 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSD-GAN: Measuring the Realness in the Spatial and Spectral Domains
Dec 15, 2020

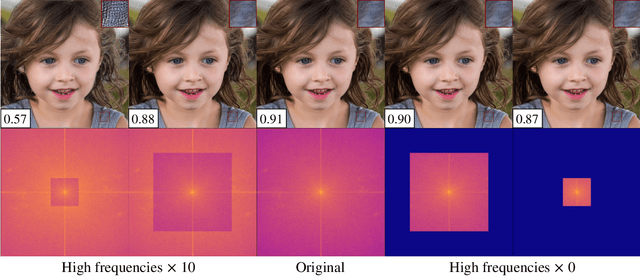

This paper observes that there is an issue of high frequencies missing in the discriminator of standard GAN, and we reveal it stems from downsampling layers employed in the network architecture. This issue makes the generator lack the incentive from the discriminator to learn high-frequency content of data, resulting in a significant spectrum discrepancy between generated images and real images. Since the Fourier transform is a bijective mapping, we argue that reducing this spectrum discrepancy would boost the performance of GANs. To this end, we introduce SSD-GAN, an enhancement of GANs to alleviate the spectral information loss in the discriminator. Specifically, we propose to embed a frequency-aware classifier into the discriminator to measure the realness of the input in both the spatial and spectral domains. With the enhanced discriminator, the generator of SSD-GAN is encouraged to learn high-frequency content of real data and generate exact details. The proposed method is general and can be easily integrated into most existing GANs framework without excessive cost. The effectiveness of SSD-GAN is validated on various network architectures, objective functions, and datasets. Code will be available at https://github.com/cyq373/SSD-GAN.
RoIMix: Proposal-Fusion among Multiple Images for Underwater Object Detection
Nov 08, 2019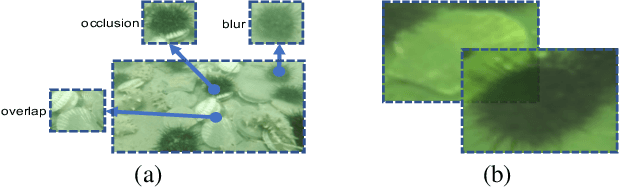

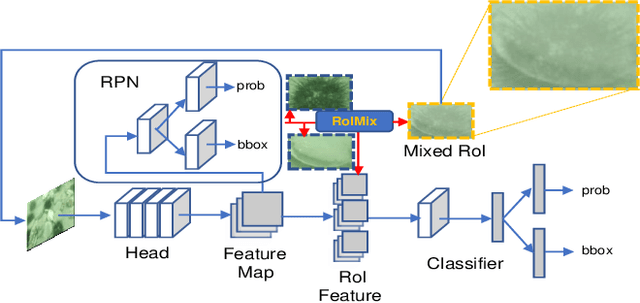

Generic object detection algorithms have proven their excellent performance in recent years. However, object detection on underwater datasets is still less explored. In contrast to generic datasets, underwater images usually have color shift and low contrast; sediment would cause blurring in underwater images. In addition, underwater creatures often appear closely to each other on images due to their living habits. To address these issues, our work investigates augmentation policies to simulate overlapping, occluded and blurred objects, and we construct a model capable of achieving better generalization. We propose an augmentation method called RoIMix, which characterizes interactions among images. Proposals extracted from different images are mixed together. Previous data augmentation methods operate on a single image while we apply RoIMix to multiple images to create enhanced samples as training data. Experiments show that our proposed method improves the performance of region-based object detectors on both Pascal VOC and URPC datasets.
Multi-mapping Image-to-Image Translation via Learning Disentanglement
Sep 17, 2019
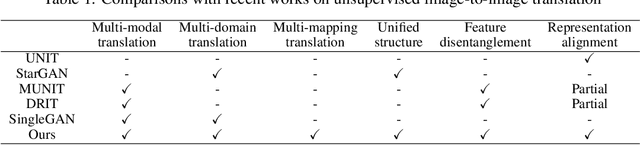

