 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Grid Net: hand mesh vertex regression from single depth maps
Jul 24, 2019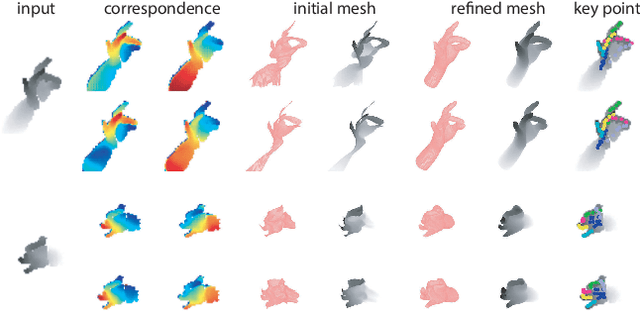
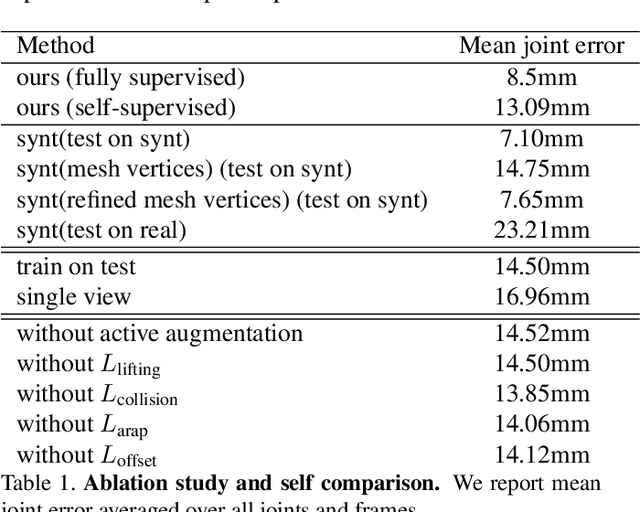
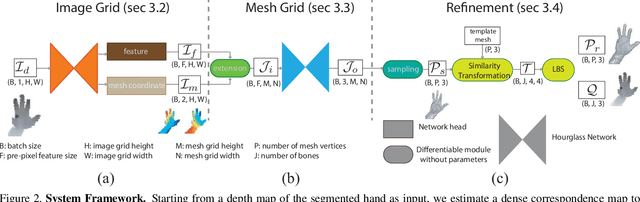

We present a method for recovering the dense 3D surface of the hand by regressing the vertex coordinates of a mesh model from a single depth map. To this end, we use a two-stage 2D fully convolutional network architecture. In the first stage, the network estimates a dense correspondence field for every pixel on the depth map or image grid to the mesh grid. In the second stage, we design a differentiable operator to map features learned from the previous stage and regress a 3D coordinate map on the mesh grid. Finally, we sample from the mesh grid to recover the mesh vertices, and fit it an articulated template mesh in closed form. During inference, the network can predict all the mesh vertices, transformation matrices for every joint and the joint coordinates in a single forward pass. When given supervision on the sparse key-point coordinates, our method achieves state-of-the-art accuracy on NYU dataset for key point localization while recovering mesh vertices and a dense correspondence map. Our framework can also be learned through self-supervision by minimizing a set of data fitting and kinematic prior terms. With multi-camera rig during training to resolve self-occlusion, it can perform competitively with strongly supervised methods Without any human annotation.
