 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisibility-aware Multi-view Stereo Network
Aug 19, 2020
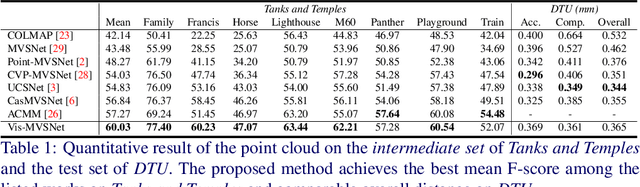
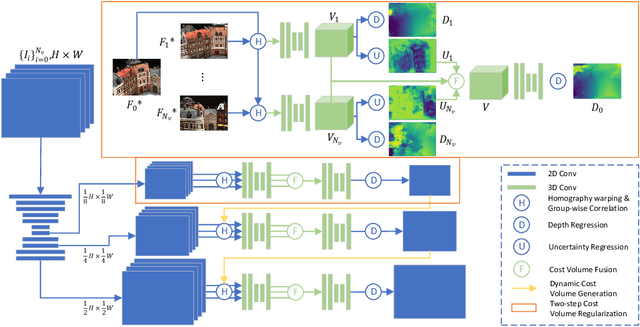
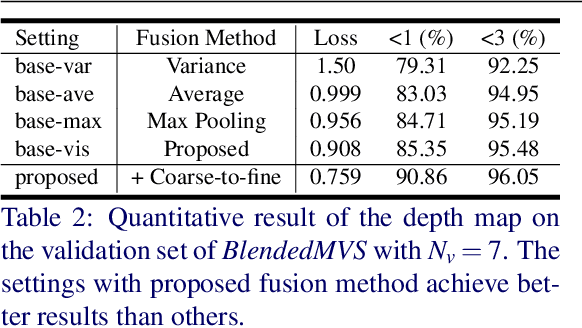
Learning-based multi-view stereo (MVS) methods have demonstrated promising results. However, very few existing networks explicitly take the pixel-wise visibility into consideration, resulting in erroneous cost aggregation from occluded pixels. In this paper, we explicitly infer and integrate the pixel-wise occlusion information in the MVS network via the matching uncertainty estimation. The pair-wise uncertainty map is jointly inferred with the pair-wise depth map, which is further used as weighting guidance during the multi-view cost volume fusion. As such, the adverse influence of occluded pixels is suppressed in the cost fusion. The proposed framework Vis-MVSNet significantly improves depth accuracies in the scenes with severe occlusion. Extensive experiments are performed on DTU, BlendedMVS, and Tanks and Temples datasets to justify the effectiveness of the proposed framework.
Learning Stereo Matchability in Disparity Regression Networks
Aug 11, 2020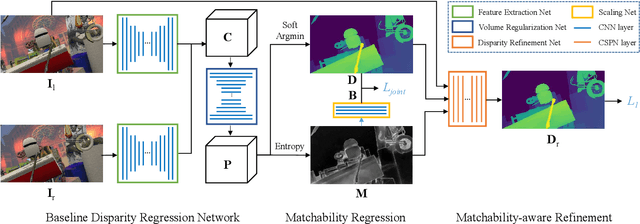

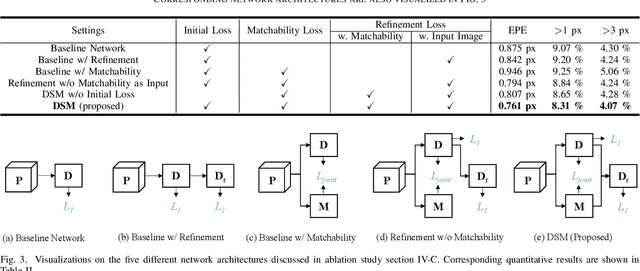

Learning-based stereo matching has recently achieved promising results, yet still suffers difficulties in establishing reliable matches in weakly matchable regions that are textureless, non-Lambertian, or occluded. In this paper, we address this challenge by proposing a stereo matching network that considers pixel-wise matchability. Specifically, the network jointly regresses disparity and matchability maps from 3D probability volume through expectation and entropy operations. Next, a learned attenuation is applied as the robust loss function to alleviate the influence of weakly matchable pixels in the training. Finally, a matchability-aware disparity refinement is introduced to improve the depth inference in weakly matchable regions. The proposed deep stereo matchability (DSM) framework can improve the matching result or accelerate the computation while still guaranteeing the quality. Moreover, the DSM framework is portable to many recent stereo networks. Extensive experiments are conducted on Scene Flow and KITTI stereo datasets to demonstrate the effectiveness of the proposed framework over the state-of-the-art learning-based stereo methods.
