 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Self-Supervision for Video Identification of Individual Holstein-Friesian Cattle: The Cows2021 Dataset
May 05, 2021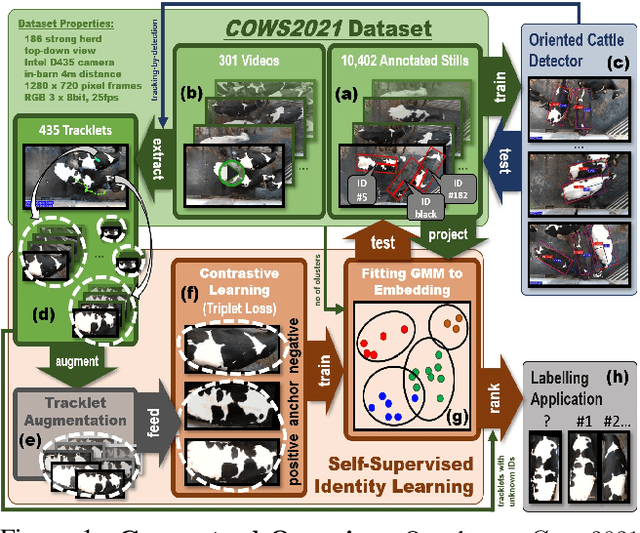


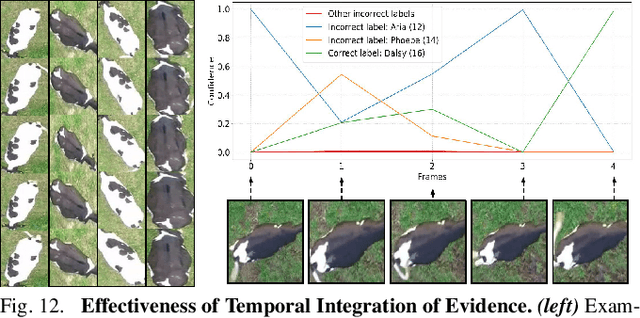
In this paper we publish the largest identity-annotated Holstein-Friesian cattle dataset Cows2021 and a first self-supervision framework for video identification of individual animals. The dataset contains 10,402 RGB images with labels for localisation and identity as well as 301 videos from the same herd. The data shows top-down in-barn imagery, which captures the breed's individually distinctive black and white coat pattern. Motivated by the labelling burden involved in constructing visual cattle identification systems, we propose exploiting the temporal coat pattern appearance across videos as a self-supervision signal for animal identity learning. Using an individual-agnostic cattle detector that yields oriented bounding-boxes, rotation-normalised tracklets of individuals are formed via tracking-by-detection and enriched via augmentations. This produces a `positive' sample set per tracklet, which is paired against a `negative' set sampled from random cattle of other videos. Frame-triplet contrastive learning is then employed to construct a metric latent space. The fitting of a Gaussian Mixture Model to this space yields a cattle identity classifier. Results show an accuracy of Top-1 57.0% and Top-4: 76.9% and an Adjusted Rand Index: 0.53 compared to the ground truth. Whilst supervised training surpasses this benchmark by a large margin, we conclude that self-supervision can nevertheless play a highly effective role in speeding up labelling efforts when initially constructing supervision information. We provide all data and full source code alongside an analysis and evaluation of the system.