Image-based Navigation using Visual Features and Map
Dec 10, 2018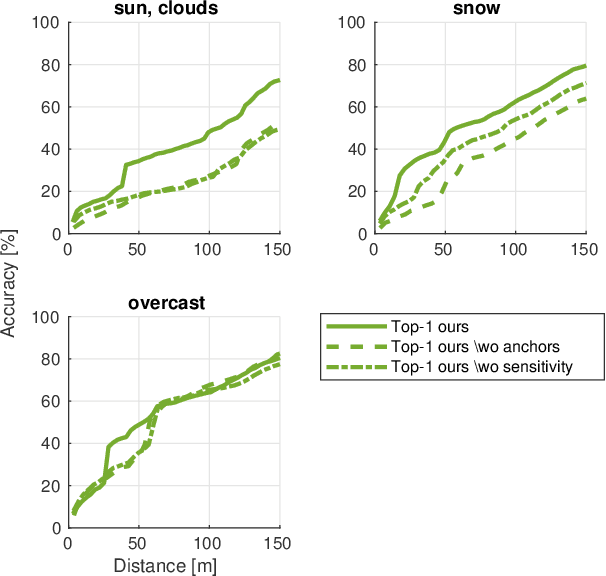
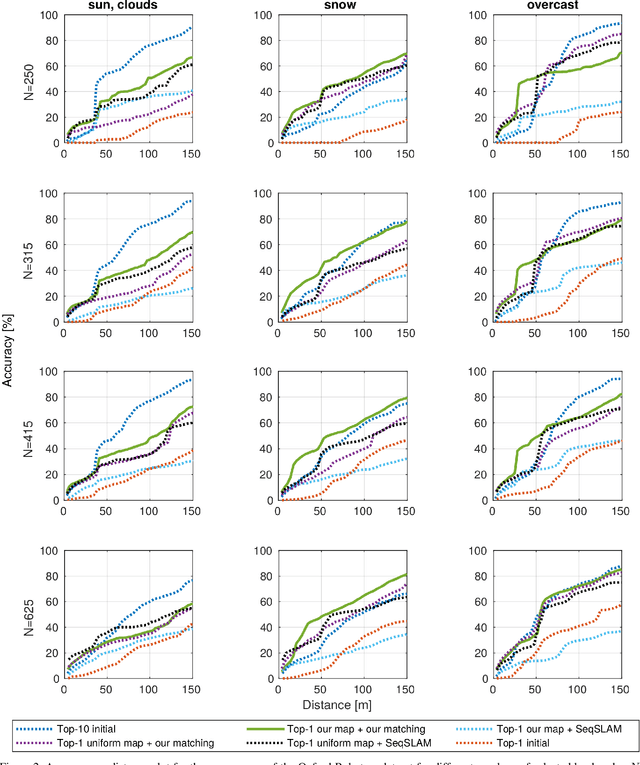
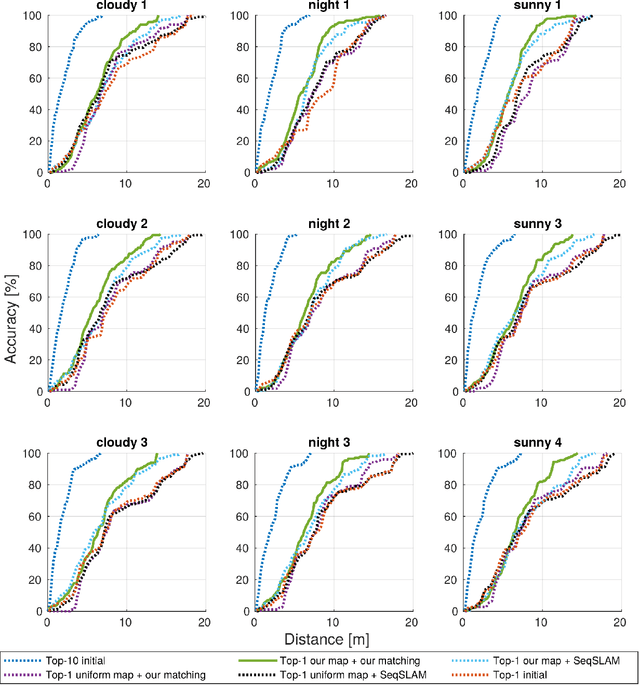
Building on progress in feature representations for image retrieval, image-based localization has seen a surge of research interest. Image-based localization has the advantage of being inexpensive and efficient, often avoiding the use of 3D metric maps altogether. This said, the need to maintain a large number of reference images as an effective support of localization in a scene, nonetheless calls for them to be organized in a map structure of some kind. The problem of localization often arises as part of a navigation process. We are, therefore, interested in summarizing the reference images as a set of landmarks, which meet the requirements for image-based navigation. A contribution of the paper is to formulate such a set of requirements for the two sub-tasks involved: map construction and self localization. These requirements are then exploited for compact map representation and accurate self-localization, using the framework of a network flow problem. During this process, we formulate the map construction and self-localization problems as convex quadratic and second-order cone programs, respectively. We evaluate our methods on publicly available indoor and outdoor datasets, where they outperform existing methods significantly.