Learning Discriminative Feature with CRF for Unsupervised Video Object Segmentation
Aug 04, 2020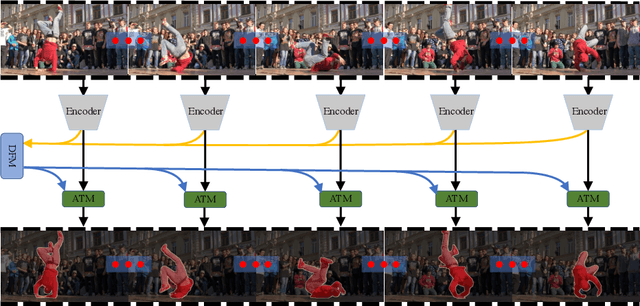
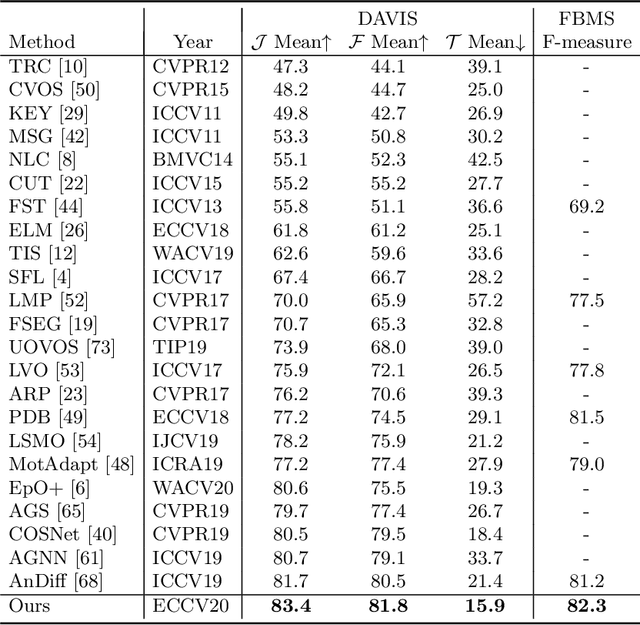
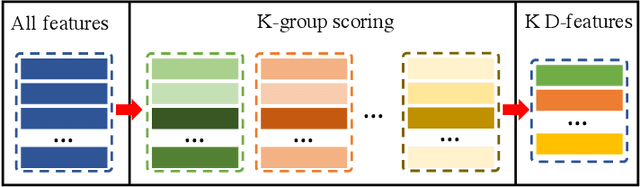
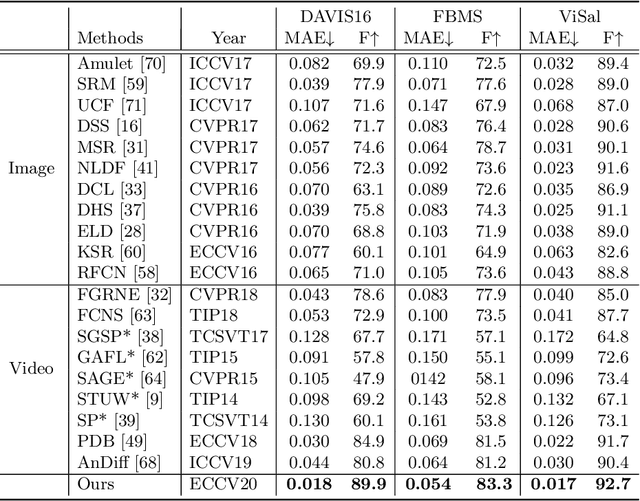
In this paper, we introduce a novel network, called discriminative feature network (DFNet), to address the unsupervised video object segmentation task. To capture the inherent correlation among video frames, we learn discriminative features (D-features) from the input images that reveal feature distribution from a global perspective. The D-features are then used to establish correspondence with all features of test image under conditional random field (CRF) formulation, which is leveraged to enforce consistency between pixels. The experiments verify that DFNet outperforms state-of-the-art methods by a large margin with a mean IoU score of 83.4% and ranks first on the DAVIS-2016 leaderboard while using much fewer parameters and achieving much more efficient performance in the inference phase. We further evaluate DFNet on the FBMS dataset and the video saliency dataset ViSal, reaching a new state-of-the-art. To further demonstrate the generalizability of our framework, DFNet is also applied to the image object co-segmentation task. We perform experiments on a challenging dataset PASCAL-VOC and observe the superiority of DFNet. The thorough experiments verify that DFNet is able to capture and mine the underlying relations of images and discover the common foreground objects.
