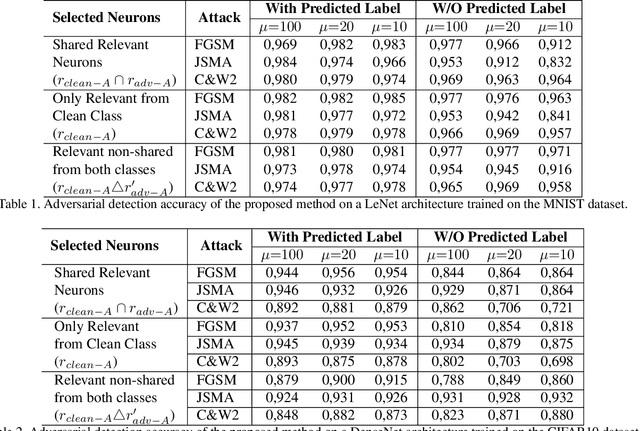
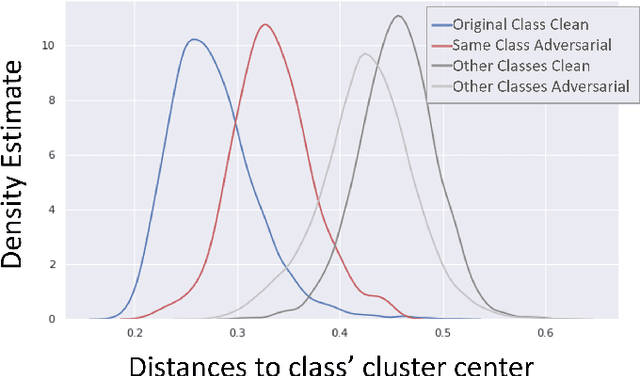
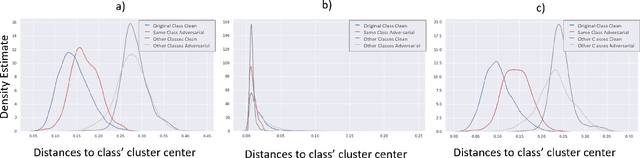
We present a method for adversarial attack detection based on the inspection of a sparse set of neurons. We follow the hypothesis that adversarial attacks introduce imperceptible perturbations in the input and that these perturbations change the state of neurons relevant for the concepts modelled by the attacked model. Therefore, monitoring the status of these neurons would enable the detection of adversarial attacks. Focusing on the image classification task, our method identifies neurons that are relevant for the classes predicted by the model. A deeper qualitative inspection of these sparse set of neurons indicates that their state changes in the presence of adversarial samples. Moreover, quantitative results from our empirical evaluation indicate that our method is capable of recognizing adversarial samples, produced by state-of-the-art attack methods, with comparable accuracy to that of state-of-the-art detectors.