Model-free Consensus Maximization for Non-Rigid Shapes
Aug 13, 2018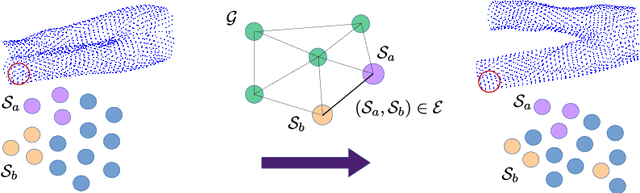
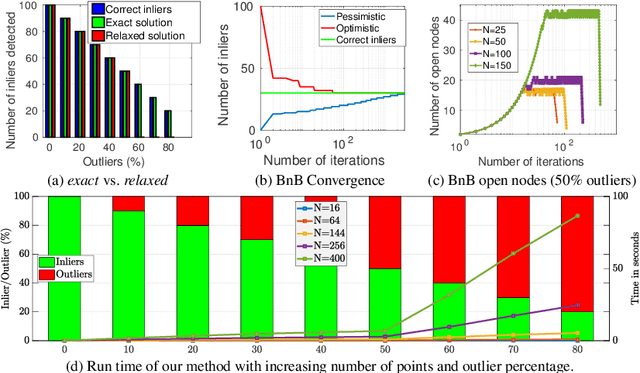
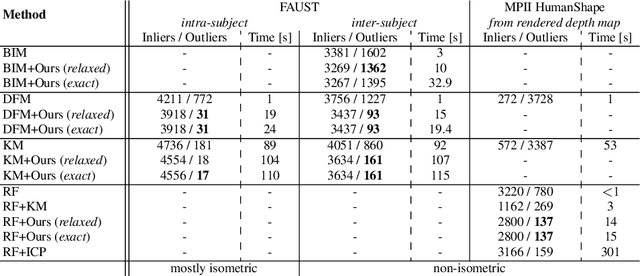

Many computer vision methods use consensus maximization to relate measurements containing outliers with the correct transformation model. In the context of rigid shapes, this is typically done using Random Sampling and Consensus (RANSAC) by estimating an analytical model that agrees with the largest number of measurements (inliers). However, small parameter models may not be always available. In this paper, we formulate the model-free consensus maximization as an Integer Program in a graph using `rules' on measurements. We then provide a method to solve it optimally using the Branch and Bound (BnB) paradigm. We focus its application on non-rigid shapes, where we apply the method to remove outlier 3D correspondences and achieve performance superior to the state of the art. Our method works with outlier ratio as high as 80\%. We further derive a similar formulation for 3D template to image matching, achieving similar or better performance compared to the state of the art.