Stochastic Bundle Adjustment for Efficient and Scalable 3D Reconstruction
Aug 02, 2020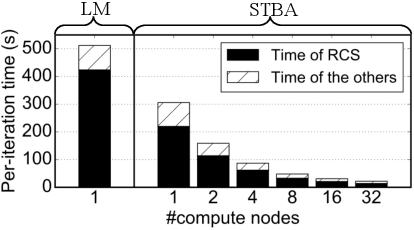
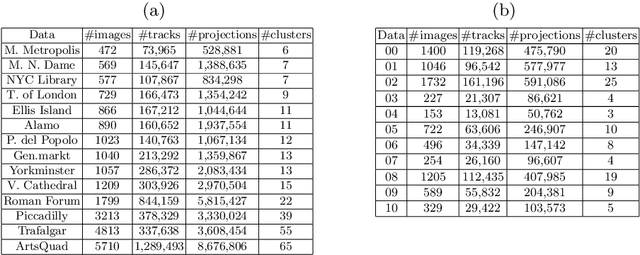
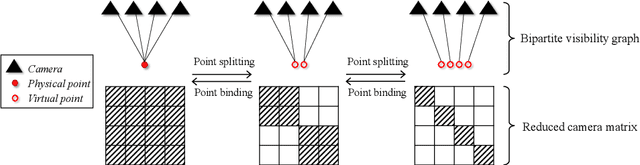

Current bundle adjustment solvers such as the Levenberg-Marquardt (LM) algorithm are limited by the bottleneck in solving the Reduced Camera System (RCS) whose dimension is proportional to the camera number. When the problem is scaled up, this step is neither efficient in computation nor manageable for a single compute node. In this work, we propose a stochastic bundle adjustment algorithm which seeks to decompose the RCS approximately inside the LM iterations to improve the efficiency and scalability. It first reformulates the quadratic programming problem of an LM iteration based on the clustering of the visibility graph by introducing the equality constraints across clusters. Then, we propose to relax it into a chance constrained problem and solve it through sampled convex program. The relaxation is intended to eliminate the interdependence between clusters embodied by the constraints, so that a large RCS can be decomposed into independent linear sub-problems. Numerical experiments on unordered Internet image sets and sequential SLAM image sets, as well as distributed experiments on large-scale datasets, have demonstrated the high efficiency and scalability of the proposed approach. Codes are released at https://github.com/zlthinker/STBA.
Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency
Jul 24, 2020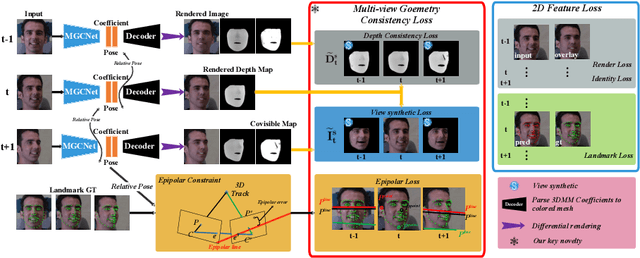
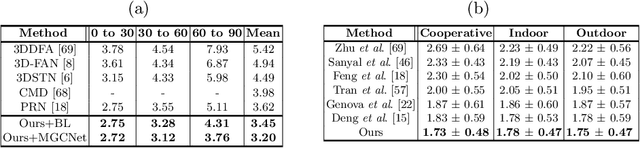

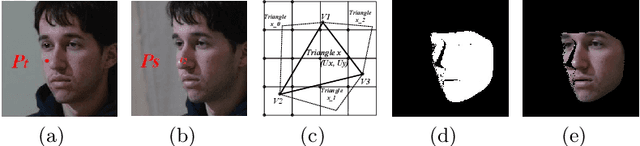
Recent learning-based approaches, in which models are trained by single-view images have shown promising results for monocular 3D face reconstruction, but they suffer from the ill-posed face pose and depth ambiguity issue. In contrast to previous works that only enforce 2D feature constraints, we propose a self-supervised training architecture by leveraging the multi-view geometry consistency, which provides reliable constraints on face pose and depth estimation. We first propose an occlusion-aware view synthesis method to apply multi-view geometry consistency to self-supervised learning. Then we design three novel loss functions for multi-view consistency, including the pixel consistency loss, the depth consistency loss, and the facial landmark-based epipolar loss. Our method is accurate and robust, especially under large variations of expressions, poses, and illumination conditions. Comprehensive experiments on the face alignment and 3D face reconstruction benchmarks have demonstrated superiority over state-of-the-art methods. Our code and model are released in https://github.com/jiaxiangshang/MGCNet.
