 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-SwinUNet: Spatio-temporal Deep Learning Framework for VFSS Instance Segmentation
Feb 22, 2023This paper presents a deep learning framework for medical video segmentation. Convolution neural network (CNN) and transformer-based methods have achieved great milestones in medical image segmentation tasks due to their incredible semantic feature encoding and global information comprehension abilities. However, most existing approaches ignore a salient aspect of medical video data - the temporal dimension. Our proposed framework explicitly extracts features from neighbouring frames across the temporal dimension and incorporates them with a temporal feature blender, which then tokenises the high-level spatio-temporal feature to form a strong global feature encoded via a Swin Transformer. The final segmentation results are produced via a UNet-like encoder-decoder architecture. Our model outperforms other approaches by a significant margin and improves the segmentation benchmarks on the VFSS2022 dataset, achieving a dice coefficient of 0.8986 and 0.8186 for the two datasets tested. Our studies also show the efficacy of the temporal feature blending scheme and cross-dataset transferability of learned capabilities. Code and models are fully available at https://github.com/SimonZeng7108/Video-SwinUNet.
Triple-stream Deep Metric Learning of Great Ape Behavioural Actions
Jan 06, 2023



We propose the first metric learning system for the recognition of great ape behavioural actions. Our proposed triple stream embedding architecture works on camera trap videos taken directly in the wild and demonstrates that the utilisation of an explicit DensePose-C chimpanzee body part segmentation stream effectively complements traditional RGB appearance and optical flow streams. We evaluate system variants with different feature fusion techniques and long-tail recognition approaches. Results and ablations show performance improvements of ~12% in top-1 accuracy over previous results achieved on the PanAf-500 dataset containing 180,000 manually annotated frames across nine behavioural actions. Furthermore, we provide a qualitative analysis of our findings and augment the metric learning system with long-tail recognition techniques showing that average per class accuracy -- critical in the domain -- can be improved by ~23% compared to the literature on that dataset. Finally, since our embedding spaces are constructed as metric, we provide first data-driven visualisations of the great ape behavioural action spaces revealing emerging geometry and topology. We hope that the work sparks further interest in this vital application area of computer vision for the benefit of endangered great apes.
Video-TransUNet: Temporally Blended Vision Transformer for CT VFSS Instance Segmentation
Aug 22, 2022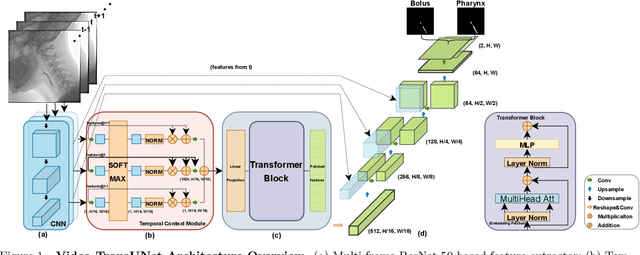
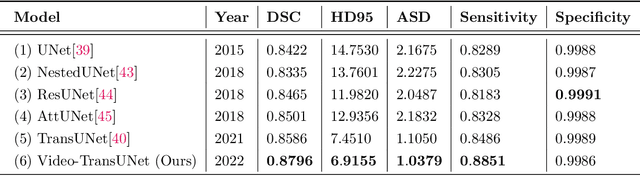


We propose Video-TransUNet, a deep architecture for instance segmentation in medical CT videos constructed by integrating temporal feature blending into the TransUNet deep learning framework. In particular, our approach amalgamates strong frame representation via a ResNet CNN backbone, multi-frame feature blending via a Temporal Context Module (TCM), non-local attention via a Vision Transformer, and reconstructive capabilities for multiple targets via a UNet-based convolutional-deconvolutional architecture with multiple heads. We show that this new network design can significantly outperform other state-of-the-art systems when tested on the segmentation of bolus and pharynx/larynx in Videofluoroscopic Swallowing Study (VFSS) CT sequences. On our VFSS2022 dataset it achieves a dice coefficient of 0.8796 and an average surface distance of 1.0379 pixels. Note that tracking the pharyngeal bolus accurately is a particularly important application in clinical practice since it constitutes the primary method for diagnostics of swallowing impairment. Our findings suggest that the proposed model can indeed enhance the TransUNet architecture via exploiting temporal information and improving segmentation performance by a significant margin. We publish key source code, network weights, and ground truth annotations for simplified performance reproduction.
