 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIJmond Industrial Smoke Segmentation Dataset
Mar 24, 2026This report describes a dataset for industrial smoke segmentation, published on a figshare repository (https://doi.org/10.21942/uva.31847188). The dataset is licensed under CC BY 4.0.
Bridging Synthetic and Real-World Domains: A Human-in-the-Loop Weakly-Supervised Framework for Industrial Toxic Emission Segmentation
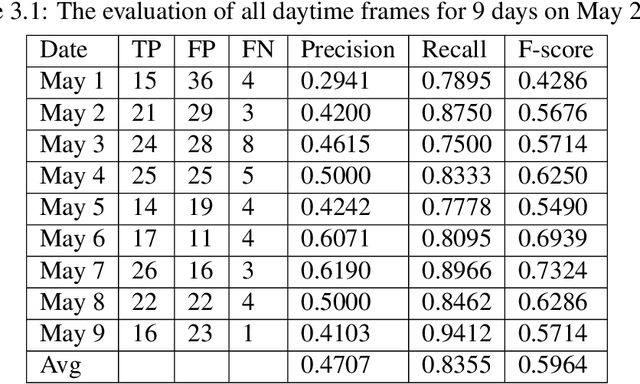
Jul 29, 2025Industrial smoke segmentation is critical for air-quality monitoring and environmental protection but is often hampered by the high cost and scarcity of pixel-level annotations in real-world settings. We introduce CEDANet, a human-in-the-loop, class-aware domain adaptation framework that uniquely integrates weak, citizen-provided video-level labels with adversarial feature alignment. Specifically, we refine pseudo-labels generated by a source-trained segmentation model using citizen votes, and employ class-specific domain discriminators to transfer rich source-domain representations to the industrial domain. Comprehensive experiments on SMOKE5K and custom IJmond datasets demonstrate that CEDANet achieves an F1-score of 0.414 and a smoke-class IoU of 0.261 with citizen feedback, vastly outperforming the baseline model, which scored 0.083 and 0.043 respectively. This represents a five-fold increase in F1-score and a six-fold increase in smoke-class IoU. Notably, CEDANet with citizen-constrained pseudo-labels achieves performance comparable to the same architecture trained on limited 100 fully annotated images with F1-score of 0.418 and IoU of 0.264, demonstrating its ability to reach small-sampled fully supervised-level accuracy without target-domain annotations. Our research validates the scalability and cost-efficiency of combining citizen science with weakly supervised domain adaptation, offering a practical solution for complex, data-scarce environmental monitoring applications.
Empowering Local Communities Using Artificial Intelligence
Oct 05, 2021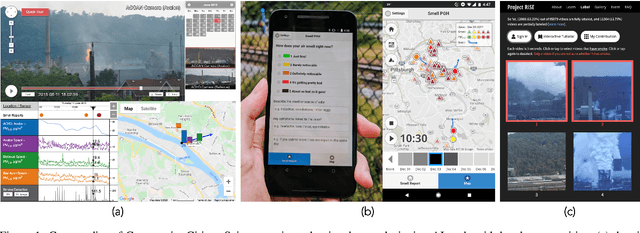
Many powerful Artificial Intelligence (AI) techniques have been engineered with the goals of high performance and accuracy. Recently, AI algorithms have been integrated into diverse and real-world applications. It has become an important topic to explore the impact of AI on society from a people-centered perspective. Previous works in citizen science have identified methods of using AI to engage the public in research, such as sustaining participation, verifying data quality, classifying and labeling objects, predicting user interests, and explaining data patterns. These works investigated the challenges regarding how scientists design AI systems for citizens to participate in research projects at a large geographic scale in a generalizable way, such as building applications for citizens globally to participate in completing tasks. In contrast, we are interested in another area that receives significantly less attention: how scientists co-design AI systems "with" local communities to influence a particular geographical region, such as community-based participatory projects. Specifically, this article discusses the challenges of applying AI in Community Citizen Science, a framework to create social impact through community empowerment at an intensely place-based local scale. We provide insights in this under-explored area of focus to connect scientific research closely to social issues and citizen needs.