ASLFeat: Learning Local Features of Accurate Shape and Localization
Apr 19, 2020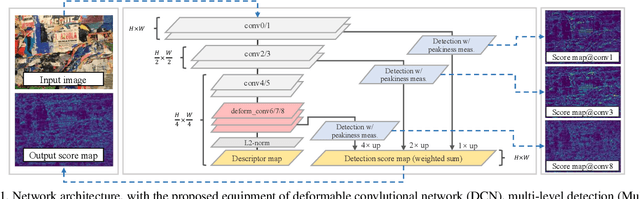

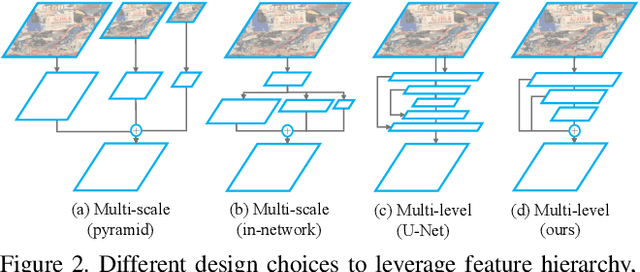
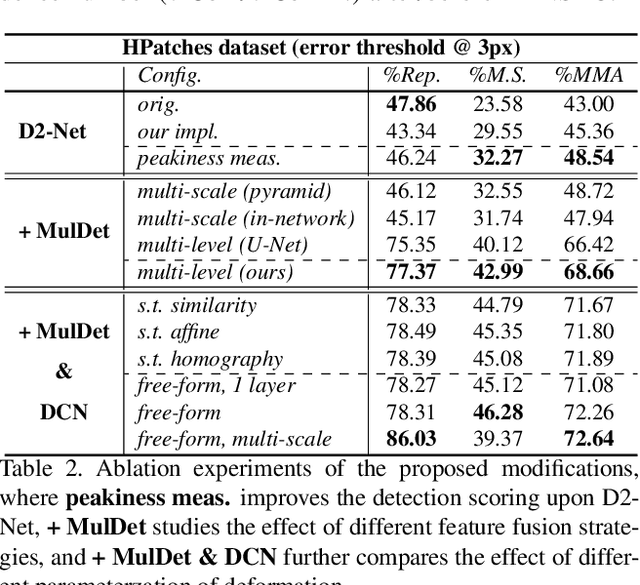
This work focuses on mitigating two limitations in the joint learning of local feature detectors and descriptors. First, the ability to estimate the local shape (scale, orientation, etc.) of feature points is often neglected during dense feature extraction, while the shape-awareness is crucial to acquire stronger geometric invariance. Second, the localization accuracy of detected keypoints is not sufficient to reliably recover camera geometry, which has become the bottleneck in tasks such as 3D reconstruction. In this paper, we present ASLFeat, with three light-weight yet effective modifications to mitigate above issues. First, we resort to deformable convolutional networks to densely estimate and apply local transformation. Second, we take advantage of the inherent feature hierarchy to restore spatial resolution and low-level details for accurate keypoint localization. Finally, we use a peakiness measurement to relate feature responses and derive more indicative detection scores. The effect of each modification is thoroughly studied, and the evaluation is extensively conducted across a variety of practical scenarios. State-of-the-art results are reported that demonstrate the superiority of our methods.