Temporal-Relational CrossTransformers for Few-Shot Action Recognition
Jan 15, 2021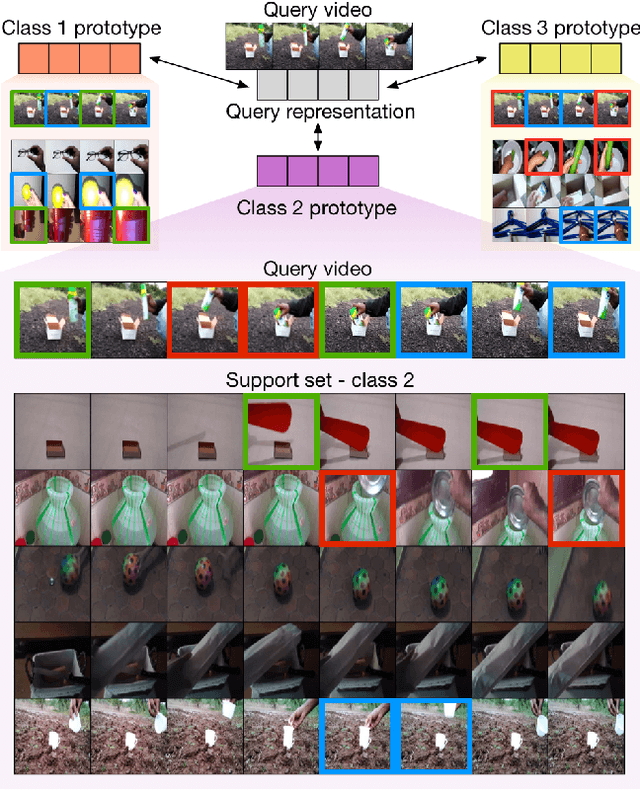
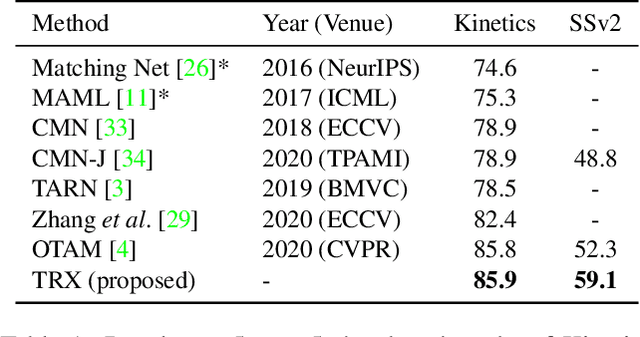
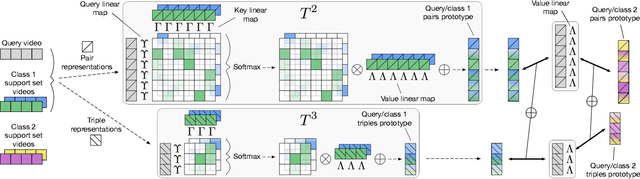
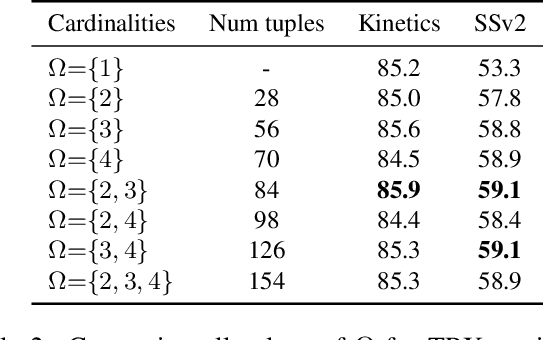
We propose a novel approach to few-shot action recognition, finding temporally-corresponding frame tuples between the query and videos in the support set. Distinct from previous few-shot action recognition works, we construct class prototypes using the CrossTransformer attention mechanism to observe relevant sub-sequences of all support videos, rather than using class averages or single best matches. Video representations are formed from ordered tuples of varying numbers of frames, which allows sub-sequences of actions at different speeds and temporal offsets to be compared. Our proposed Temporal-Relational CrossTransformers achieve state-of-the-art results on both Kinetics and Something-Something V2 (SSv2), outperforming prior work on SSv2 by a wide margin (6.8%) due to the method's ability to model temporal relations. A detailed ablation showcases the importance of matching to multiple support set videos and learning higher-order relational CrossTransformers. Code is available at https://github.com/tobyperrett/trx
