 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBIAS-ID: A Framework for Analyzing Transformation Biases in AI-Generated Image Detectors
May 29, 2026Given the surge of harmful AI-generated imagery online, reliably distinguishing authentic images from generated ones has become an urgent research topic. While many proposed detection methods perform well under controlled settings, they often collapse when tested on real-world data. A potential root cause are subtle biases in the detectors' training data. As a result, detectors may rely on spurious correlations instead of learning true forensic artifacts. While a recent line of work has identified the problem, there is not yet an established protocol to evaluate how biased a detector actually is. In this work, we therefore take a step back: First, we discuss what it means for a detector to be biased, and how this differs from a lack of robustness. Second, we propose BIAS-ID, a transparent framework for analyzing and quantifying the presence of transformation biases in AI-generated image detectors. We validate our framework by performing an evaluation of six detectors across two datasets, revealing that several state-of-the-art detection methods are strongly affected by biases. Our results highlight the importance of bias-aware evaluation for developing reliable AI-generated image detectors.
Towards A Correct Usage of Cryptography in Semantic Watermarks for Diffusion Models
Mar 14, 2025Semantic watermarking methods enable the direct integration of watermarks into the generation process of latent diffusion models by only modifying the initial latent noise. One line of approaches building on Gaussian Shading relies on cryptographic primitives to steer the sampling process of the latent noise. However, we identify several issues in the usage of cryptographic techniques in Gaussian Shading, particularly in its proof of lossless performance and key management, causing ambiguity in follow-up works, too. In this work, we therefore revisit the cryptographic primitives for semantic watermarking. We introduce a novel, general proof of lossless performance based on IND\$-CPA security for semantic watermarks. We then discuss the configuration of the cryptographic primitives in semantic watermarks with respect to security, efficiency, and generation quality.
Black-Box Forgery Attacks on Semantic Watermarks for Diffusion Models
Dec 04, 2024



Integrating watermarking into the generation process of latent diffusion models (LDMs) simplifies detection and attribution of generated content. Semantic watermarks, such as Tree-Rings and Gaussian Shading, represent a novel class of watermarking techniques that are easy to implement and highly robust against various perturbations. However, our work demonstrates a fundamental security vulnerability of semantic watermarks. We show that attackers can leverage unrelated models, even with different latent spaces and architectures (UNet vs DiT), to perform powerful and realistic forgery attacks. Specifically, we design two watermark forgery attacks. The first imprints a targeted watermark into real images by manipulating the latent representation of an arbitrary image in an unrelated LDM to get closer to the latent representation of a watermarked image. We also show that this technique can be used for watermark removal. The second attack generates new images with the target watermark by inverting a watermarked image and re-generating it with an arbitrary prompt. Both attacks just need a single reference image with the target watermark. Overall, our findings question the applicability of semantic watermarks by revealing that attackers can easily forge or remove these watermarks under realistic conditions.
AI-Generated Faces in the Real World: A Large-Scale Case Study of Twitter Profile Images
Apr 22, 2024



Recent advances in the field of generative artificial intelligence (AI) have blurred the lines between authentic and machine-generated content, making it almost impossible for humans to distinguish between such media. One notable consequence is the use of AI-generated images for fake profiles on social media. While several types of disinformation campaigns and similar incidents have been reported in the past, a systematic analysis has been lacking. In this work, we conduct the first large-scale investigation of the prevalence of AI-generated profile pictures on Twitter. We tackle the challenges of a real-world measurement study by carefully integrating various data sources and designing a multi-stage detection pipeline. Our analysis of nearly 15 million Twitter profile pictures shows that 0.052% were artificially generated, confirming their notable presence on the platform. We comprehensively examine the characteristics of these accounts and their tweet content, and uncover patterns of coordinated inauthentic behavior. The results also reveal several motives, including spamming and political amplification campaigns. Our research reaffirms the need for effective detection and mitigation strategies to cope with the potential negative effects of generative AI in the future.
The Impact of Uniform Inputs on Activation Sparsity and Energy-Latency Attacks in Computer Vision
Mar 27, 2024