Joint Semantic Segmentation and Boundary Detection using Iterative Pyramid Contexts
Apr 16, 2020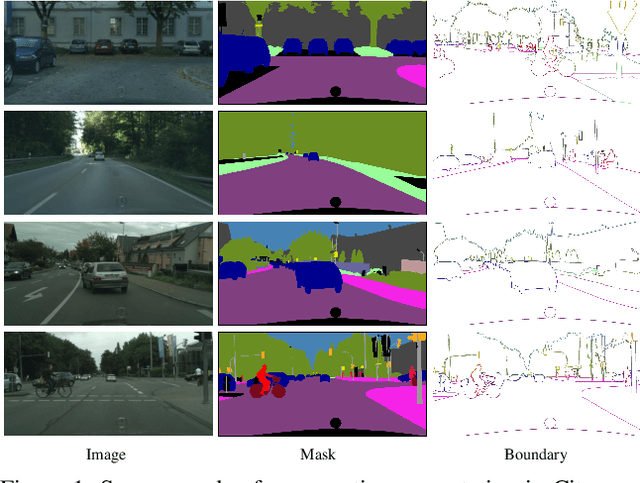
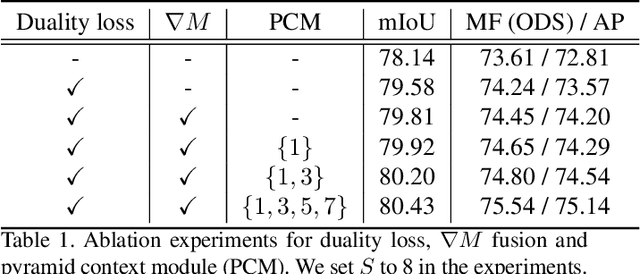
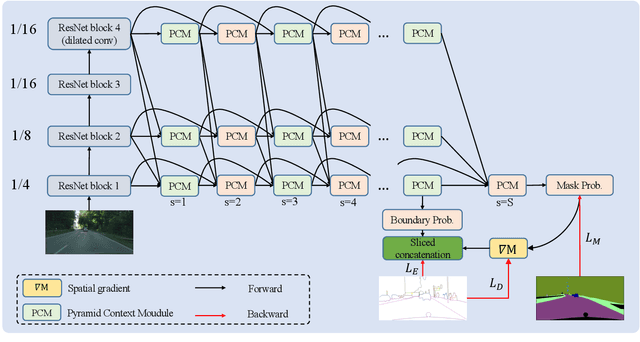
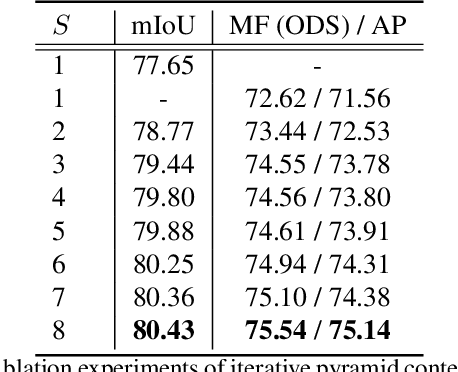
In this paper, we present a joint multi-task learning framework for semantic segmentation and boundary detection. The critical component in the framework is the iterative pyramid context module (PCM), which couples two tasks and stores the shared latent semantics to interact between the two tasks. For semantic boundary detection, we propose the novel spatial gradient fusion to suppress nonsemantic edges. As semantic boundary detection is the dual task of semantic segmentation, we introduce a loss function with boundary consistency constraint to improve the boundary pixel accuracy for semantic segmentation. Our extensive experiments demonstrate superior performance over state-of-the-art works, not only in semantic segmentation but also in semantic boundary detection. In particular, a mean IoU score of 81:8% on Cityscapes test set is achieved without using coarse data or any external data for semantic segmentation. For semantic boundary detection, we improve over previous state-of-the-art works by 9.9% in terms of AP and 6:8% in terms of MF(ODS).