A Dataset and Application for Facial Recognition of Individual Gorillas in Zoo Environments
Dec 08, 2020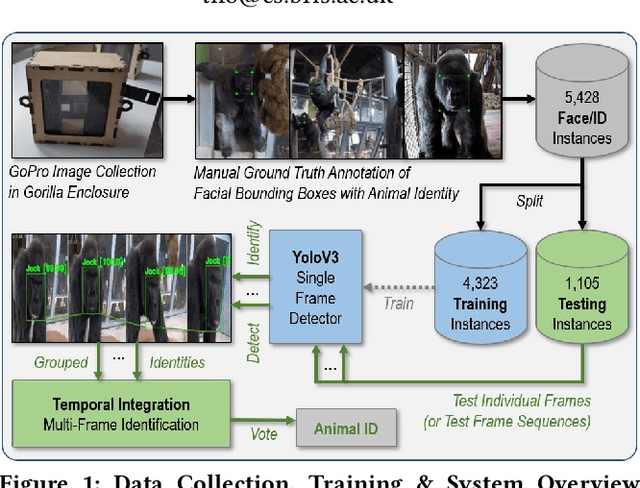
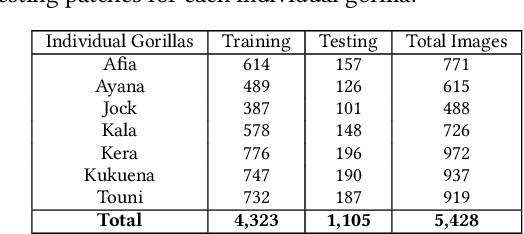


We put forward a video dataset with 5k+ facial bounding box annotations across a troop of 7 western lowland gorillas at Bristol Zoo Gardens. Training on this dataset, we implement and evaluate a standard deep learning pipeline on the task of facially recognising individual gorillas in a zoo environment. We show that a basic YOLOv3-powered application is able to perform identifications at 92% mAP when utilising single frames only. Tracking-by-detection-association and identity voting across short tracklets yields an improved robust performance of 97% mAP. To facilitate easy utilisation for enriching the research capabilities of zoo environments, we publish the code, video dataset, weights, and ground-truth annotations at data.bris.ac.uk.
Visual Recognition of Great Ape Behaviours in the Wild
Nov 21, 2020
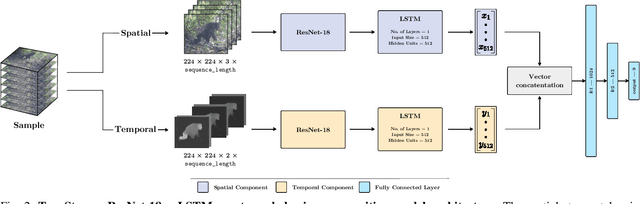
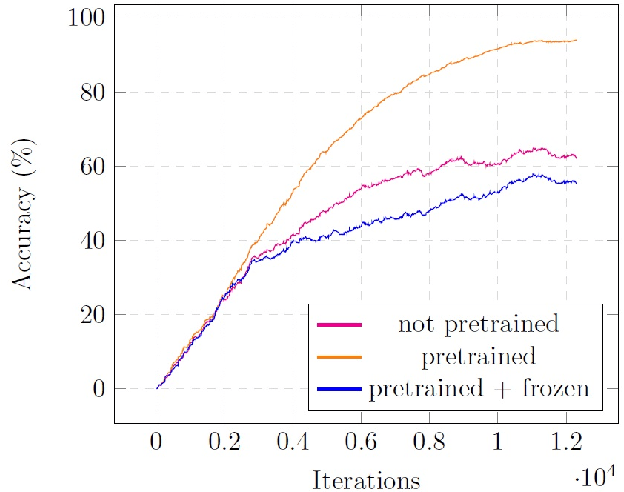

We propose a first great ape-specific visual behaviour recognition system utilising deep learning that is capable of detecting nine core ape behaviours.