Inertial Hallucinations -- When Wearable Inertial Devices Start Seeing Things
Jul 14, 2022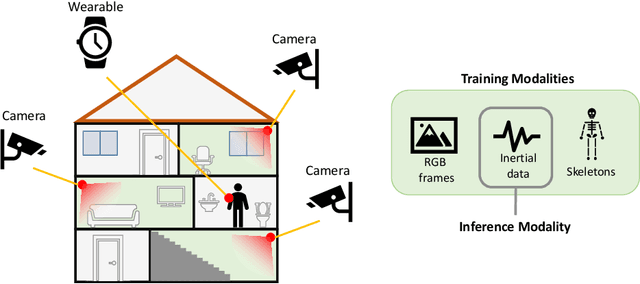

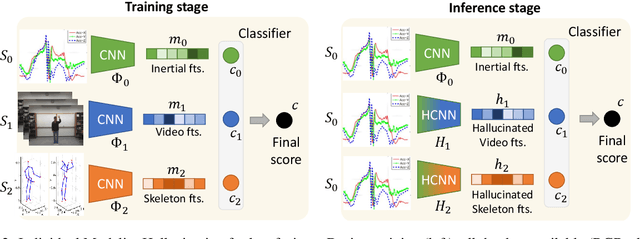
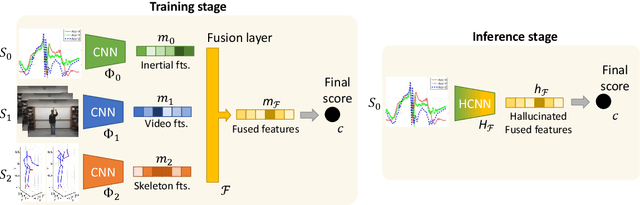
We propose a novel approach to multimodal sensor fusion for Ambient Assisted Living (AAL) which takes advantage of learning using privileged information (LUPI). We address two major shortcomings of standard multimodal approaches, limited area coverage and reduced reliability. Our new framework fuses the concept of modality hallucination with triplet learning to train a model with different modalities to handle missing sensors at inference time. We evaluate the proposed model on inertial data from a wearable accelerometer device, using RGB videos and skeletons as privileged modalities, and show an improvement of accuracy of an average 6.6% on the UTD-MHAD dataset and an average 5.5% on the Berkeley MHAD dataset, reaching a new state-of-the-art for inertial-only classification accuracy on these datasets. We validate our framework through several ablation studies.
Towards Individual Grevy's Zebra Identification via Deep 3D Fitting and Metric Learning
Jun 07, 2022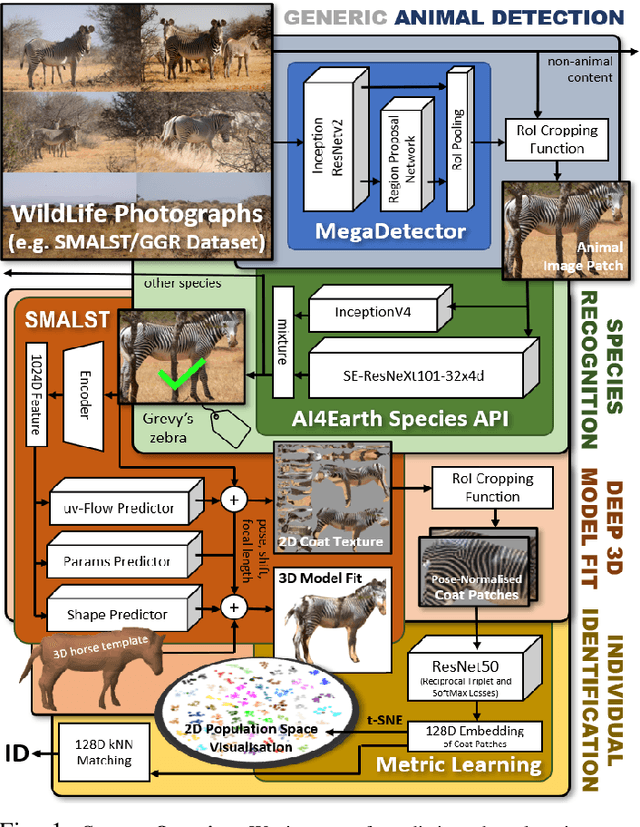
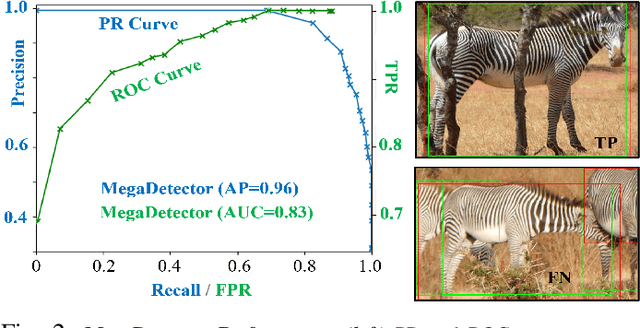

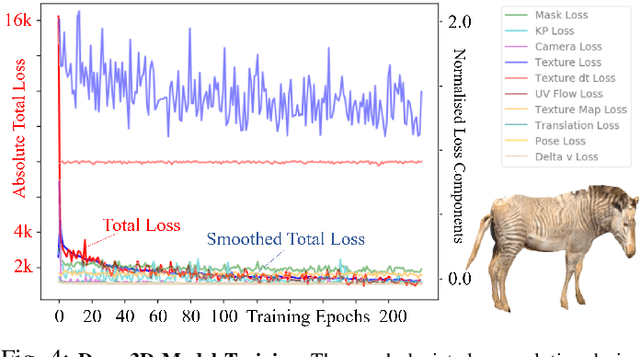
This paper combines deep learning techniques for species detection, 3D model fitting, and metric learning in one pipeline to perform individual animal identification from photographs by exploiting unique coat patterns. This is the first work to attempt this and, compared to traditional 2D bounding box or segmentation based CNN identification pipelines, the approach provides effective and explicit view-point normalisation and allows for a straight forward visualisation of the learned biometric population space. Note that due to the use of metric learning the pipeline is also readily applicable to open set and zero shot re-identification scenarios. We apply the proposed approach to individual Grevy's zebra (Equus grevyi) identification and show in a small study on the SMALST dataset that the use of 3D model fitting can indeed benefit performance. In particular, back-projected textures from 3D fitted models improve identification accuracy from 48.0% to 56.8% compared to 2D bounding box approaches for the dataset. Whilst the study is far too small accurately to estimate the full performance potential achievable in larger-scale real-world application settings and in comparisons against polished tools, our work lays the conceptual and practical foundations for a next step in animal biometrics towards deep metric learning driven, fully 3D-aware animal identification in open population settings. We publish network weights and relevant facilitating source code with this paper for full reproducibility and as inspiration for further research.