KFNet: Learning Temporal Camera Relocalization using Kalman Filtering
Mar 24, 2020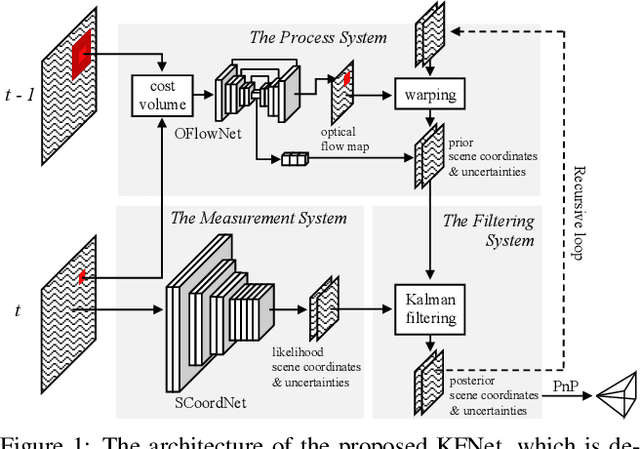
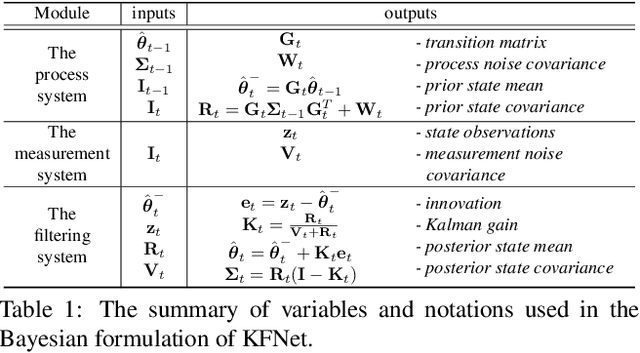
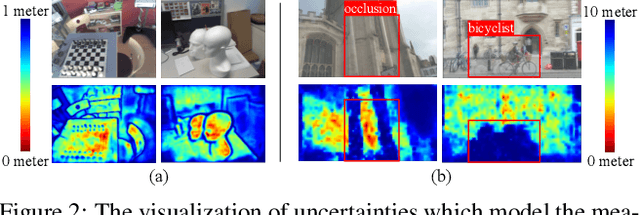
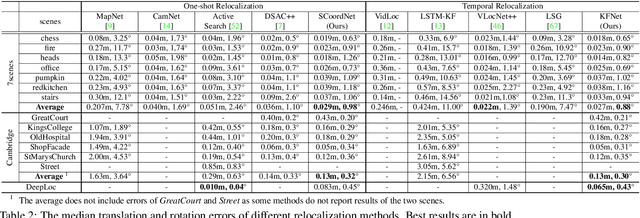
Temporal camera relocalization estimates the pose with respect to each video frame in sequence, as opposed to one-shot relocalization which focuses on a still image. Even though the time dependency has been taken into account, current temporal relocalization methods still generally underperform the state-of-the-art one-shot approaches in terms of accuracy. In this work, we improve the temporal relocalization method by using a network architecture that incorporates Kalman filtering (KFNet) for online camera relocalization. In particular, KFNet extends the scene coordinate regression problem to the time domain in order to recursively establish 2D and 3D correspondences for the pose determination. The network architecture design and the loss formulation are based on Kalman filtering in the context of Bayesian learning. Extensive experiments on multiple relocalization benchmarks demonstrate the high accuracy of KFNet at the top of both one-shot and temporal relocalization approaches. Our codes are released at https://github.com/zlthinker/KFNet.
BlendedMVS: A Large-scale Dataset for Generalized Multi-view Stereo Networks
Nov 22, 2019
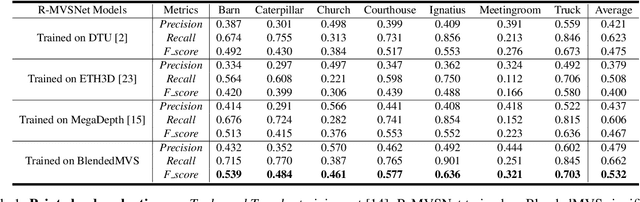

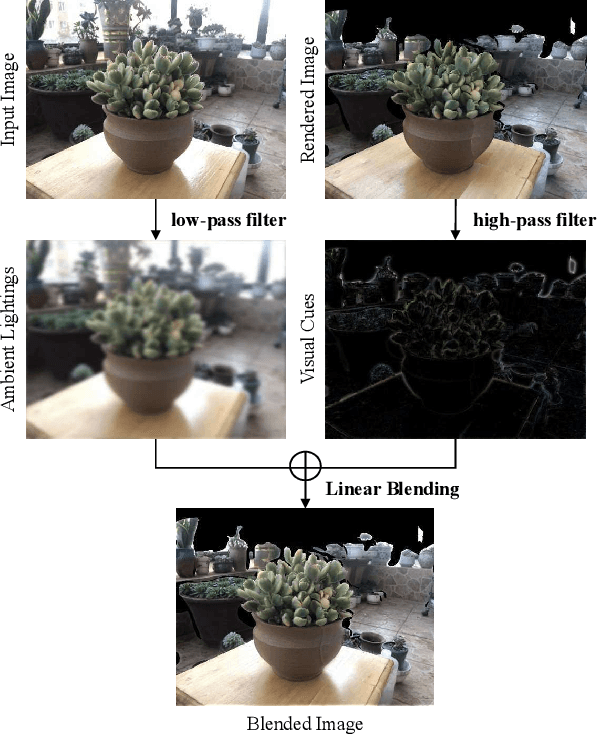
While deep learning has recently achieved great success on multi-view stereo (MVS), limited training data makes the trained model hard to be generalized to unseen scenarios. Compared with other computer vision tasks, it is rather difficult to collect a large-scale MVS dataset as it requires expensive active scanners and labor-intensive process to obtain ground truth 3D structures. In this paper, we introduce