 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvXAI: Delivering Heterogeneous AI Explanations via Conversations to Support Human-AI Scientific Writing
May 16, 2023While various AI explanation (XAI) methods have been proposed to interpret AI systems, whether the state-of-the-art XAI methods are practically useful for humans remains inconsistent findings. To improve the usefulness of XAI methods, a line of studies identifies the gaps between the diverse and dynamic real-world user needs with the status quo of XAI methods. Although prior studies envision mitigating these gaps by integrating multiple XAI methods into the universal XAI interfaces (e.g., conversational or GUI-based XAI systems), there is a lack of work investigating how these systems should be designed to meet practical user needs. In this study, we present ConvXAI, a conversational XAI system that incorporates multiple XAI types, and empowers users to request a variety of XAI questions via a universal XAI dialogue interface. Particularly, we innovatively embed practical user needs (i.e., four principles grounding on the formative study) into ConvXAI design to improve practical usefulness. Further, we design the domain-specific language (DSL) to implement the essential conversational XAI modules and release the core conversational universal XAI API for generalization. The findings from two within-subjects studies with 21 users show that ConvXAI is more useful for humans in perceiving the understanding and writing improvement, and improving the writing process in terms of productivity and sentence quality. Finally, this work contributes insight into the design space of useful XAI, reveals humans' XAI usage patterns with empirical evidence in practice, and identifies opportunities for future useful XAI work.
What Types of Questions Require Conversation to Answer? A Case Study of AskReddit Questions
Apr 03, 2023



The proliferation of automated conversational systems such as chatbots, spoken-dialogue systems, and smart speakers, has significantly impacted modern digital life. However, these systems are primarily designed to provide answers to well-defined questions rather than to support users in exploring complex, ill-defined questions. In this paper, we aim to push the boundaries of conversational systems by examining the types of nebulous, open-ended questions that can best be answered through conversation. We first sampled 500 questions from one million open-ended requests posted on AskReddit, and then recruited online crowd workers to answer eight inquiries about these questions. We also performed open coding to categorize the questions into 27 different domains. We found that the issues people believe require conversation to resolve satisfactorily are highly social and personal. Our work provides insights into how future research could be geared to align with users' needs.
Understanding Individual and Team-based Human Factors in Detecting Deepfake Texts
Apr 03, 2023



In recent years, Natural Language Generation (NLG) techniques in AI (e.g., T5, GPT-3, ChatGPT) have shown a massive improvement and are now capable of generating human-like long coherent texts at scale, yielding so-called deepfake texts. This advancement, despite their benefits, can also cause security and privacy issues (e.g., plagiarism, identity obfuscation, disinformation attack). As such, it has become critically important to develop effective, practical, and scalable solutions to differentiate deepfake texts from human-written texts. Toward this challenge, in this work, we investigate how factors such as skill levels and collaborations impact how humans identify deepfake texts, studying three research questions: (1) do collaborative teams detect deepfake texts better than individuals? (2) do expert humans detect deepfake texts better than non-expert humans? (3) what are the factors that maximize the detection performance of humans? We implement these questions on two platforms: (1) non-expert humans or asynchronous teams on Amazon Mechanical Turk (AMT) and (2) expert humans or synchronous teams on the Upwork. By analyzing the detection performance and the factors that affected performance, some of our key findings are: (1) expert humans detect deepfake texts significantly better than non-expert humans, (2) synchronous teams on the Upwork detect deepfake texts significantly better than individuals, while asynchronous teams on the AMT detect deepfake texts weakly better than individuals, and (3) among various error categories, examining coherence and consistency in texts is useful in detecting deepfake texts. In conclusion, our work could inform the design of future tools/framework to improve collaborative human detection of deepfake texts.
Summaries as Captions: Generating Figure Captions for Scientific Documents with Automated Text Summarization
Feb 23, 2023



Effective figure captions are crucial for clear comprehension of scientific figures, yet poor caption writing remains a common issue in scientific articles. Our study of arXiv cs.CL papers found that 53.88% of captions were rated as unhelpful or worse by domain experts, showing the need for better caption generation. Previous efforts in figure caption generation treated it as a vision task, aimed at creating a model to understand visual content and complex contextual information. Our findings, however, demonstrate that over 75% of figure captions' tokens align with corresponding figure-mentioning paragraphs, indicating great potential for language technology to solve this task. In this paper, we present a novel approach for generating figure captions in scientific documents using text summarization techniques. Our approach extracts sentences referencing the target figure, then summarizes them into a concise caption. In the experiments on real-world arXiv papers (81.2% were published at academic conferences), our method, using only text data, outperformed previous approaches in both automatic and human evaluations. We further conducted data-driven investigations into the two core challenges: (i) low-quality author-written captions and (ii) the absence of a standard for good captions. We found that our models could generate improved captions for figures with original captions rated as unhelpful, and the model trained on captions with more than 30 tokens produced higher-quality captions. We also found that good captions often include the high-level takeaway of the figure. Our work proves the effectiveness of text summarization in generating figure captions for scholarly articles, outperforming prior vision-based approaches. Our findings have practical implications for future figure captioning systems, improving scientific communication clarity.