Back to the Future: Cycle Encoding Prediction for Self-supervised Contrastive Video Representation Learning
Oct 15, 2020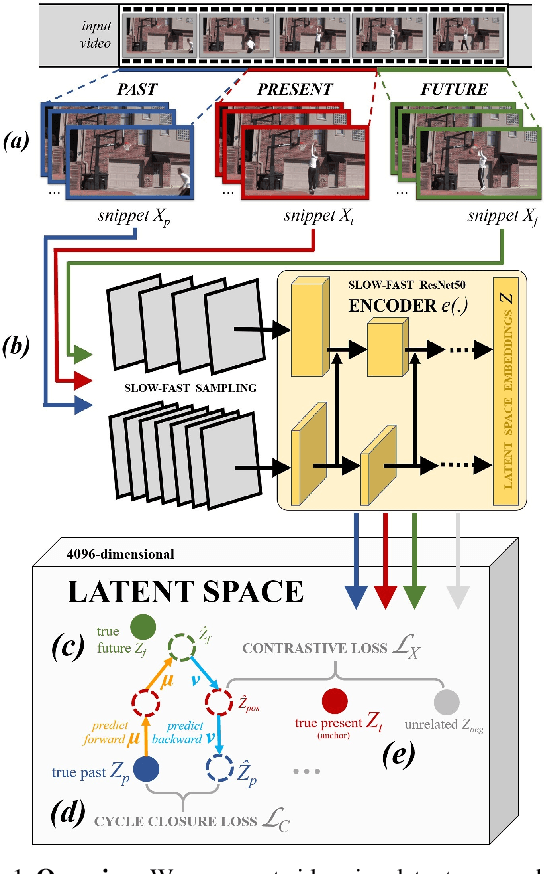
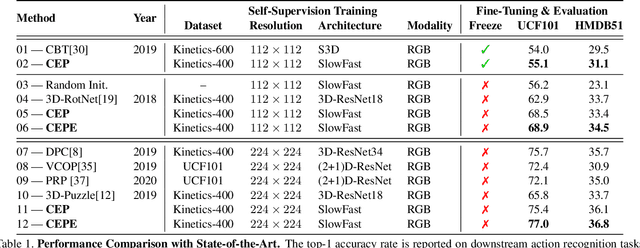

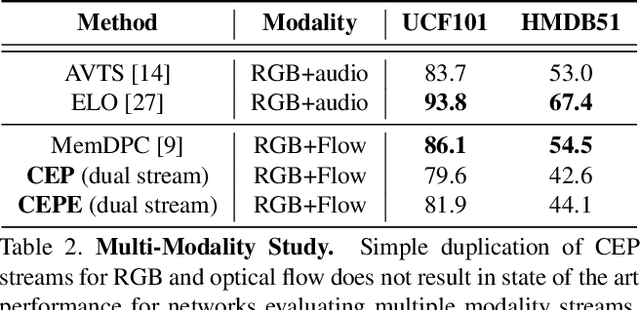
In this paper we show that learning video feature spaces in which temporal cycles are maximally predictable benefits action classification. In particular, we propose a novel learning approach termed Cycle Encoding Prediction (CEP) that is able to effectively represent high-level spatio-temporal structure of unlabelled video content. CEP builds a latent space wherein the concept of closed forward-backward as well as backward-forward temporal loops is approximately preserved. As a self-supervision signal, CEP leverages the bi-directional temporal coherence of the video stream and applies loss functions that encourage both temporal cycle closure as well as contrastive feature separation. Architecturally, the underpinning network structure utilises a single feature encoder for all video snippets, adding two predictive modules that learn temporal forward and backward transitions. We apply our framework for pretext training of networks for action recognition tasks. We report significantly improved results for the standard datasets UCF101 and HMDB51. Detailed ablation studies support the effectiveness of the proposed components. We publish source code for the CEP components in full with this paper.