BlendedMVS, a novel large-scale dataset, to provide sufficient training ground truth for learning-based MVS. To create the dataset, we apply a 3D reconstruction pipeline to recover high-quality textured meshes from images of well-selected scenes. Then, we render these mesh models to color images and depth maps. The rendered color images are further blended with the input images to generate photo-realistic blended images as the training input. Our dataset contains over 17k high-resolution images covering a variety of scenes, including cities, architectures, sculptures and small objects. Extensive experiments demonstrate that BlendedMVS endows the trained model with significantly better generalization ability compared with other MVS datasets. The entire dataset with pretrained models will be made publicly available at https://github.com/YoYo000/BlendedMVS.
Self-Supervised Learning of Depth and Motion Under Photometric Inconsistency
Sep 19, 2019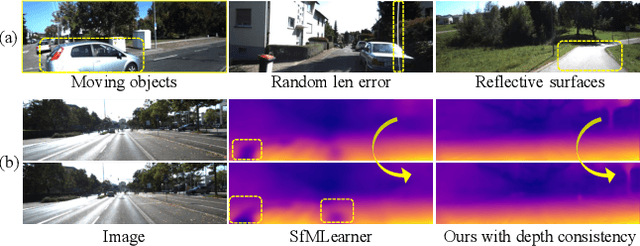
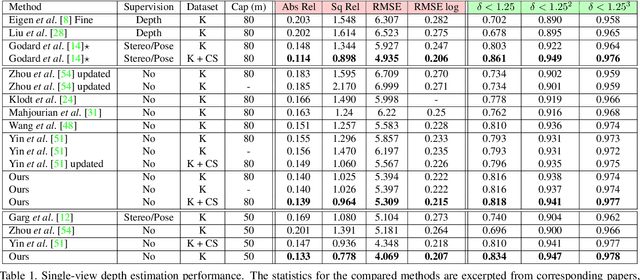
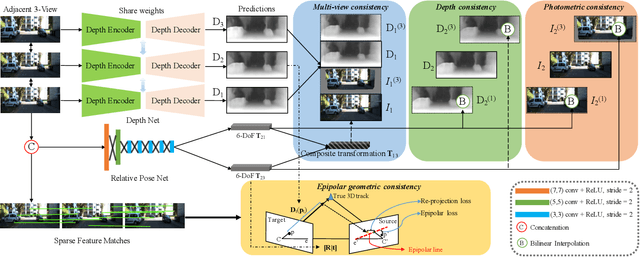
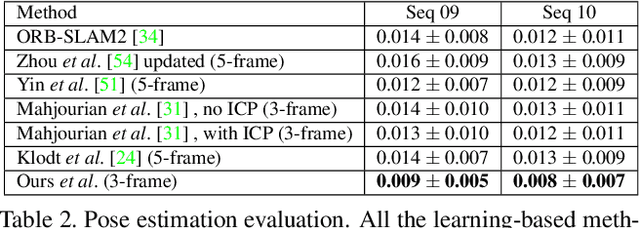
The self-supervised learning of depth and pose from monocular sequences provides an attractive solution by using the photometric consistency of nearby frames as it depends much less on the ground-truth data. In this paper, we address the issue when previous assumptions of the self-supervised approaches are violated due to the dynamic nature of real-world scenes. Different from handling the noise as uncertainty, our key idea is to incorporate more robust geometric quantities and enforce internal consistency in the temporal image sequence. As demonstrated on commonly used benchmark datasets, the proposed method substantially improves the state-of-the-art methods on both depth and relative pose estimation for monocular image sequences, without adding inference overhead.