 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
Making History Matter: History-Advantage Sequence Training for Visual Dialog
Apr 17, 2019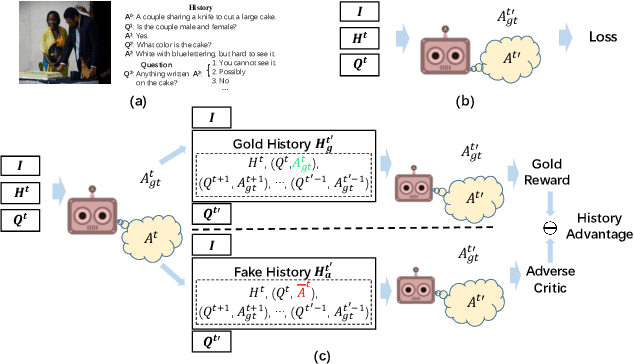
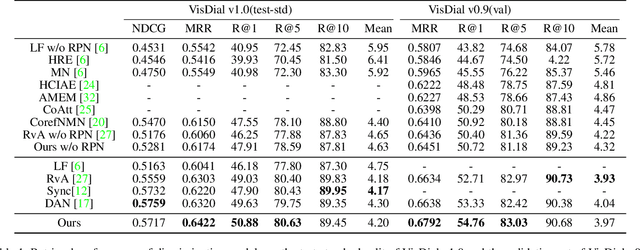
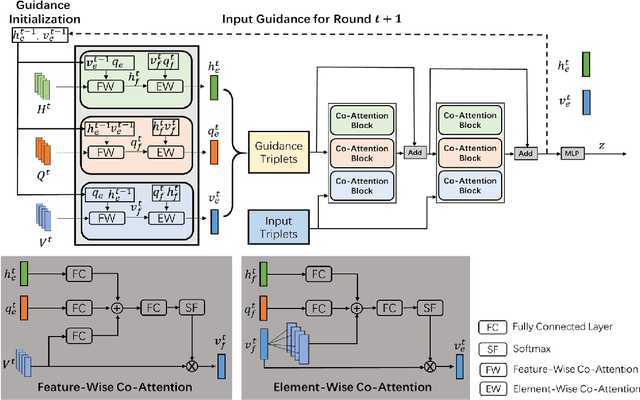
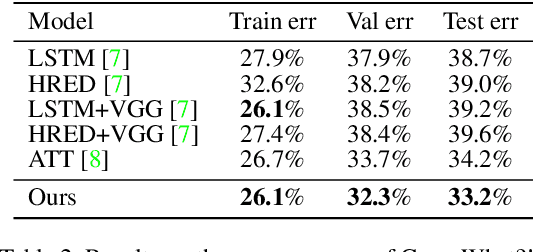
We study the multi-round response generation in visual dialog, where a response is generated according to a visually grounded conversational history. Given a triplet: an image, Q&A history, and current question, all the prevailing methods follow a codec (i.e., encoder-decoder) fashion in a supervised learning paradigm: a multimodal encoder encodes the triplet into a feature vector, which is then fed into the decoder for the current answer generation, supervised by the ground-truth. However, this conventional supervised learning does NOT take into account the impact of imperfect history, violating the conversational nature of visual dialog and thus making the codec more inclined to learn history bias but not contextual reasoning. To this end, inspired by the actor-critic policy gradient in reinforcement learning, we propose a novel training paradigm called History Advantage Sequence Training (HAST). Specifically, we intentionally impose wrong answers in the history, obtaining an adverse critic, and see how the historic error impacts the codec's future behavior by History Advantage-a quantity obtained by subtracting the adverse critic from the gold reward of ground-truth history. Moreover, to make the codec more sensitive to the history, we propose a novel attention network called History-Aware Co-Attention Network (HACAN) which can be effectively trained by using HAST. Experimental results on three benchmarks: VisDial v0.9&v1.0 and GuessWhat?!, show that the proposed HAST strategy consistently outperforms the state-of-the-art supervised counterparts.