On the Exploration of Incremental Learning for Fine-grained Image Retrieval
Oct 15, 2020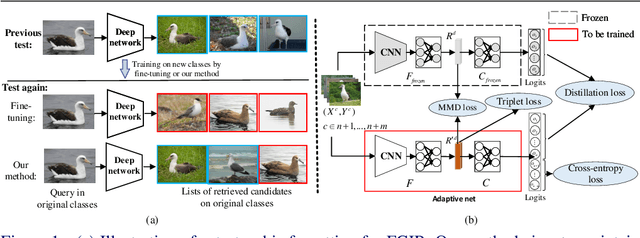
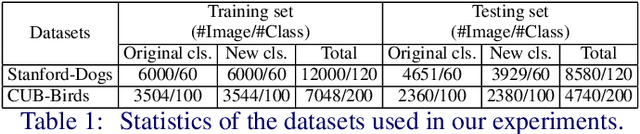
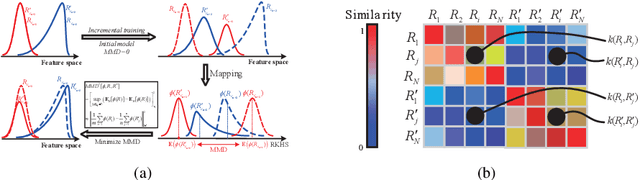
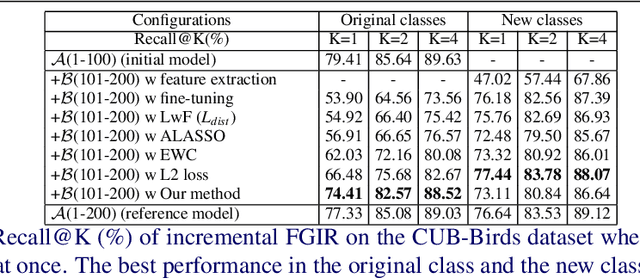
In this paper, we consider the problem of fine-grained image retrieval in an incremental setting, when new categories are added over time. On the one hand, repeatedly training the representation on the extended dataset is time-consuming. On the other hand, fine-tuning the learned representation only with the new classes leads to catastrophic forgetting. To this end, we propose an incremental learning method to mitigate retrieval performance degradation caused by the forgetting issue. Without accessing any samples of the original classes, the classifier of the original network provides soft "labels" to transfer knowledge to train the adaptive network, so as to preserve the previous capability for classification. More importantly, a regularization function based on Maximum Mean Discrepancy is devised to minimize the discrepancy of new classes features from the original network and the adaptive network, respectively. Extensive experiments on two datasets show that our method effectively mitigates the catastrophic forgetting on the original classes while achieving high performance on the new classes.
Self-Supervised Ranking for Representation Learning
Oct 14, 2020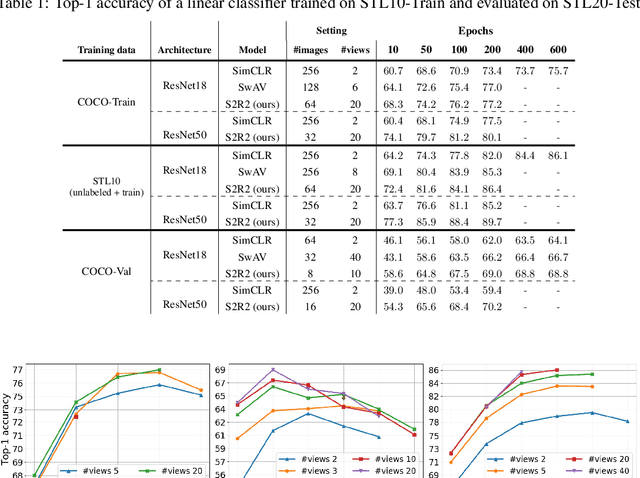
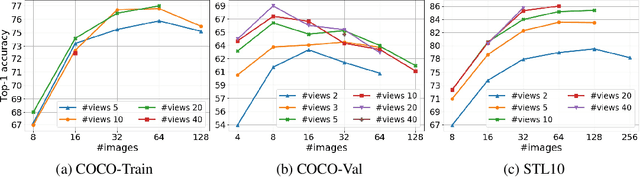
We present a new framework for self-supervised representation learning by positing it as a ranking problem in an image retrieval context on a large number of random views from random sets of images. Our work is based on two intuitive observations: first, a good representation of images must yield a high-quality image ranking in a retrieval task; second, we would expect random views of an image to be ranked closer to a reference view of that image than random views of other images. Hence, we model representation learning as a learning-to-rank problem in an image retrieval context, and train it by maximizing average precision (AP) for ranking. Specifically, given a mini-batch of images, we generate a large number of positive/negative samples and calculate a ranking loss term by separately treating each image view as a retrieval query. The new framework, dubbed S2R2, enables computing a global objective compared to the local objective in the popular contrastive learning framework calculated on pairs of views. A global objective leads S2R2 to faster convergence in terms of the number of epochs. In principle, by using a ranking criterion, we eliminate reliance on object-centered curated datasets (e.g., ImageNet). When trained on STL10 and MS-COCO, S2R2 outperforms SimCLR and performs on par with the state-of-the-art clustering-based contrastive learning model, SwAV, while being much simpler both conceptually and implementation-wise. Furthermore, when trained on a small subset of MS-COCO with fewer similar scenes, S2R2 significantly outperforms both SwAV and SimCLR. This indicates that S2R2 is potentially more effective on diverse scenes and decreases the need for a large training dataset for self-supervised learning.