RISE Video Dataset: Recognizing Industrial Smoke Emissions
May 20, 2020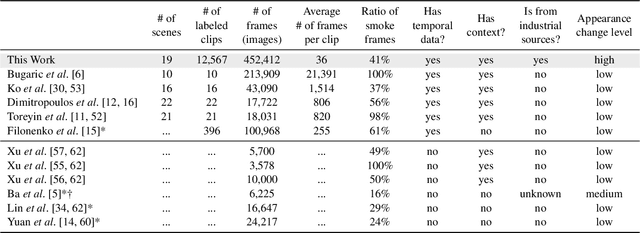
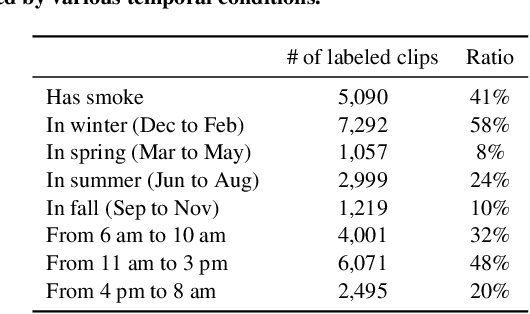
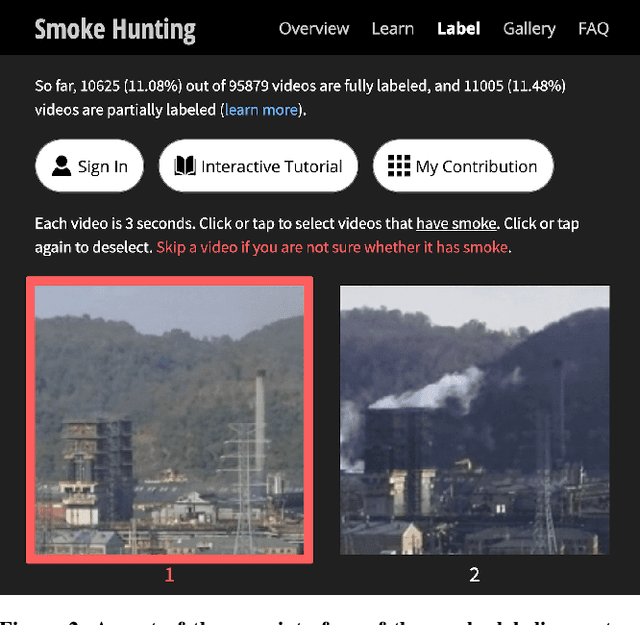

Industrial smoke emissions pose a significant concern to human health. Prior works have shown that using Computer Vision (CV) techniques to identify smoke as visual evidence can influence the attitude of regulators and empower citizens in pursuing environmental justice. However, existing datasets do not have sufficient quality nor quantity for training robust CV models to support air quality advocacy. We introduce RISE, the first large-scale video dataset for Recognizing Industrial Smoke Emissions. We adopt the citizen science approach to collaborate with local community members in annotating whether a video clip has smoke emissions. Our dataset contains 12,567 clips with 19 distinct views from cameras on three sites that monitored three different industrial facilities. The clips are from 30 days that spans four seasons in two years in the daytime. We run experiments using deep neural networks developed for video action recognition to establish a performance baseline and reveal the challenges for smoke recognition. Our data analysis also shows opportunities for integrating citizen scientists and crowd workers into the application of Artificial Intelligence for social good.
