 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusing in the Right Space: A Systematic Study of Latent Diffusability
Jun 02, 2026Latent diffusion models leverage visual tokenizers to compress images into latent spaces for efficient generative modeling. However, better reconstruction quality of a tokenizer does not necessarily translate into better generation quality, suggesting that latent representations should be evaluated not only by fidelity but also by their diffusability. Recent studies have proposed diverse explanations for diffusion-friendly latent spaces, including semantic separability, affine equivariance, distribution uniformity, spatial structure, spectral smoothness, and manifold continuity. Yet these properties are often validated on a limited set of tokenizers, leaving it unclear which factors are most predictive of downstream generation quality and whether such conclusions hold beyond the specific settings in which they are introduced. In this work, we conduct a systematic study of latent diffusability by training a large collection of tokenizers with diverse regularization strategies, architectures, and latent configurations, and evaluating them with multiple downstream diffusion backbones. Our analysis identifies several latent properties that consistently correlate with generation quality and exhibit strong generalization across experimental settings. Beyond existing metrics, we introduce Velocity Irreducible Variance (VIV), a measure of velocity ambiguity induced by trajectory crossings. Extensive experiments show that VIV is one of the most stable predictors of generation quality.
VLMs are Good Teachers for Video Reasoning via Adaptive Test-Time Optimization
Jun 01, 2026The recent "Reasoning with Video" paradigm utilizes Video Generation Models (VGMs) to generate temporally coherent visual trajectories to complete reasoning tasks. Although state-of-the-art VGMs excel at visual quality, they often struggle to understand and follow task-specific rules, leading to logical failures across diverse reasoning scenarios. Existing efforts try to utilize Vision-Language Models (VLMs) as problem pre-solvers to produce or refine textual guidance for the VGM. However, textual descriptions fail to capture intricate spatiotemporal details, and VGMs often struggle to faithfully execute fine-grained or long-tail instructions even with a valid plan. While VLMs struggle as solvers, they possess strong perception capabilities to evaluate process-constraint satisfaction and final-goal achievement. Leveraging this strength, we introduce a paradigm shift that transitions the role of VLMs to "teachers". Specifically, a VLM teacher extracts task-specific rules to formulate differentiable rewards, guiding a VGM Reasoner via test-time online optimization of a lightweight LoRA module. This strategy enables adaptive test-time optimization and extends the reasoning capabilities beyond the VGM's intrinsic boundaries. Evaluations on symbolic (VBVR-Bench) and general-purpose (RULER-Bench) video reasoning benchmarks show that the proposed method yields a 16.7-point average performance gain, outperforming the VLM-as-Solver paradigm (+0.4 points) and Best-of-N scaling (+2.2 points) by a large margin at comparable test-time cost. These findings reveal that integrating VLMs as test-time teachers offers a promising paradigm for achieving generalizable video reasoning. Project Page: https://VLM-as-Teacher.github.io/
VFRTok: Variable Frame Rates Video Tokenizer with Duration-Proportional Information Assumption
May 17, 2025



Modern video generation frameworks based on Latent Diffusion Models suffer from inefficiencies in tokenization due to the Frame-Proportional Information Assumption. Existing tokenizers provide fixed temporal compression rates, causing the computational cost of the diffusion model to scale linearly with the frame rate. The paper proposes the Duration-Proportional Information Assumption: the upper bound on the information capacity of a video is proportional to the duration rather than the number of frames. Based on this insight, the paper introduces VFRTok, a Transformer-based video tokenizer, that enables variable frame rate encoding and decoding through asymmetric frame rate training between the encoder and decoder. Furthermore, the paper proposes Partial Rotary Position Embeddings (RoPE) to decouple position and content modeling, which groups correlated patches into unified tokens. The Partial RoPE effectively improves content-awareness, enhancing the video generation capability. Benefiting from the compact and continuous spatio-temporal representation, VFRTok achieves competitive reconstruction quality and state-of-the-art generation fidelity while using only 1/8 tokens compared to existing tokenizers.