Feed-Forward On-Edge Fine-tuning Using Static Synthetic Gradient Modules
Sep 21, 2020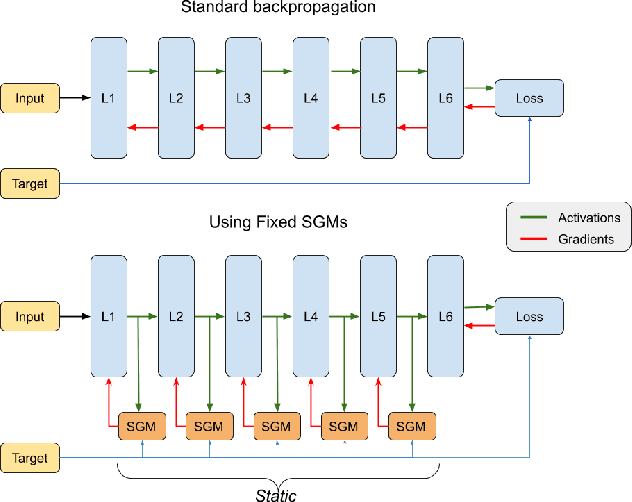
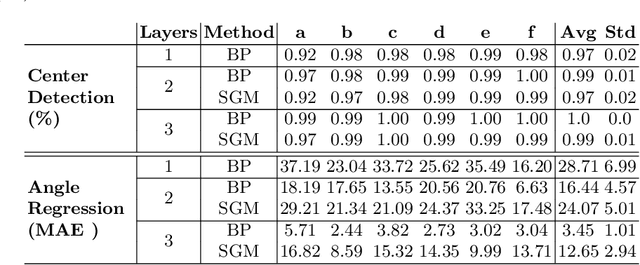
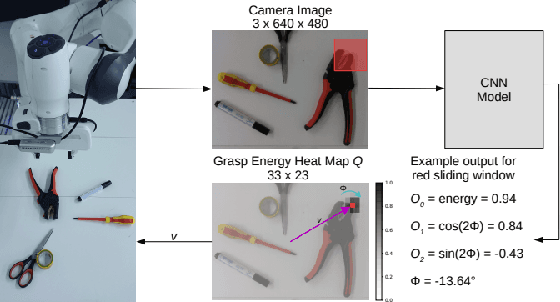
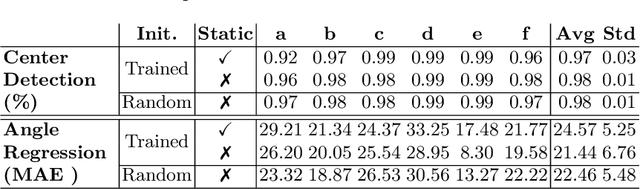
Training deep learning models on embedded devices is typically avoided since this requires more memory, computation and power over inference. In this work, we focus on lowering the amount of memory needed for storing all activations, which are required during the backward pass to compute the gradients. Instead, during the forward pass, static Synthetic Gradient Modules (SGMs) predict gradients for each layer. This allows training the model in a feed-forward manner without having to store all activations. We tested our method on a robot grasping scenario where a robot needs to learn to grasp new objects given only a single demonstration. By first training the SGMs in a meta-learning manner on a set of common objects, during fine-tuning, the SGMs provided the model with accurate gradients to successfully learn to grasp new objects. We have shown that our method has comparable results to using standard backpropagation.