Conveying the Predicted Future to Users: A Case Study of Story Plot Prediction
Feb 17, 2023Creative writing is hard: Novelists struggle with writer's block daily. While automatic story generation has advanced recently, it is treated as a "toy task" for advancing artificial intelligence rather than helping people. In this paper, we create a system that produces a short description that narrates a predicted plot using existing story generation approaches. Our goal is to assist writers in crafting a consistent and compelling story arc. We conducted experiments on Amazon Mechanical Turk (AMT) to examine the quality of the generated story plots in terms of consistency and storiability. The results show that short descriptions produced by our frame-enhanced GPT-2 (FGPT-2) were rated as the most consistent and storiable among all models; FGPT-2's outputs even beat some random story snippets written by humans. Next, we conducted a preliminary user study using a story continuation task where AMT workers were given access to machine-generated story plots and asked to write a follow-up story. FGPT-2 could positively affect the writing process, though people favor other baselines more. Our study shed some light on the possibilities of future creative writing support systems beyond the scope of completing sentences. Our code is available at: https://github.com/appleternity/Story-Plot-Generation.
Nationality Bias in Text Generation
Feb 14, 2023Little attention is placed on analyzing nationality bias in language models, especially when nationality is highly used as a factor in increasing the performance of social NLP models. This paper examines how a text generation model, GPT-2, accentuates pre-existing societal biases about country-based demonyms. We generate stories using GPT-2 for various nationalities and use sensitivity analysis to explore how the number of internet users and the country's economic status impacts the sentiment of the stories. To reduce the propagation of biases through large language models (LLM), we explore the debiasing method of adversarial triggering. Our results show that GPT-2 demonstrates significant bias against countries with lower internet users, and adversarial triggering effectively reduces the same.
Are Shortest Rationales the Best Explanations for Human Understanding?
Mar 16, 2022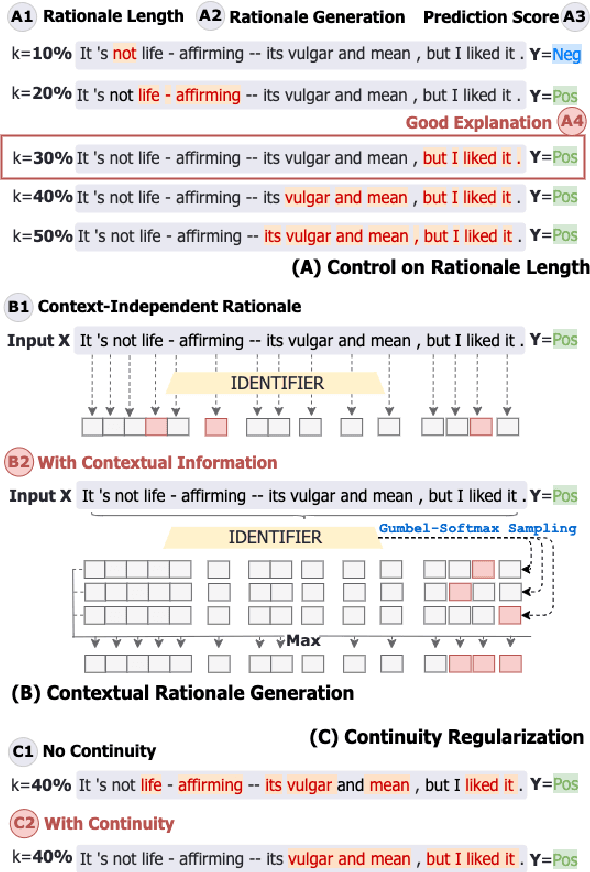
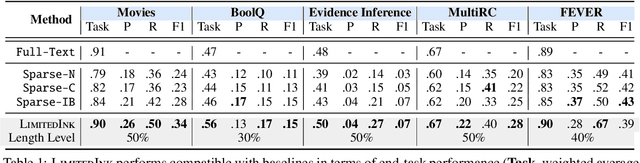