Resource efficiency plays an important role for machine learning nowadays. The energy and decision latency are two critical aspects to ensure a sustainable and practical application. Unfortunately, the energy consumption and decision latency are not robust against adversaries. Researchers have recently demonstrated that attackers can compute and submit so-called sponge examples at inference time to increase the energy consumption and decision latency of neural networks. In computer vision, the proposed strategy crafts inputs with less activation sparsity which could otherwise be used to accelerate the computation. In this paper, we analyze the mechanism how these energy-latency attacks reduce activation sparsity. In particular, we find that input uniformity is a key enabler. A uniform image, that is, an image with mostly flat, uniformly colored surfaces, triggers more activations due to a specific interplay of convolution, batch normalization, and ReLU activation. Based on these insights, we propose two new simple, yet effective strategies for crafting sponge examples: sampling images from a probability distribution and identifying dense, yet inconspicuous inputs in natural datasets. We empirically examine our findings in a comprehensive evaluation with multiple image classification models and show that our attack achieves the same sparsity effect as prior sponge-example methods, but at a fraction of computation effort. We also show that our sponge examples transfer between different neural networks. Finally, we discuss applications of our findings for the good by improving efficiency by increasing sparsity.
On the Detection of Image-Scaling Attacks in Machine Learning
Oct 23, 2023



Image scaling is an integral part of machine learning and computer vision systems. Unfortunately, this preprocessing step is vulnerable to so-called image-scaling attacks where an attacker makes unnoticeable changes to an image so that it becomes a new image after scaling. This opens up new ways for attackers to control the prediction or to improve poisoning and backdoor attacks. While effective techniques exist to prevent scaling attacks, their detection has not been rigorously studied yet. Consequently, it is currently not possible to reliably spot these attacks in practice. This paper presents the first in-depth systematization and analysis of detection methods for image-scaling attacks. We identify two general detection paradigms and derive novel methods from them that are simple in design yet significantly outperform previous work. We demonstrate the efficacy of these methods in a comprehensive evaluation with all major learning platforms and scaling algorithms. First, we show that image-scaling attacks modifying the entire scaled image can be reliably detected even under an adaptive adversary. Second, we find that our methods provide strong detection performance even if only minor parts of the image are manipulated. As a result, we can introduce a novel protection layer against image-scaling attacks.
No more Reviewer #2: Subverting Automatic Paper-Reviewer Assignment using Adversarial Learning
Mar 25, 2023



The number of papers submitted to academic conferences is steadily rising in many scientific disciplines. To handle this growth, systems for automatic paper-reviewer assignments are increasingly used during the reviewing process. These systems use statistical topic models to characterize the content of submissions and automate the assignment to reviewers. In this paper, we show that this automation can be manipulated using adversarial learning. We propose an attack that adapts a given paper so that it misleads the assignment and selects its own reviewers. Our attack is based on a novel optimization strategy that alternates between the feature space and problem space to realize unobtrusive changes to the paper. To evaluate the feasibility of our attack, we simulate the paper-reviewer assignment of an actual security conference (IEEE S&P) with 165 reviewers on the program committee. Our results show that we can successfully select and remove reviewers without access to the assignment system. Moreover, we demonstrate that the manipulated papers remain plausible and are often indistinguishable from benign submissions.
I still know it's you! On Challenges in Anonymizing Source Code
Aug 26, 2022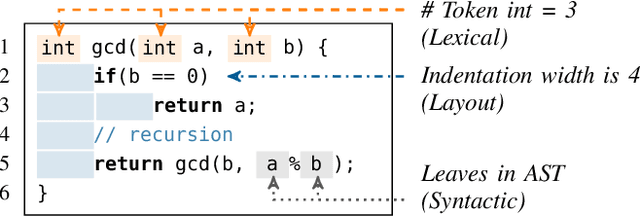
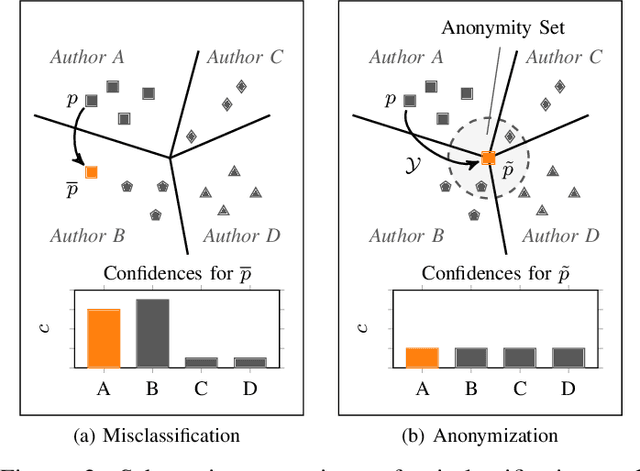