Commands 4 Autonomous Vehicles (C4AV) Workshop Summary
Sep 18, 2020
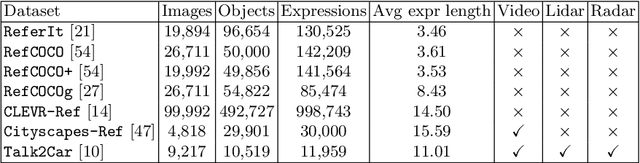

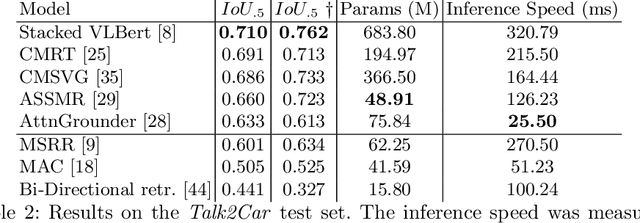
The task of visual grounding requires locating the most relevant region or object in an image, given a natural language query. So far, progress on this task was mostly measured on curated datasets, which are not always representative of human spoken language. In this work, we deviate from recent, popular task settings and consider the problem under an autonomous vehicle scenario. In particular, we consider a situation where passengers can give free-form natural language commands to a vehicle which can be associated with an object in the street scene. To stimulate research on this topic, we have organized the \emph{Commands for Autonomous Vehicles} (C4AV) challenge based on the recent \emph{Talk2Car} dataset (URL: https://www.aicrowd.com/challenges/eccv-2020-commands-4-autonomous-vehicles). This paper presents the results of the challenge. First, we compare the used benchmark against existing datasets for visual grounding. Second, we identify the aspects that render top-performing models successful, and relate them to existing state-of-the-art models for visual grounding, in addition to detecting potential failure cases by evaluating on carefully selected subsets. Finally, we discuss several possibilities for future work.
Multiple Exemplars-based Hallucinationfor Face Super-resolution and Editing
Sep 17, 2020
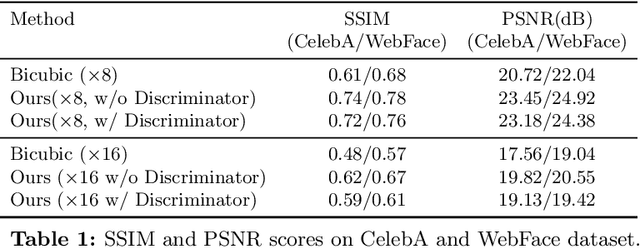
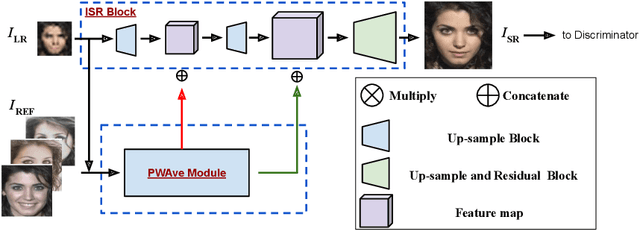

Given a really low-resolution input image of a face (say 16x16 or 8x8 pixels), the goal of this paper is to reconstruct a high-resolution version thereof. This, by itself, is an ill-posed problem, as the high-frequency information is missing in the low-resolution input and needs to be hallucinated, based on prior knowledge about the image content. Rather than relying on a generic face prior, in this paper, we explore the use of a set of exemplars, i.e. other high-resolution images of the same person. These guide the neural network as we condition the output on them. Multiple exemplars work better than a single one. To combine the information from multiple exemplars effectively, we introduce a pixel-wise weight generation module. Besides standard face super-resolution, our method allows to perform subtle face editing simply by replacing the exemplars with another set with different facial features. A user study is conducted and shows the super-resolved images can hardly be distinguished from real images on the CelebA dataset. A qualitative comparison indicates our model outperforms methods proposed in the literature on the CelebA and WebFace dataset.