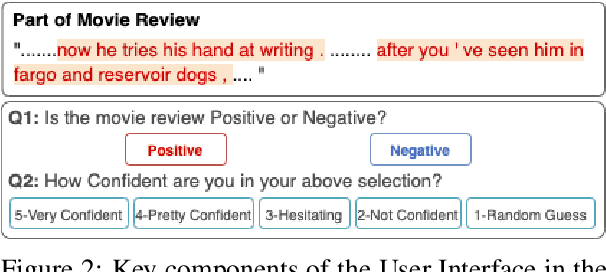
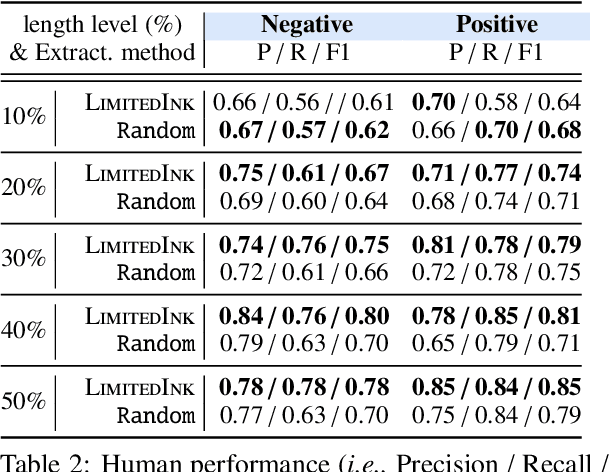
Existing self-explaining models typically favor extracting the shortest possible rationales - snippets of an input text "responsible for" corresponding output - to explain the model prediction, with the assumption that shorter rationales are more intuitive to humans. However, this assumption has yet to be validated. Is the shortest rationale indeed the most human-understandable? To answer this question, we design a self-explaining model, LimitedInk, which allows users to extract rationales at any target length. Compared to existing baselines, LimitedInk achieves compatible end-task performance and human-annotated rationale agreement, making it a suitable representation of the recent class of self-explaining models. We use LimitedInk to conduct a user study on the impact of rationale length, where we ask human judges to predict the sentiment label of documents based only on LimitedInk-generated rationales with different lengths. We show rationales that are too short do not help humans predict labels better than randomly masked text, suggesting the need for more careful design of the best human rationales.
SciCap: Generating Captions for Scientific Figures
Oct 25, 2021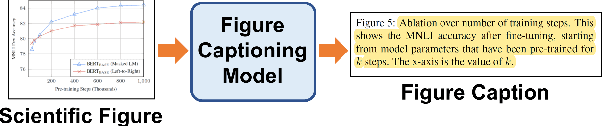
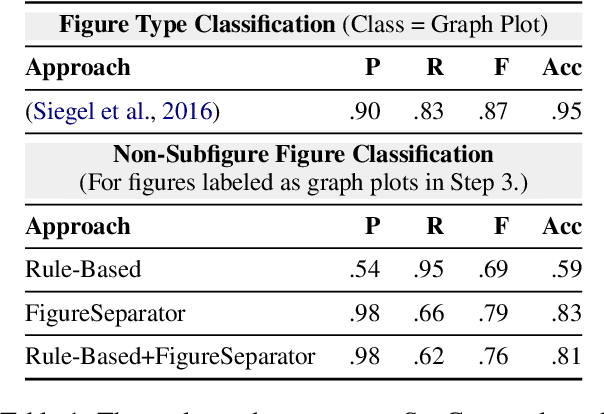
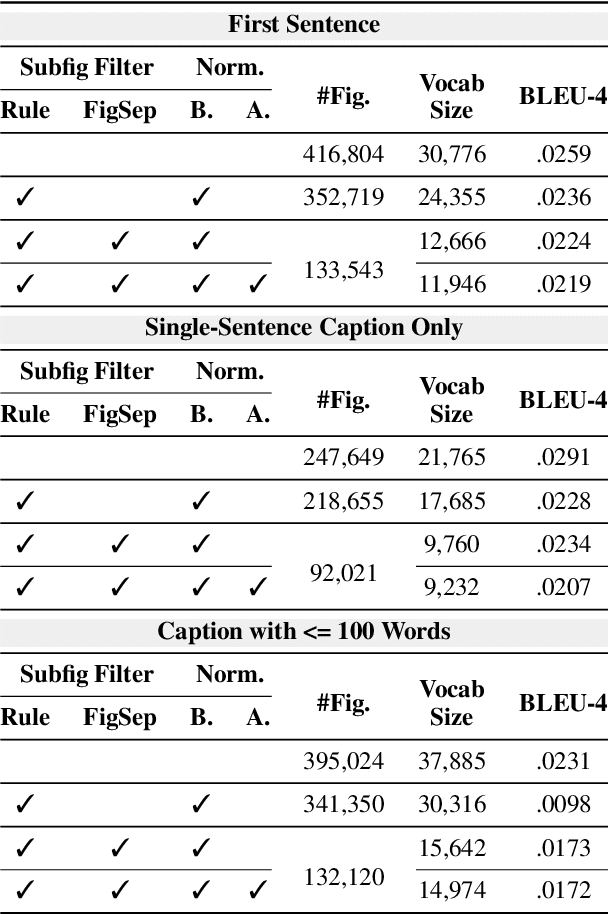
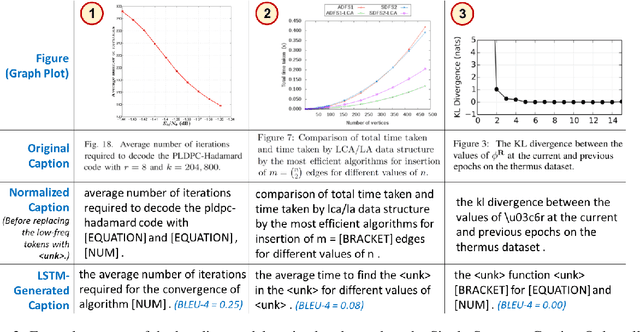
Researchers use figures to communicate rich, complex information in scientific papers. The captions of these figures are critical to conveying effective messages. However, low-quality figure captions commonly occur in scientific articles and may decrease understanding. In this paper, we propose an end-to-end neural framework to automatically generate informative, high-quality captions for scientific figures. To this end, we introduce SCICAP, a large-scale figure-caption dataset based on computer science arXiv papers published between 2010 and 2020. After pre-processing - including figure-type classification, sub-figure identification, text normalization, and caption text selection - SCICAP contained more than two million figures extracted from over 290,000 papers. We then established baseline models that caption graph plots, the dominant (19.2%) figure type. The experimental results showed both opportunities and steep challenges of generating captions for scientific figures.