Incremental Non-Rigid Structure-from-Motion with Unknown Focal Length
Aug 13, 2018
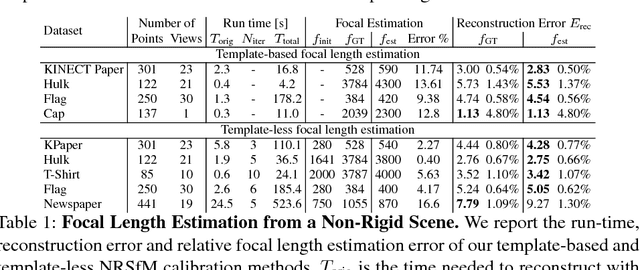
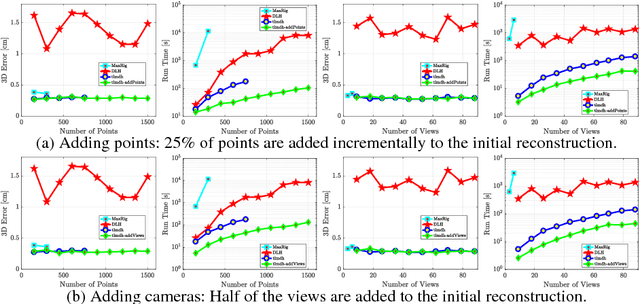
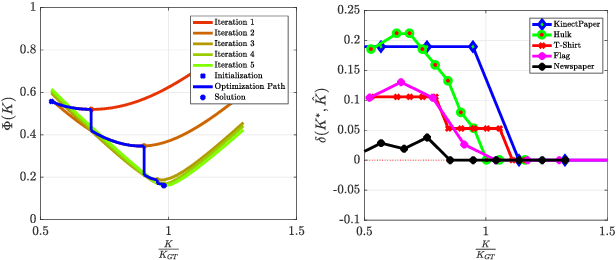
The perspective camera and the isometric surface prior have recently gathered increased attention for Non-Rigid Structure-from-Motion (NRSfM). Despite the recent progress, several challenges remain, particularly the computational complexity and the unknown camera focal length. In this paper we present a method for incremental Non-Rigid Structure-from-Motion (NRSfM) with the perspective camera model and the isometric surface prior with unknown focal length. In the template-based case, we provide a method to estimate four parameters of the camera intrinsics. For the template-less scenario of NRSfM, we propose a method to upgrade reconstructions obtained for one focal length to another based on local rigidity and the so-called Maximum Depth Heuristics (MDH). On its basis we propose a method to simultaneously recover the focal length and the non-rigid shapes. We further solve the problem of incorporating a large number of points and adding more views in MDH-based NRSfM and efficiently solve them with Second-Order Cone Programming (SOCP). This does not require any shape initialization and produces results orders of times faster than many methods. We provide evaluations on standard sequences with ground-truth and qualitative reconstructions on challenging YouTube videos. These evaluations show that our method performs better in both speed and accuracy than the state of the art.