Meta-Learning with Context-Agnostic Initialisations
Jul 29, 2020
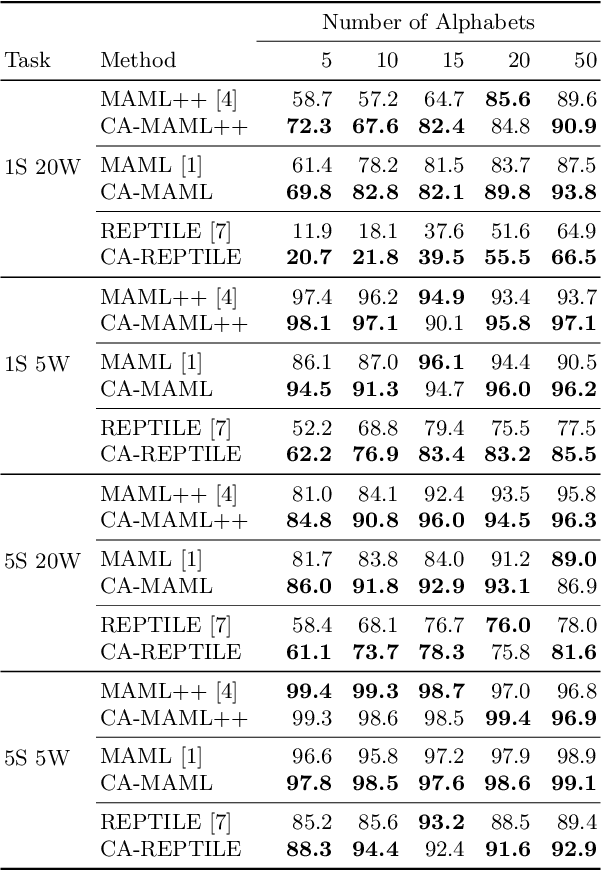
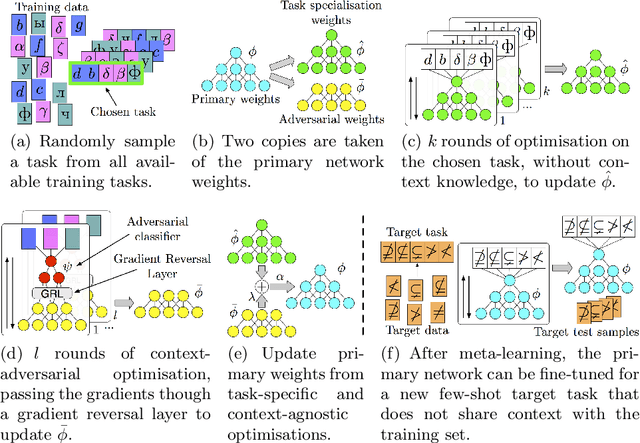
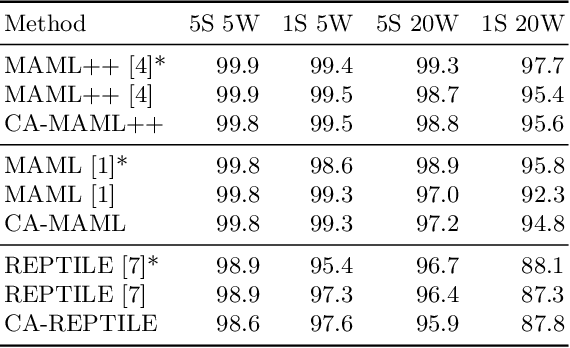
Meta-learning approaches have addressed few-shot problems by finding initialisations suited for fine-tuning to target tasks. Often there are additional properties within training data (which we refer to as context), not relevant to the target task, which act as a distractor to meta-learning, particularly when the target task contains examples from a novel context not seen during training. We address this oversight by incorporating a context-adversarial component into the meta-learning process. This produces an initialisation for fine-tuning to target which is both context-agnostic and task-generalised. We evaluate our approach on three commonly used meta-learning algorithms and two problems. We demonstrate our context-agnostic meta-learning improves results in each case. First, we report on Omniglot few-shot character classification, using alphabets as context. An average improvement of 4.3% is observed across methods and tasks when classifying characters from an unseen alphabet. Second, we evaluate on a dataset for personalised energy expenditure predictions from video, using participant knowledge as context. We demonstrate that context-agnostic meta-learning decreases the average mean square error by 30%.