CODA-19: Reliably Annotating Research Aspects on 10,000+ CORD-19 Abstracts Using a Non-Expert Crowd
May 20, 2020
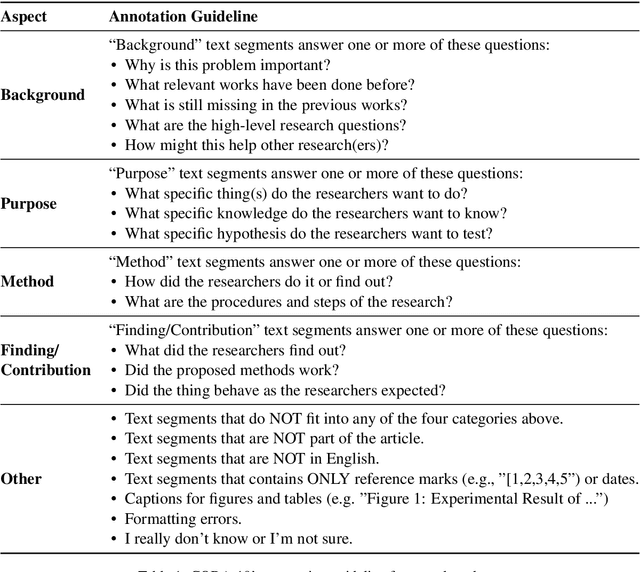


This paper introduces CODA-19, a human-annotated dataset that codes the Background, Purpose, Method, Finding/Contribution, and Other sections of 10,966 English abstracts in the COVID-19 Open Research Dataset. CODA-19 was created by 248 crowd workers from Amazon Mechanical Turk within 10 days, achieving a label quality comparable to that of experts. Each abstract was annotated by nine different workers, and the final labels were obtained by majority vote. The inter-annotator agreement (Cohen's kappa) between the crowd and the biomedical expert (0.741) is comparable to inter-expert agreement (0.788). CODA-19's labels have an accuracy of 82.2% when compared to the biomedical expert's labels, while the accuracy between experts was 85.0%. Reliable human annotations help scientists to understand the rapidly accelerating coronavirus literature and also serve as the battery of AI/NLP research, but obtaining expert annotations can be slow. We demonstrated that a non-expert crowd can be rapidly employed at scale to join the fight against COVID-19.
Smell Pittsburgh: Engaging Community Citizen Science for Air Quality
Dec 30, 2019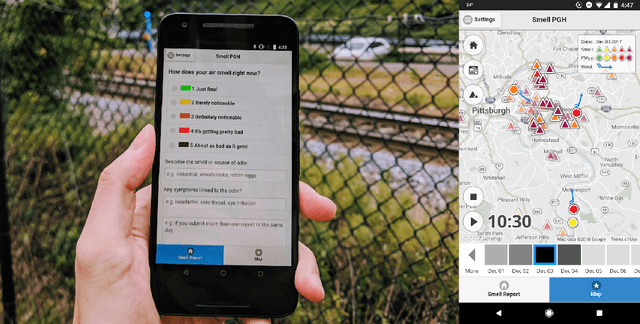
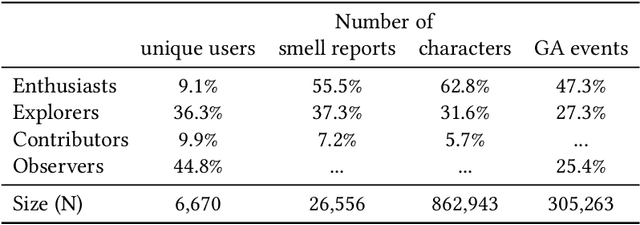
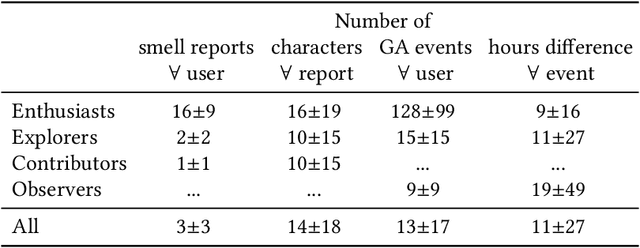
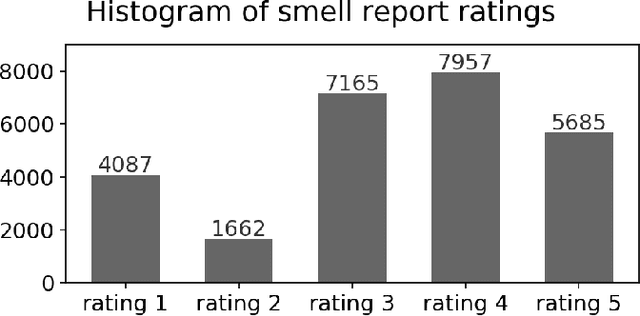
Urban air pollution has been linked to various human health concerns, including cardiopulmonary diseases. Communities who suffer from poor air quality often rely on experts to identify pollution sources due to the lack of accessible tools. Taking this into account, we developed Smell Pittsburgh, a system that enables community members to report odors and track where these odors are frequently concentrated. All smell report data are publicly accessible online. These reports are also sent to the local health department and visualized on a map along with air quality data from monitoring stations. This visualization provides a comprehensive overview of the local pollution landscape. Additionally, with these reports and air quality data, we developed a model to predict upcoming smell events and send push notifications to inform communities. We also applied regression analysis to identify statistically significant effects of push notifications on user engagement. Our evaluation of this system demonstrates that engaging residents in documenting their experiences with pollution odors can help identify local air pollution patterns, and can empower communities to advocate for better air quality. All citizen-contributed smell data are publicly accessible and can be downloaded from https://smellpgh.org.