Dense 3D Regression for Hand Pose Estimation
Nov 24, 2017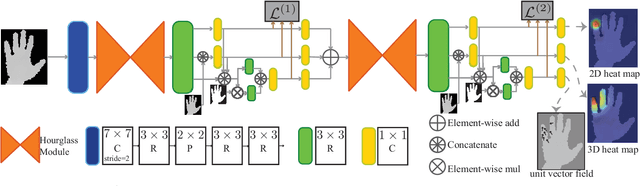
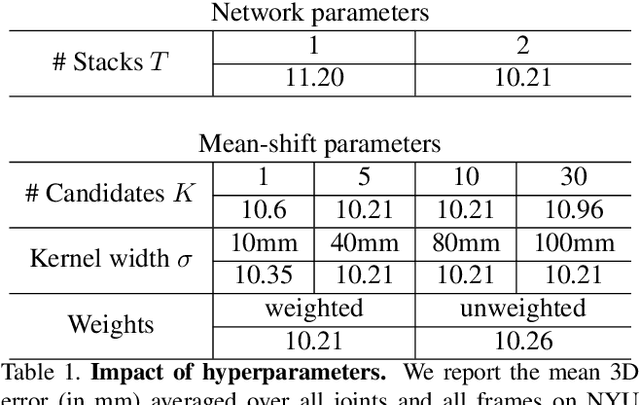
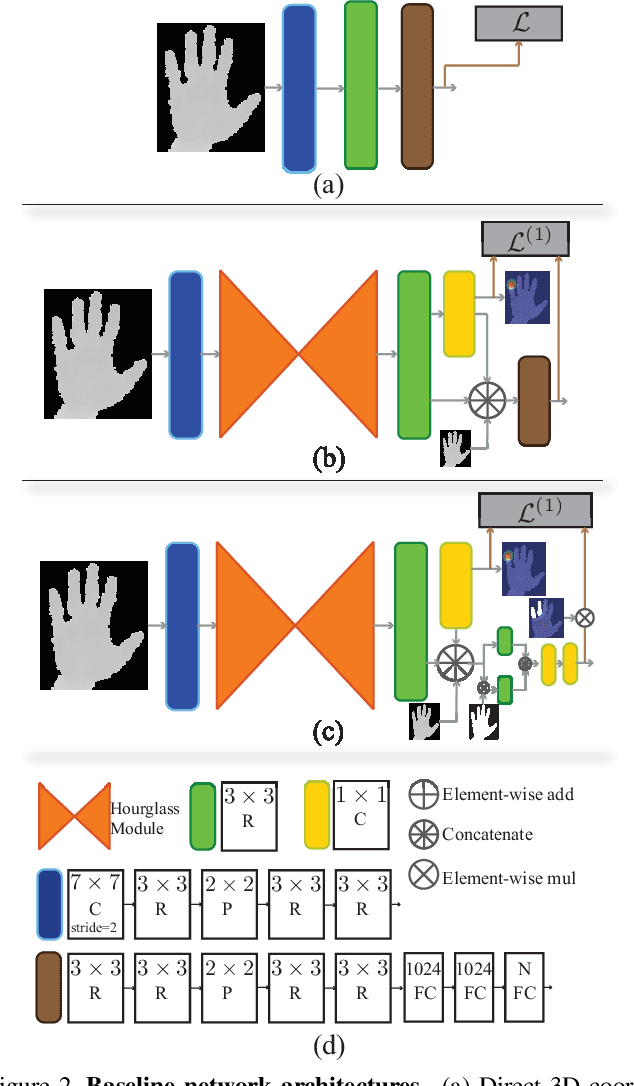

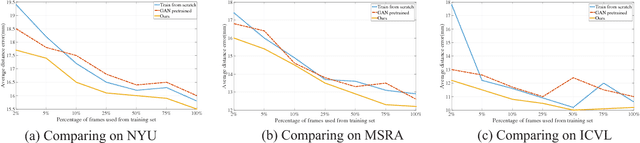
We present a simple and effective method for 3D hand pose estimation from a single depth frame. As opposed to previous state-of-the-art methods based on holistic 3D regression, our method works on dense pixel-wise estimation. This is achieved by careful design choices in pose parameterization, which leverages both 2D and 3D properties of depth map. Specifically, we decompose the pose parameters into a set of per-pixel estimations, i.e., 2D heat maps, 3D heat maps and unit 3D directional vector fields. The 2D/3D joint heat maps and 3D joint offsets are estimated via multi-task network cascades, which is trained end-to-end. The pixel-wise estimations can be directly translated into a vote casting scheme. A variant of mean shift is then used to aggregate local votes while enforcing consensus between the the estimated 3D pose and the pixel-wise 2D and 3D estimations by design. Our method is efficient and highly accurate. On MSRA and NYU hand dataset, our method outperforms all previous state-of-the-art approaches by a large margin. On the ICVL hand dataset, our method achieves similar accuracy compared to the currently proposed nearly saturated result and outperforms various other proposed methods. Code is available $\href{"https://github.com/melonwan/denseReg"}{\text{online}}$.