Visual Identification of Individual Holstein-Friesian Cattle via Deep Metric Learning
Jul 04, 2020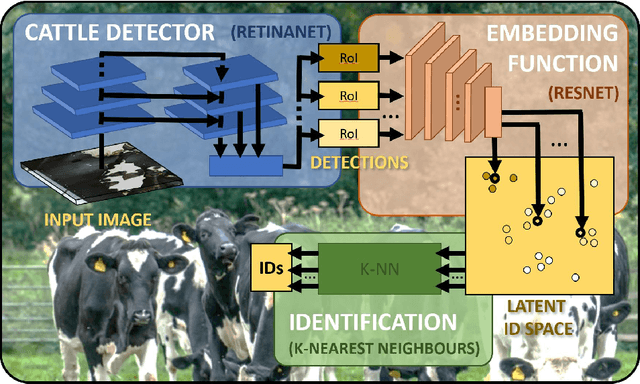
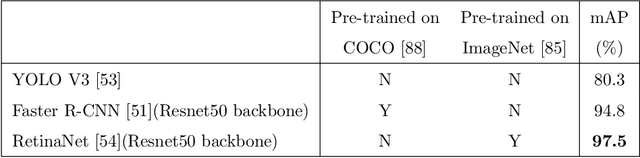
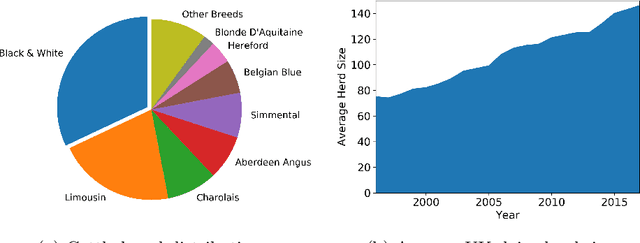

Holstein-Friesian cattle exhibit individually-characteristic black and white coat patterns visually akin to those arising from Turing's reaction-diffusion systems. This work takes advantage of these natural markings in order to automate visual detection and biometric identification of individual Holstein-Friesians via convolutional neural networks and deep metric learning techniques. Existing approaches rely on markings, tags or wearables with a variety of maintenance requirements, whereas we present a totally hands-off method for the automated detection, localisation, and identification of individual animals from overhead imaging in an open herd setting, i.e. where new additions to the herd are identified without re-training. We propose the use of SoftMax-based reciprocal triplet loss to address the identification problem and evaluate the techniques in detail against fixed herd paradigms. We find that deep metric learning systems show strong performance even when many cattle unseen during system training are to be identified and re-identified - achieving 98.2% accuracy when trained on just half of the population. This work paves the way for facilitating the non-intrusive monitoring of cattle applicable to precision farming and surveillance for automated productivity, health and welfare monitoring, and to veterinary research such as behavioural analysis, disease outbreak tracing, and more. Key parts of the source code, network weights and underpinning datasets are available publicly.
Sit-to-Stand Analysis in the Wild using Silhouettes for Longitudinal Health Monitoring
Oct 03, 2019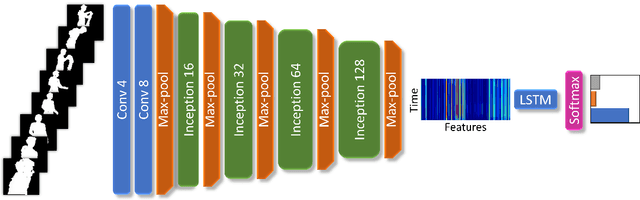

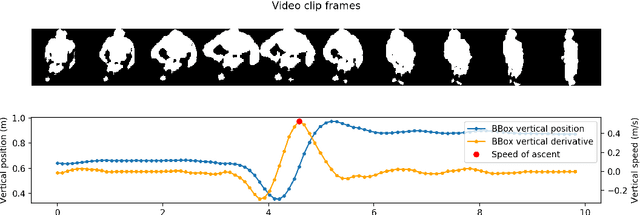

We present the first fully automated Sit-to-Stand or Stand-to-Sit (StS) analysis framework for long-term monitoring of patients in free-living environments using video silhouettes. Our method adopts a coarse-to-fine time localisation approach, where a deep learning classifier identifies possible StS sequences from silhouettes, and a smart peak detection stage provides fine localisation based on 3D bounding boxes. We tested our method on data from real homes of participants and monitored patients undergoing total hip or knee replacement. Our results show 94.4% overall accuracy in the coarse localisation and an error of 0.026 m/s in the speed of ascent measurement, highlighting important trends in the recuperation of patients who underwent surgery.