Dynamic Curriculum Learning for Great Ape Detection in the Wild
Apr 30, 2022
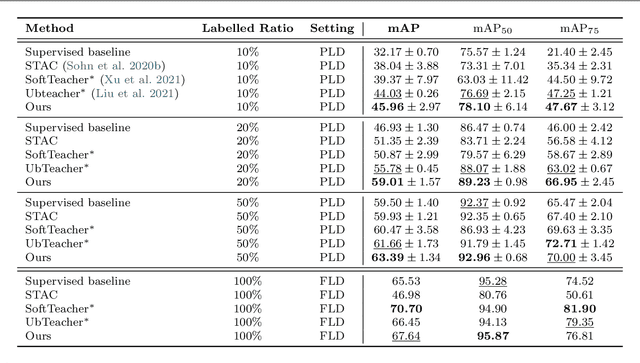
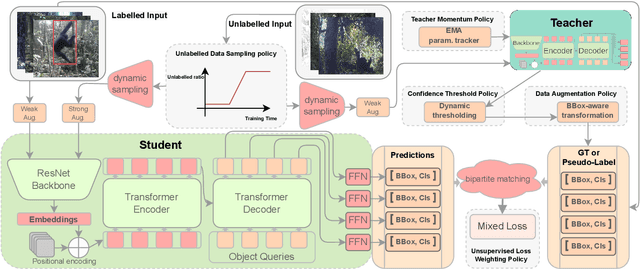
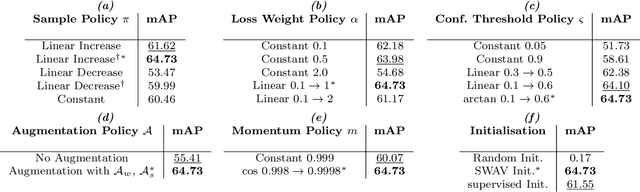
We propose a novel end-to-end curriculum learning approach that leverages large volumes of unlabelled great ape camera trap footage to improve supervised species detector construction in challenging real-world jungle environments. In contrast to previous semi-supervised methods, our approach gradually improves detection quality by steering training towards virtuous self-reinforcement. To achieve this, we propose integrating pseudo-labelling with dynamic curriculum learning policies. We show that such dynamics and controls can avoid learning collapse and gradually tie detector adjustments to higher model quality. We provide theoretical arguments and ablations, and confirm significant performance improvements against various state-of-the-art systems when evaluating on the Extended PanAfrican Dataset holding several thousand camera trap videos of great apes. We note that system performance is strongest for smaller labelled ratios, which are common in ecological applications. Our approach, although designed with wildlife data in mind, also shows competitive benchmarks for generic object detection in the MS-COCO dataset, indicating wider applicability of introduced concepts. The code is available at https://github.com/youshyee/DCL-Detection.
Label a Herd in Minutes: Individual Holstein-Friesian Cattle Identification
Apr 22, 2022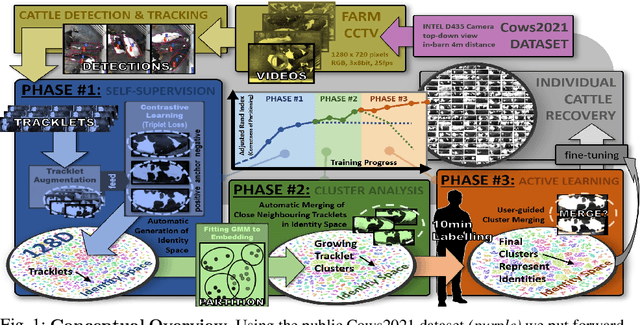


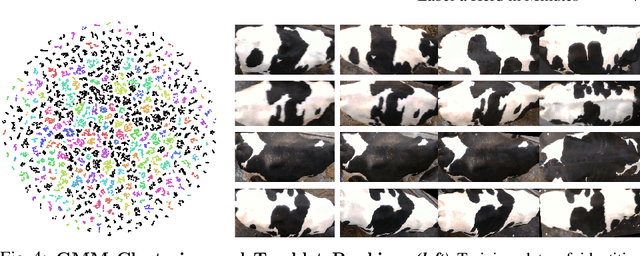
We describe a practically evaluated approach for training visual cattle ID systems for a whole farm requiring only ten minutes of labelling effort. In particular, for the task of automatic identification of individual Holstein-Friesians in real-world farm CCTV, we show that self-supervision, metric learning, cluster analysis, and active learning can complement each other to significantly reduce the annotation requirements usually needed to train cattle identification frameworks. Evaluating the approach on the test portion of the publicly available Cows2021 dataset, for training we use 23,350 frames across 435 single individual tracklets generated by automated oriented cattle detection and tracking in operational farm footage. Self-supervised metric learning is first employed to initialise a candidate identity space where each tracklet is considered a distinct entity. Grouping entities into equivalence classes representing cattle identities is then performed by automated merging via cluster analysis and active learning. Critically, we identify the inflection point at which automated choices cannot replicate improvements based on human intervention to reduce annotation to a minimum. Experimental results show that cluster analysis and a few minutes of labelling after automated self-supervision can improve the test identification accuracy of 153 identities to 92.44% (ARI=0.93) from the 74.9% (ARI=0.754) obtained by self-supervision only. These promising results indicate that a tailored combination of human and machine reasoning in visual cattle ID pipelines can be highly effective whilst requiring only minimal labelling effort. We provide all key source code and network weights with this paper for easy result reproduction.