Automatic Tool Landmark Detection for Stereo Vision in Robot-Assisted Retinal Surgery
Nov 20, 2017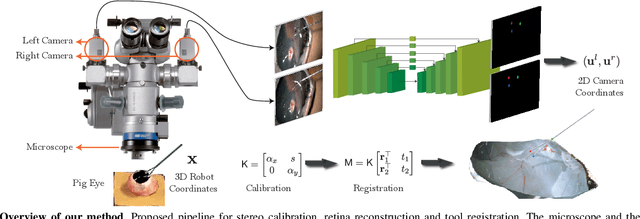
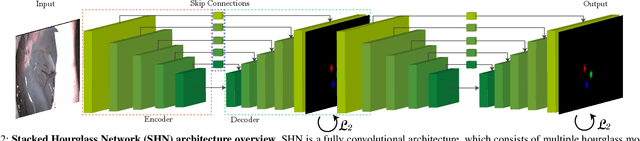
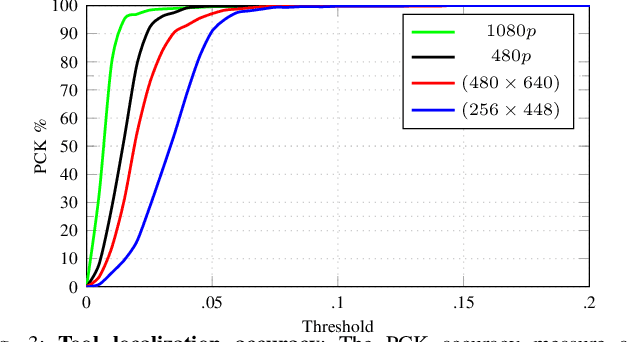
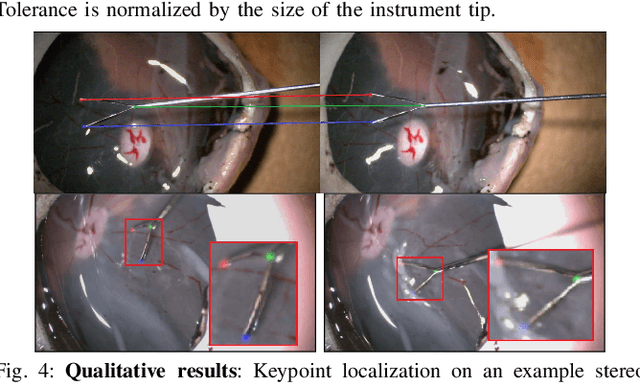
Computer vision and robotics are being increasingly applied in medical interventions. Especially in interventions where extreme precision is required they could make a difference. One such application is robot-assisted retinal microsurgery. In recent works, such interventions are conducted under a stereo-microscope, and with a robot-controlled surgical tool. The complementarity of computer vision and robotics has however not yet been fully exploited. In order to improve the robot control we are interested in 3D reconstruction of the anatomy and in automatic tool localization using a stereo microscope. In this paper, we solve this problem for the first time using a single pipeline, starting from uncalibrated cameras to reach metric 3D reconstruction and registration, in retinal microsurgery. The key ingredients of our method are: (a) surgical tool landmark detection, and (b) 3D reconstruction with the stereo microscope, using the detected landmarks. To address the former, we propose a novel deep learning method that detects and recognizes keypoints in high definition images at higher than real-time speed. We use the detected 2D keypoints along with their corresponding 3D coordinates obtained from the robot sensors to calibrate the stereo microscope using an affine projection model. We design an online 3D reconstruction pipeline that makes use of smoothness constraints and performs robot-to-camera registration. The entire pipeline is extensively validated on open-sky porcine eye sequences. Quantitative and qualitative results are presented for all steps.
Crossing Nets: Combining GANs and VAEs with a Shared Latent Space for Hand Pose Estimation
Jul 18, 2017
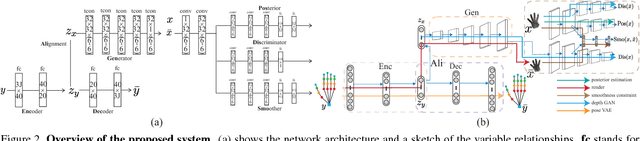
State-of-the-art methods for 3D hand pose estimation from depth images require large amounts of annotated training data. We propose to model the statistical relationships of 3D hand poses and corresponding depth images using two deep generative models with a shared latent space. By design, our architecture allows for learning from unlabeled image data in a semi-supervised manner. Assuming a one-to-one mapping between a pose and a depth map, any given point in the shared latent space can be projected into both a hand pose and a corresponding depth map. Regressing the hand pose can then be done by learning a discriminator to estimate the posterior of the latent pose given some depth maps. To improve generalization and to better exploit unlabeled depth maps, we jointly train a generator and a discriminator. At each iteration, the generator is updated with the back-propagated gradient from the discriminator to synthesize realistic depth maps of the articulated hand, while the discriminator benefits from an augmented training set of synthesized and unlabeled samples. The proposed discriminator network architecture is highly efficient and runs at 90 FPS on the CPU with accuracies comparable or better than state-of-art on 3 publicly available benchmarks.