Empowering Local Communities Using Artificial Intelligence
Oct 05, 2021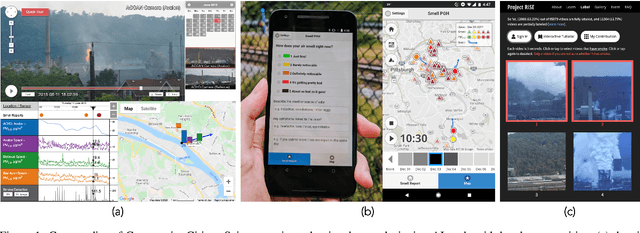
Many powerful Artificial Intelligence (AI) techniques have been engineered with the goals of high performance and accuracy. Recently, AI algorithms have been integrated into diverse and real-world applications. It has become an important topic to explore the impact of AI on society from a people-centered perspective. Previous works in citizen science have identified methods of using AI to engage the public in research, such as sustaining participation, verifying data quality, classifying and labeling objects, predicting user interests, and explaining data patterns. These works investigated the challenges regarding how scientists design AI systems for citizens to participate in research projects at a large geographic scale in a generalizable way, such as building applications for citizens globally to participate in completing tasks. In contrast, we are interested in another area that receives significantly less attention: how scientists co-design AI systems "with" local communities to influence a particular geographical region, such as community-based participatory projects. Specifically, this article discusses the challenges of applying AI in Community Citizen Science, a framework to create social impact through community empowerment at an intensely place-based local scale. We provide insights in this under-explored area of focus to connect scientific research closely to social issues and citizen needs.
Plot and Rework: Modeling Storylines for Visual Storytelling
May 23, 2021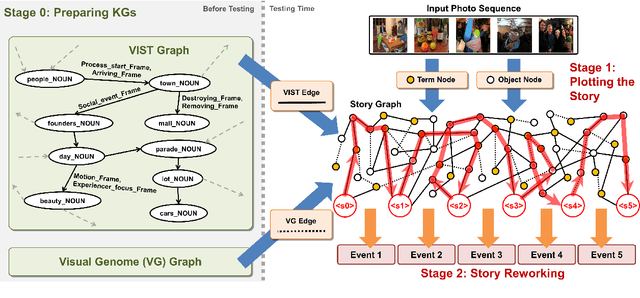

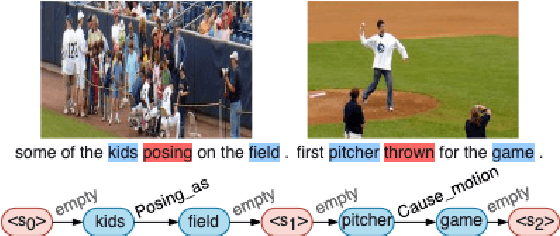

Writing a coherent and engaging story is not easy. Creative writers use their knowledge and worldview to put disjointed elements together to form a coherent storyline, and work and rework iteratively toward perfection. Automated visual storytelling (VIST) models, however, make poor use of external knowledge and iterative generation when attempting to create stories. This paper introduces PR-VIST, a framework that represents the input image sequence as a story graph in which it finds the best path to form a storyline. PR-VIST then takes this path and learns to generate the final story via an iterative training process. This framework produces stories that are superior in terms of diversity, coherence, and humanness, per both automatic and human evaluations. An ablation study shows that both plotting and reworking contribute to the model's superiority.