Visual Microfossil Identification via Deep Metric Learning
Jan 04, 2022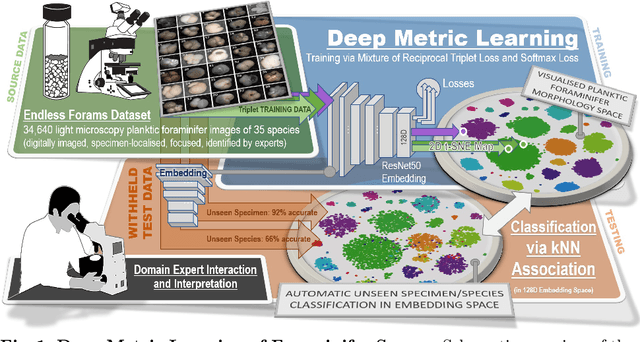
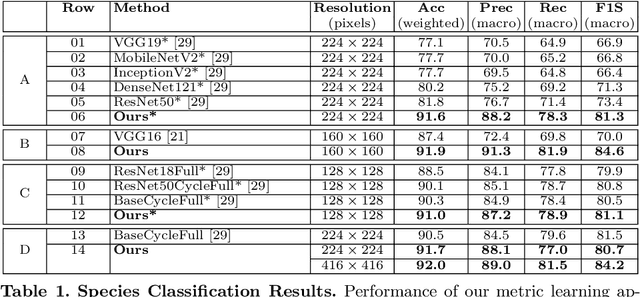
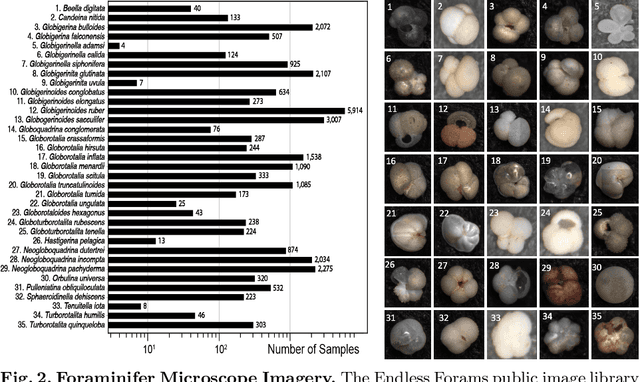
We apply deep metric learning for the first time to the prob-lem of classifying planktic foraminifer shells on microscopic images. This species recognition task is an important information source and scientific pillar for reconstructing past climates. All foraminifer CNN recognition pipelines in the literature produce black-box classifiers that lack visualisation options for human experts and cannot be applied to open set problems. Here, we benchmark metric learning against these pipelines, produce the first scientific visualisation of the phenotypic planktic foraminifer morphology space, and demonstrate that metric learning can be used to cluster species unseen during training. We show that metric learning out-performs all published CNN-based state-of-the-art benchmarks in this domain. We evaluate our approach on the 34,640 expert-annotated images of the Endless Forams public library of 35 modern planktic foraminifera species. Our results on this data show leading 92% accuracy (at 0.84 F1-score) in reproducing expert labels on withheld test data, and 66.5% accuracy (at 0.70 F1-score) when clustering species never encountered in training. We conclude that metric learning is highly effective for this domain and serves as an important tool towards expert-in-the-loop automation of microfossil identification. Key code, network weights, and data splits are published with this paper for full reproducibility.