Visual Story Post-Editing
Jun 05, 2019
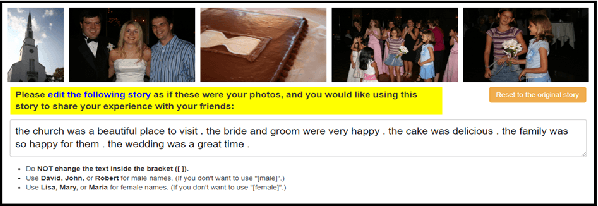

We introduce the first dataset for human edits of machine-generated visual stories and explore how these collected edits may be used for the visual story post-editing task. The dataset, VIST-Edit, includes 14,905 human edited versions of 2,981 machine-generated visual stories. The stories were generated by two state-of-the-art visual storytelling models, each aligned to 5 human-edited versions. We establish baselines for the task, showing how a relatively small set of human edits can be leveraged to boost the performance of large visual storytelling models. We also discuss the weak correlation between automatic evaluation scores and human ratings, motivating the need for new automatic metrics.
On How Users Edit Computer-Generated Visual Stories
Mar 08, 2019



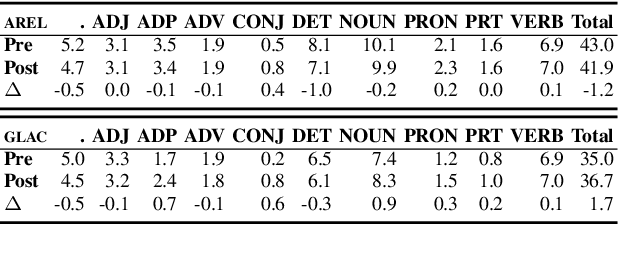
A significant body of research in Artificial Intelligence (AI) has focused on generating stories automatically, either based on prior story plots or input images. However, literature has little to say about how users would receive and use these stories. Given the quality of stories generated by modern AI algorithms, users will nearly inevitably have to edit these stories before putting them to real use. In this paper, we present the first analysis of how human users edit machine-generated stories. We obtained 962 short stories generated by one of the state-of-the-art visual storytelling models. For each story, we recruited five crowd workers from Amazon Mechanical Turk to edit it. Our analysis of these edits shows that, on average, users (i) slightly shortened machine-generated stories, (ii) increased lexical diversity in these stories, and (iii) often replaced nouns and their determiners/articles with pronouns. Our study provides a better understanding on how users receive and edit machine-generated stories,informing future researchers to create more usable and helpful story generation systems.
Industrial Smoke Detection and Visualization
Sep 17, 2018

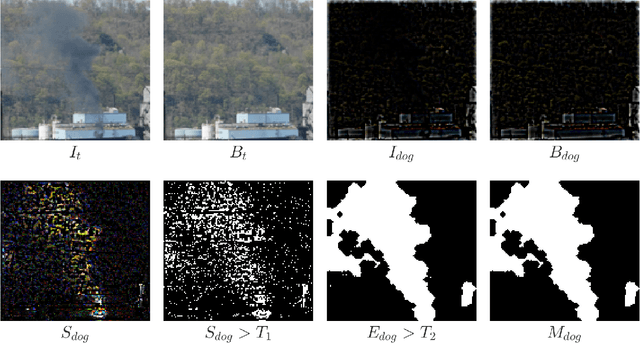
As sensing technology proliferates and becomes affordable to the general public, there is a growing trend in citizen science where scientists and volunteers form a strong partnership in conducting scientific research including problem finding, data collection, analysis, visualization, and storytelling. Providing easy-to-use computational tools to support citizen science has become an important issue. To raise the public awareness of environmental science and improve the air quality in local areas, we are currently collaborating with a local community in monitoring and documenting fugitive emissions from a coke refinery. We have helped the community members build a live camera system which captures and visualizes high resolution timelapse imagery starting from November 2014. However, searching and documenting smoke emissions manually from all video frames requires manpower and takes an impractical investment of time. This paper describes a software tool which integrates four features: (1) an algorithm based on change detection and texture segmentation for identifying smoke emissions; (2) an interactive timeline visualization providing indicators for seeking to interesting events; (3) an autonomous fast-forwarding mode for skipping uninteresting timelapse frames; and (4) a collection of animated smoke images generated automatically according to the algorithm for documentation, presentation, storytelling, and sharing. With the help of this tool, citizen scientists can now focus on the content of the story instead of time-consuming and laborious works.