VIVID-10M: A Dataset and Baseline for Versatile and Interactive Video Local Editing
Nov 22, 2024



Diffusion-based image editing models have made remarkable progress in recent years. However, achieving high-quality video editing remains a significant challenge. One major hurdle is the absence of open-source, large-scale video editing datasets based on real-world data, as constructing such datasets is both time-consuming and costly. Moreover, video data requires a significantly larger number of tokens for representation, which substantially increases the training costs for video editing models. Lastly, current video editing models offer limited interactivity, often making it difficult for users to express their editing requirements effectively in a single attempt. To address these challenges, this paper introduces a dataset VIVID-10M and a baseline model VIVID. VIVID-10M is the first large-scale hybrid image-video local editing dataset aimed at reducing data construction and model training costs, which comprises 9.7M samples that encompass a wide range of video editing tasks. VIVID is a Versatile and Interactive VIdeo local eDiting model trained on VIVID-10M, which supports entity addition, modification, and deletion. At its core, a keyframe-guided interactive video editing mechanism is proposed, enabling users to iteratively edit keyframes and propagate it to other frames, thereby reducing latency in achieving desired outcomes. Extensive experimental evaluations show that our approach achieves state-of-the-art performance in video local editing, surpassing baseline methods in both automated metrics and user studies. The VIVID-10M dataset and the VIVID editing model will be available at \url{https://inkosizhong.github.io/VIVID/}.
Preprocessing Enhanced Image Compression for Machine Vision
Jun 12, 2022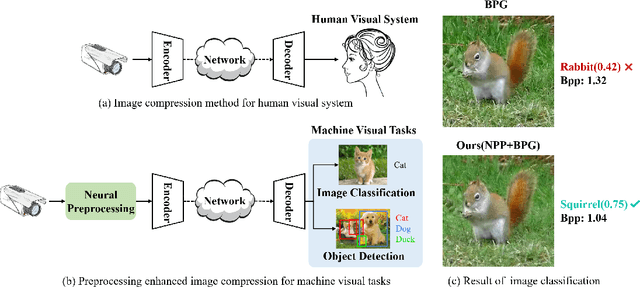
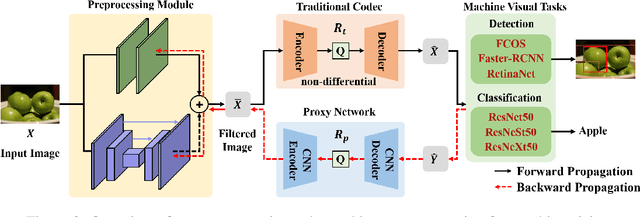
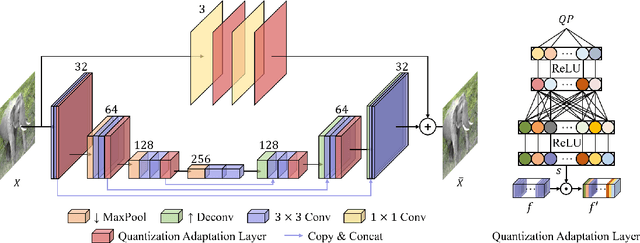
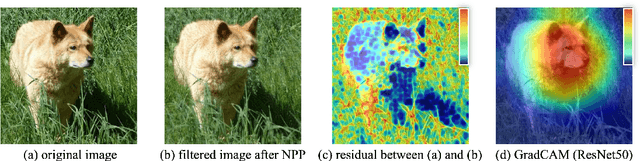
Recently, more and more images are compressed and sent to the back-end devices for the machine analysis tasks~(\textit{e.g.,} object detection) instead of being purely watched by humans. However, most traditional or learned image codecs are designed to minimize the distortion of the human visual system without considering the increased demand from machine vision systems. In this work, we propose a preprocessing enhanced image compression method for machine vision tasks to address this challenge. Instead of relying on the learned image codecs for end-to-end optimization, our framework is built upon the traditional non-differential codecs, which means it is standard compatible and can be easily deployed in practical applications. Specifically, we propose a neural preprocessing module before the encoder to maintain the useful semantic information for the downstream tasks and suppress the irrelevant information for bitrate saving. Furthermore, our neural preprocessing module is quantization adaptive and can be used in different compression ratios. More importantly, to jointly optimize the preprocessing module with the downstream machine vision tasks, we introduce the proxy network for the traditional non-differential codecs in the back-propagation stage. We provide extensive experiments by evaluating our compression method for two representative downstream tasks with different backbone networks. Experimental results show our method achieves a better trade-off between the coding bitrate and the performance of the downstream machine vision tasks by saving about 20% bitrate.