Small or Far Away? Exploiting Deep Super-Resolution and Altitude Data for Aerial Animal Surveillance
Nov 12, 2021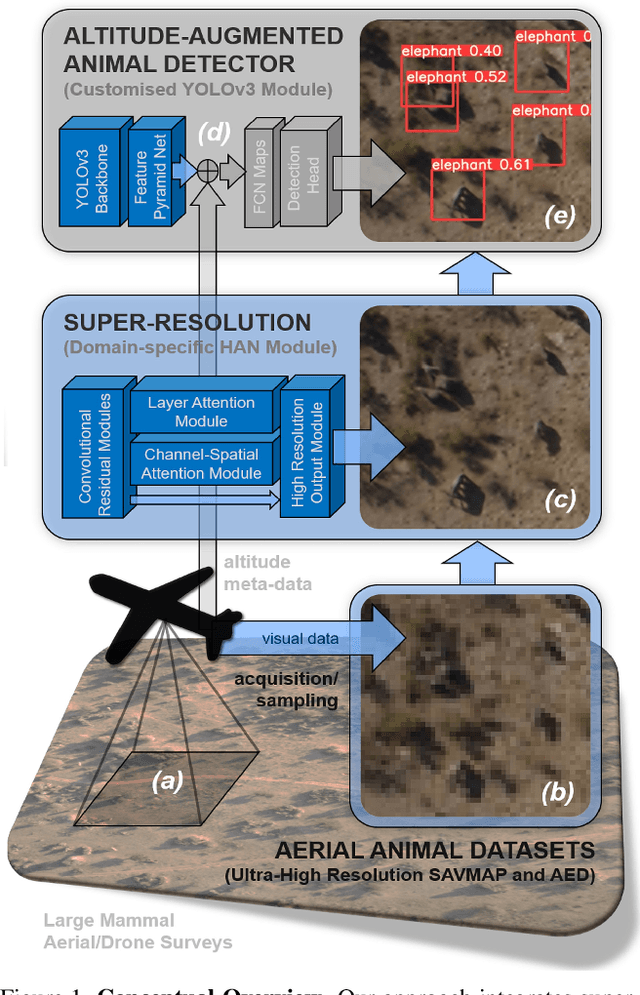
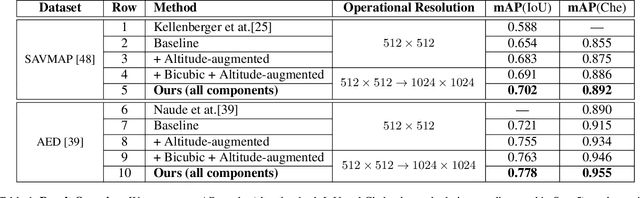

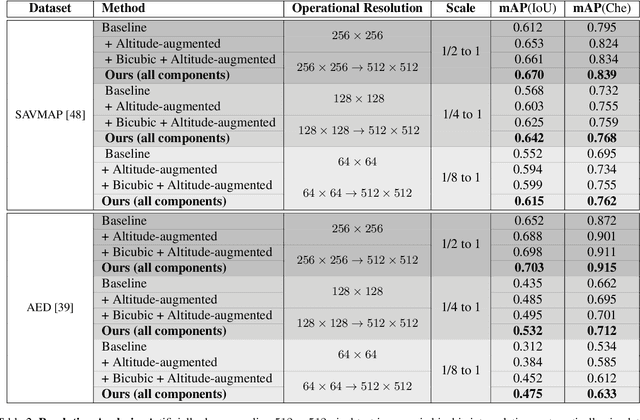
Visuals captured by high-flying aerial drones are increasingly used to assess biodiversity and animal population dynamics around the globe. Yet, challenging acquisition scenarios and tiny animal depictions in airborne imagery, despite ultra-high resolution cameras, have so far been limiting factors for applying computer vision detectors successfully with high confidence. In this paper, we address the problem for the first time by combining deep object detectors with super-resolution techniques and altitude data. In particular, we show that the integration of a holistic attention network based super-resolution approach and a custom-built altitude data exploitation network into standard recognition pipelines can considerably increase the detection efficacy in real-world settings. We evaluate the system on two public, large aerial-capture animal datasets, SAVMAP and AED. We find that the proposed approach can consistently improve over ablated baselines and the state-of-the-art performance for both datasets. In addition, we provide a systematic analysis of the relationship between animal resolution and detection performance. We conclude that super-resolution and altitude knowledge exploitation techniques can significantly increase benchmarks across settings and, thus, should be used routinely when detecting minutely resolved animals in aerial imagery.