SimArch: A Multi-agent System For Human Path Simulation In Architecture Design
Jul 10, 2018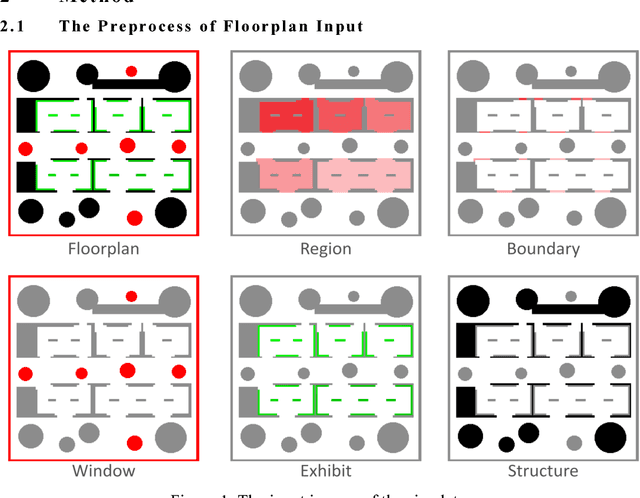
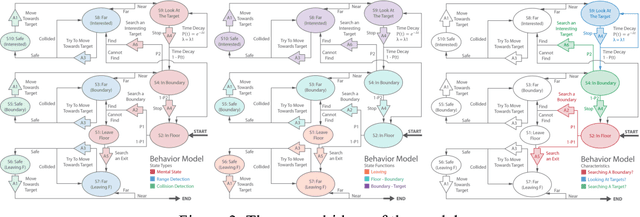
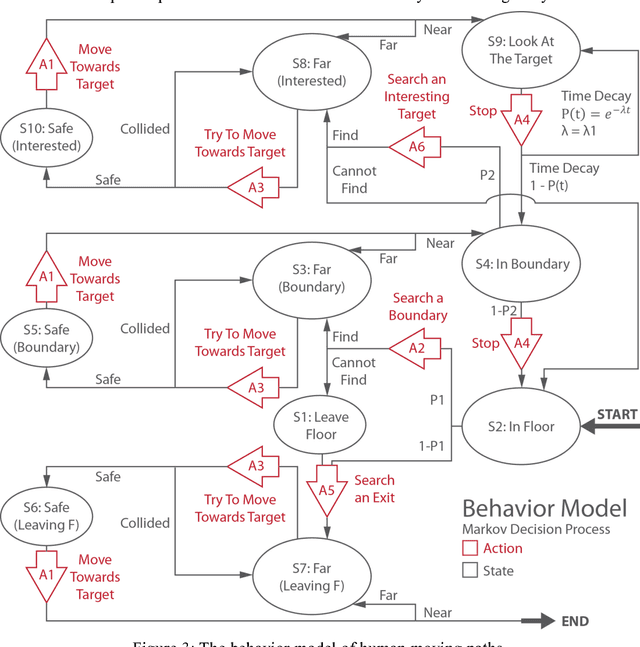

Human moving path is an important feature in architecture design. By studying the path, architects know where to arrange the basic elements (e.g. structures, glasses, furniture, etc.) in the space. This paper presents SimArch, a multi-agent system for human moving path simulation. It involves a behavior model built by using a Markov Decision Process. The model simulates human mental states, target range detection, and collision prediction when agents are on the floor, in a particular small gallery, looking at an exhibit, or leaving the floor. It also models different kinds of human characteristics by assigning different transition probabilities. A modified weighted A* search algorithm quickly plans the sub-optimal path of the agents. In an experiment, SimArch takes a series of preprocessed floorplans as inputs, simulates the moving path, and outputs a density map for evaluation. The density map provides the prediction that how likely a person will occur in a location. A following discussion illustrates how architects can use the density map to improve their floorplan design.