Deep Learning on Lie Groups for Skeleton-based Action Recognition
Apr 11, 2017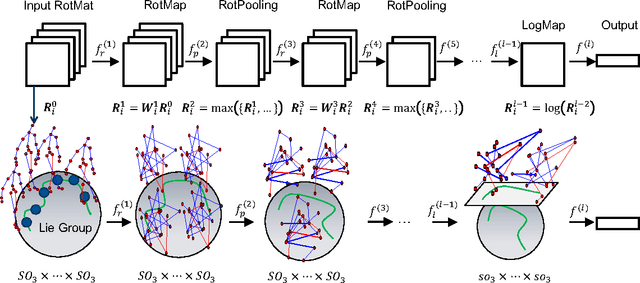
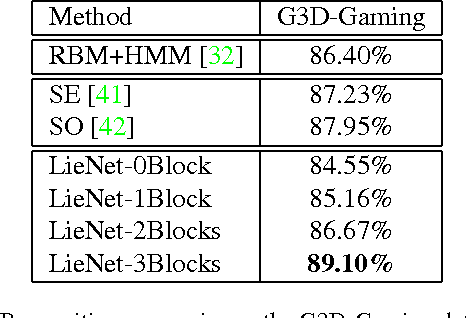
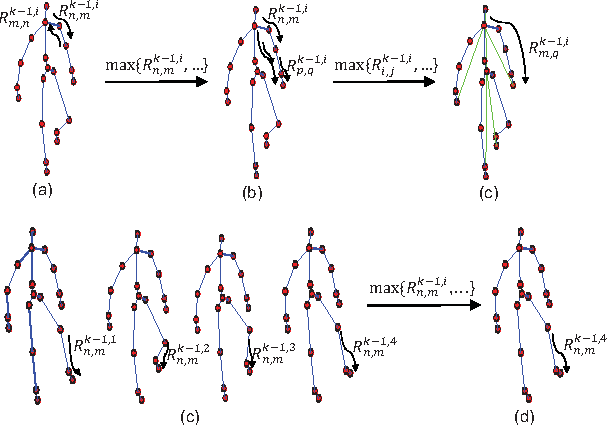
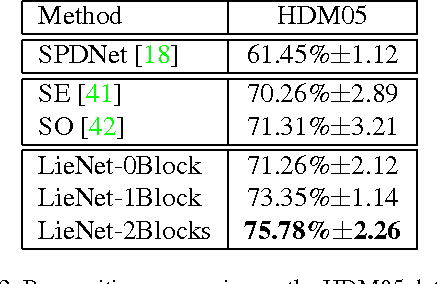
In recent years, skeleton-based action recognition has become a popular 3D classification problem. State-of-the-art methods typically first represent each motion sequence as a high-dimensional trajectory on a Lie group with an additional dynamic time warping, and then shallowly learn favorable Lie group features. In this paper we incorporate the Lie group structure into a deep network architecture to learn more appropriate Lie group features for 3D action recognition. Within the network structure, we design rotation mapping layers to transform the input Lie group features into desirable ones, which are aligned better in the temporal domain. To reduce the high feature dimensionality, the architecture is equipped with rotation pooling layers for the elements on the Lie group. Furthermore, we propose a logarithm mapping layer to map the resulting manifold data into a tangent space that facilitates the application of regular output layers for the final classification. Evaluations of the proposed network for standard 3D human action recognition datasets clearly demonstrate its superiority over existing shallow Lie group feature learning methods as well as most conventional deep learning methods.