Seeing biodiversity: perspectives in machine learning for wildlife conservation
Oct 25, 2021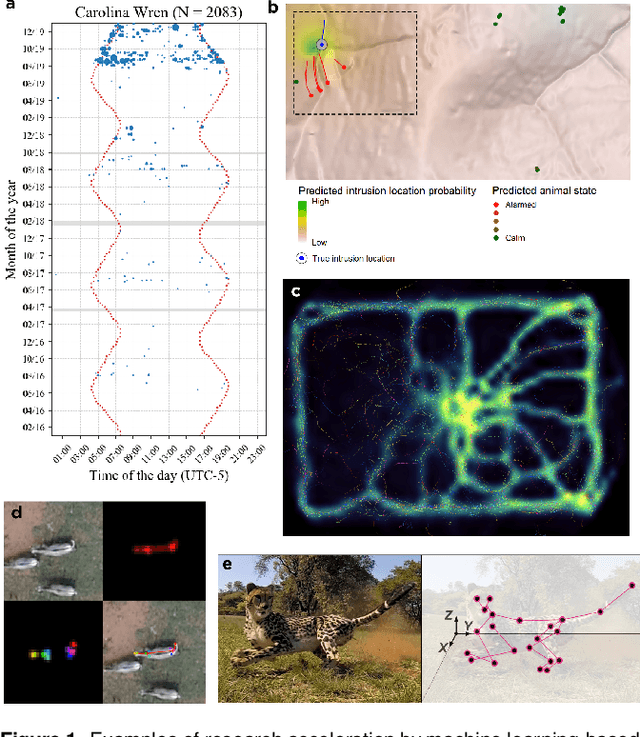
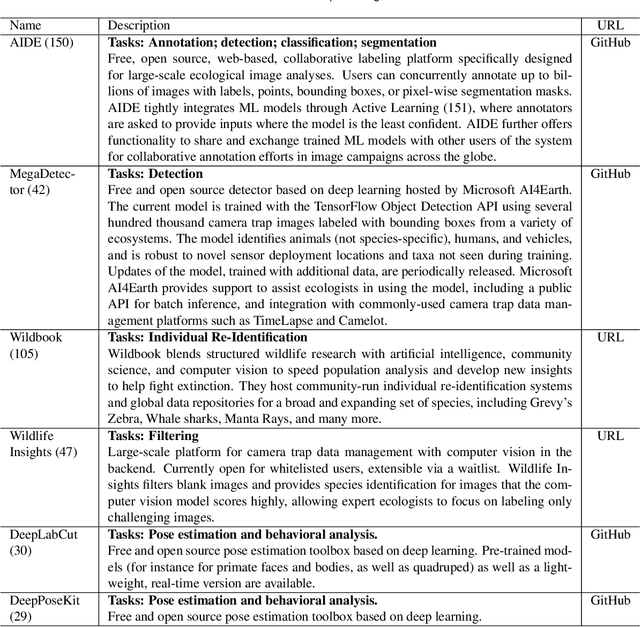

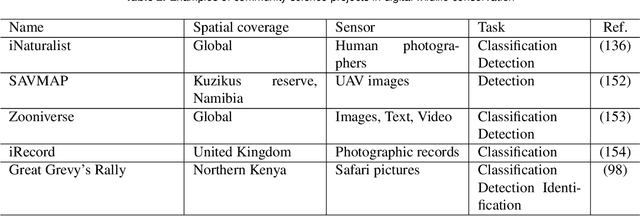
Data acquisition in animal ecology is rapidly accelerating due to inexpensive and accessible sensors such as smartphones, drones, satellites, audio recorders and bio-logging devices. These new technologies and the data they generate hold great potential for large-scale environmental monitoring and understanding, but are limited by current data processing approaches which are inefficient in how they ingest, digest, and distill data into relevant information. We argue that machine learning, and especially deep learning approaches, can meet this analytic challenge to enhance our understanding, monitoring capacity, and conservation of wildlife species. Incorporating machine learning into ecological workflows could improve inputs for population and behavior models and eventually lead to integrated hybrid modeling tools, with ecological models acting as constraints for machine learning models and the latter providing data-supported insights. In essence, by combining new machine learning approaches with ecological domain knowledge, animal ecologists can capitalize on the abundance of data generated by modern sensor technologies in order to reliably estimate population abundances, study animal behavior and mitigate human/wildlife conflicts. To succeed, this approach will require close collaboration and cross-disciplinary education between the computer science and animal ecology communities in order to ensure the quality of machine learning approaches and train a new generation of data scientists in ecology and conservation.