Great Ape Detection in Challenging Jungle Camera Trap Footage via Attention-Based Spatial and Temporal Feature Blending
Aug 29, 2019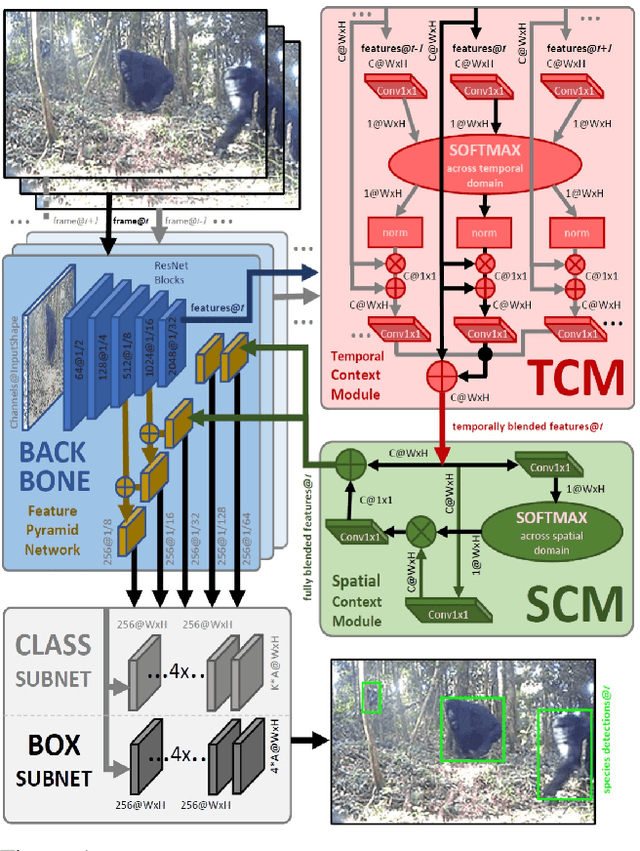
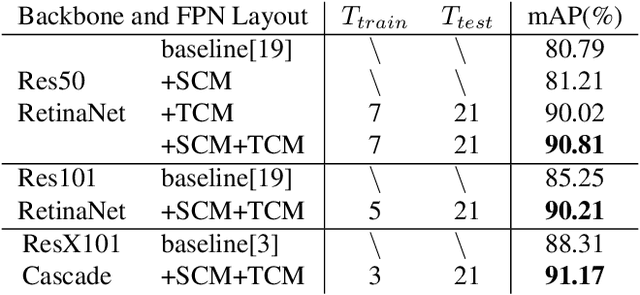

We propose the first multi-frame video object detection framework trained to detect great apes. It is applicable to challenging camera trap footage in complex jungle environments and extends a traditional feature pyramid architecture by adding self-attention driven feature blending in both the spatial as well as the temporal domain. We demonstrate that this extension can detect distinctive species appearance and motion signatures despite significant partial occlusion. We evaluate the framework using 500 camera trap videos of great apes from the Pan African Programme containing 180K frames, which we manually annotated with accurate per-frame animal bounding boxes. These clips contain significant partial occlusions, challenging lighting, dynamic backgrounds, and natural camouflage effects. We show that our approach performs highly robustly and significantly outperforms frame-based detectors. We also perform detailed ablation studies and validation on the full ILSVRC 2015 VID data corpus to demonstrate wider applicability at adequate performance levels. We conclude that the framework is ready to assist human camera trap inspection efforts. We publish code, weights, and ground truth annotations with this paper.