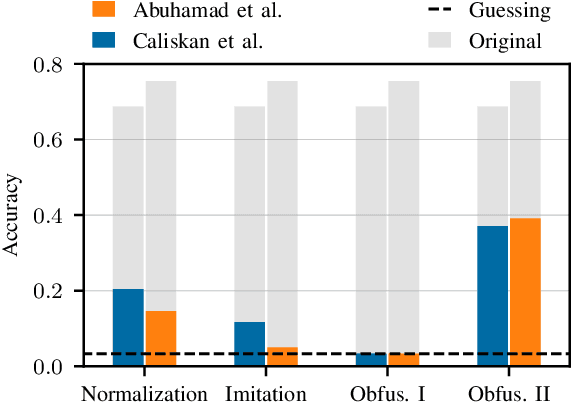
The source code of a program not only defines its semantics but also contains subtle clues that can identify its author. Several studies have shown that these clues can be automatically extracted using machine learning and allow for determining a program's author among hundreds of programmers. This attribution poses a significant threat to developers of anti-censorship and privacy-enhancing technologies, as they become identifiable and may be prosecuted. An ideal protection from this threat would be the anonymization of source code. However, neither theoretical nor practical principles of such an anonymization have been explored so far. In this paper, we tackle this problem and develop a framework for reasoning about code anonymization. We prove that the task of generating a $k$-anonymous program -- a program that cannot be attributed to one of $k$ authors -- is not computable and thus a dead end for research. As a remedy, we introduce a relaxed concept called $k$-uncertainty, which enables us to measure the protection of developers. Based on this concept, we empirically study candidate techniques for anonymization, such as code normalization, coding style imitation, and code obfuscation. We find that none of the techniques provides sufficient protection when the attacker is aware of the anonymization. While we introduce an approach for removing remaining clues from the code, the main result of our work is negative: Anonymization of source code is a hard and open problem.
Misleading Deep-Fake Detection with GAN Fingerprints
May 25, 2022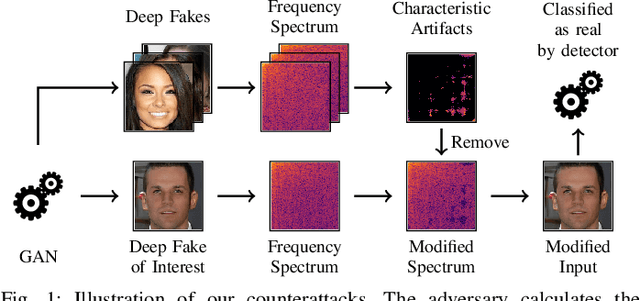
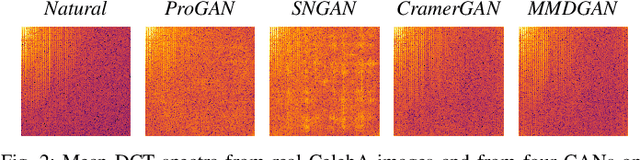
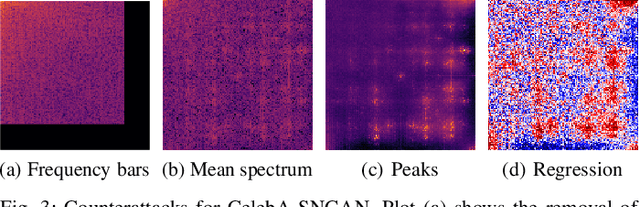