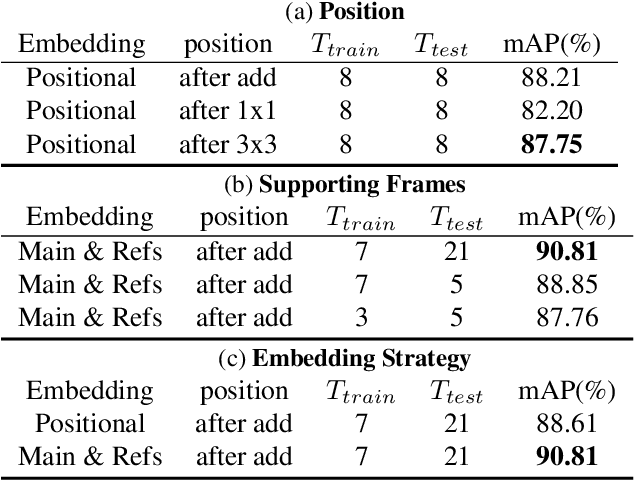
Aerial Animal Biometrics: Individual Friesian Cattle Recovery and Visual Identification via an Autonomous UAV with Onboard Deep Inference
Jul 11, 2019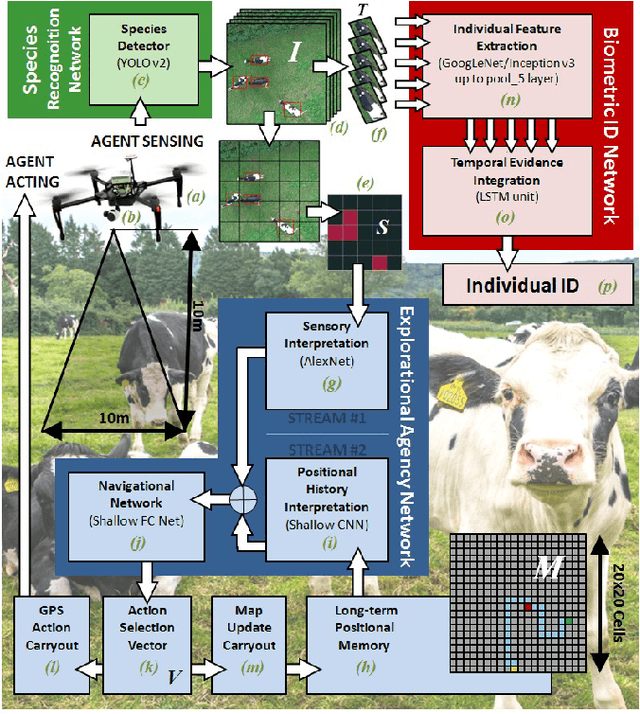
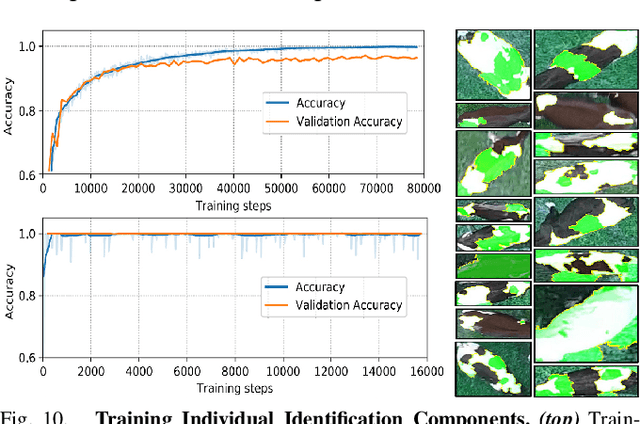
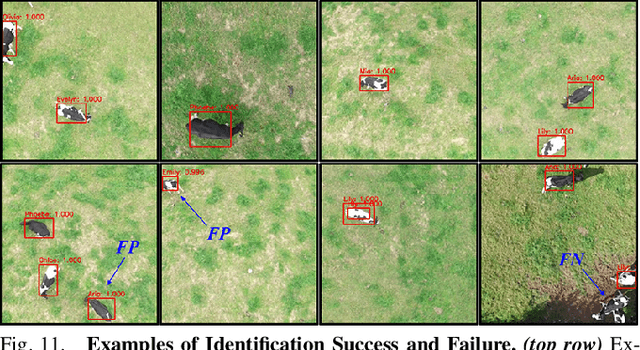
This paper describes a computationally-enhanced M100 UAV platform with an onboard deep learning inference system for integrated computer vision and navigation able to autonomously find and visually identify by coat pattern individual Holstein Friesian cattle in freely moving herds. We propose an approach that utilises three deep convolutional neural network architectures running live onboard the aircraft; that is, a YoloV2-based species detector, a dual-stream CNN delivering exploratory agency and an InceptionV3-based biometric LRCN for individual animal identification. We evaluate the performance of each of the components offline, and also online via real-world field tests comprising 146.7 minutes of autonomous low altitude flight in a farm environment over a dispersed herd of 17 heifer dairy cows. We report error-free identification performance on this online experiment. The presented proof-of-concept system is the first of its kind and a successful step towards autonomous biometric identification of individual animals from the air in open pasture environments for tag-less AI support in farming and ecology.