Generative adversarial networks (GANs) have made remarkable progress in synthesizing realistic-looking images that effectively outsmart even humans. Although several detection methods can recognize these deep fakes by checking for image artifacts from the generation process, multiple counterattacks have demonstrated their limitations. These attacks, however, still require certain conditions to hold, such as interacting with the detection method or adjusting the GAN directly. In this paper, we introduce a novel class of simple counterattacks that overcomes these limitations. In particular, we show that an adversary can remove indicative artifacts, the GAN fingerprint, directly from the frequency spectrum of a generated image. We explore different realizations of this removal, ranging from filtering high frequencies to more nuanced frequency-peak cleansing. We evaluate the performance of our attack with different detection methods, GAN architectures, and datasets. Our results show that an adversary can often remove GAN fingerprints and thus evade the detection of generated images.
Against All Odds: Winning the Defense Challenge in an Evasion Competition with Diversification
Oct 19, 2020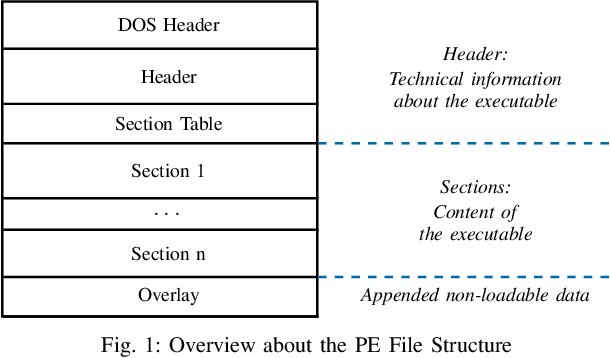
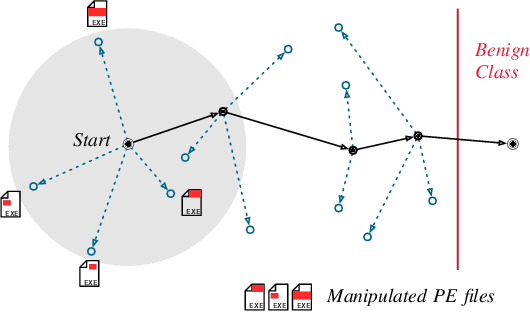
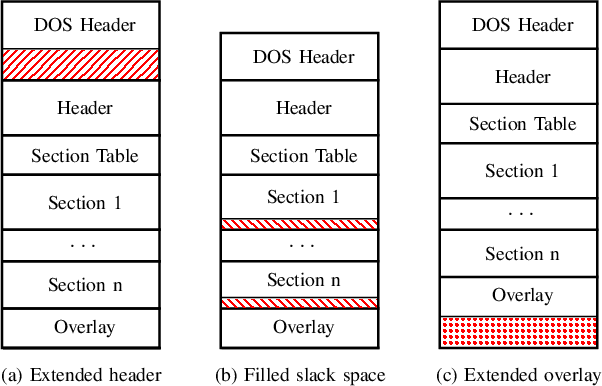
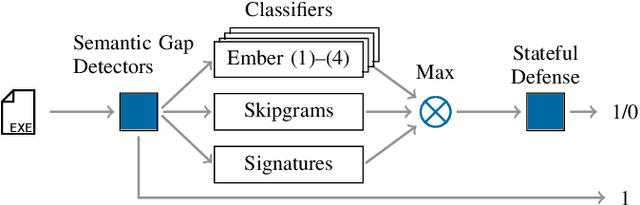
Machine learning-based systems for malware detection operate in a hostile environment. Consequently, adversaries will also target the learning system and use evasion attacks to bypass the detection of malware. In this paper, we outline our learning-based system PEberus that got the first place in the defender challenge of the Microsoft Evasion Competition, resisting a variety of attacks from independent attackers. Our system combines multiple, diverse defenses: we address the semantic gap, use various classification models, and apply a stateful defense. This competition gives us the unique opportunity to examine evasion attacks under a realistic scenario. It also highlights that existing machine learning methods can be hardened against attacks by thoroughly analyzing the attack surface and implementing concepts from adversarial learning. Our defense can serve as an additional baseline in the future to strengthen the research on secure learning.