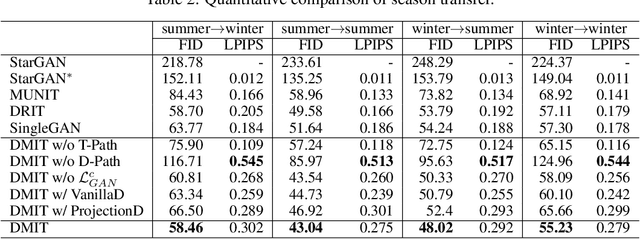
Recent advances of image-to-image translation focus on learning the one-to-many mapping from two aspects: multi-modal translation and multi-domain translation. However, the existing methods only consider one of the two perspectives, which makes them unable to solve each other's problem. To address this issue, we propose a novel unified model, which bridges these two objectives. First, we disentangle the input images into the latent representations by an encoder-decoder architecture with a conditional adversarial training in the feature space. Then, we encourage the generator to learn multi-mappings by a random cross-domain translation. As a result, we can manipulate different parts of the latent representations to perform multi-modal and multi-domain translations simultaneously. Experiments demonstrate that our method outperforms state-of-the-art methods.
ARMIN: Towards a More Efficient and Light-weight Recurrent Memory Network
Jun 28, 2019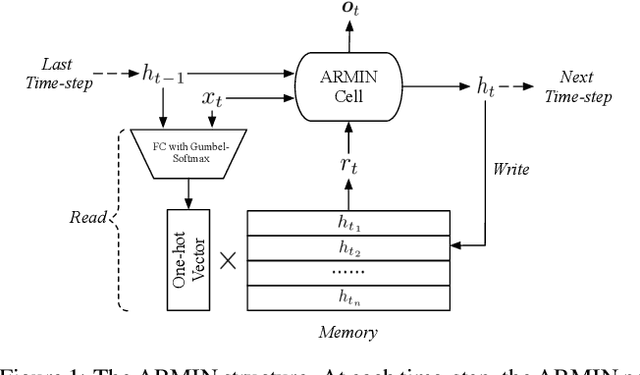
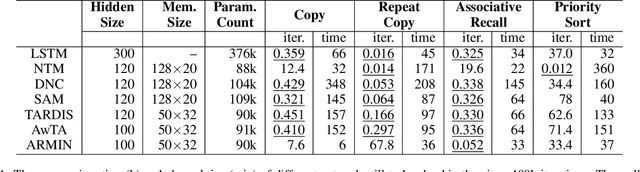
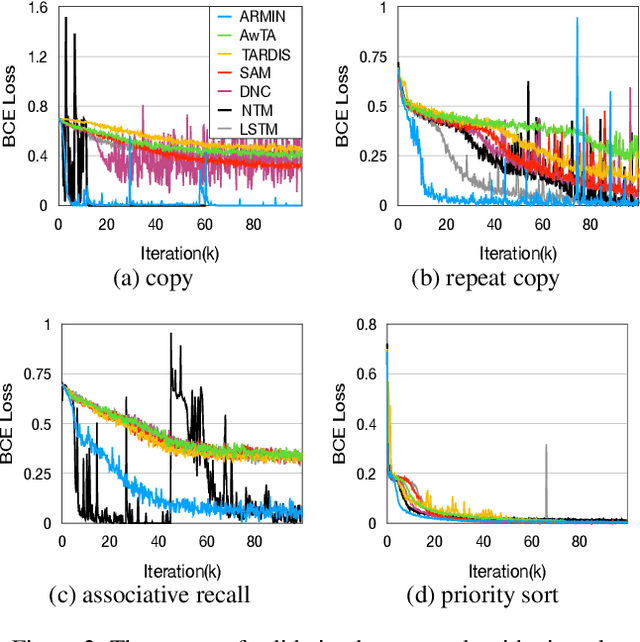
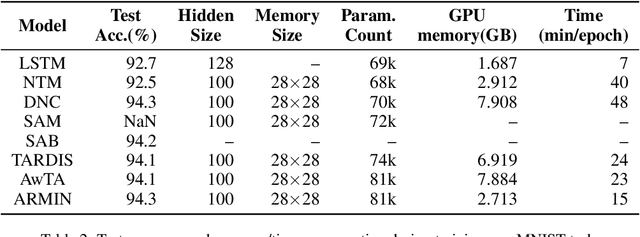
In recent years, memory-augmented neural networks(MANNs) have shown promising power to enhance the memory ability of neural networks for sequential processing tasks. However, previous MANNs suffer from complex memory addressing mechanism, making them relatively hard to train and causing computational overheads. Moreover, many of them reuse the classical RNN structure such as LSTM for memory processing, causing inefficient exploitations of memory information. In this paper, we introduce a novel MANN, the Auto-addressing and Recurrent Memory Integrating Network (ARMIN) to address these issues. The ARMIN only utilizes hidden state ht for automatic memory addressing, and uses a novel RNN cell for refined integration of memory information. Empirical results on a variety of experiments demonstrate that the ARMIN is more light-weight and efficient compared to existing memory networks. Moreover, we demonstrate that the ARMIN can achieve much lower computational overhead than vanilla LSTM while keeping similar performances. Codes are available on github.com/zoharli/armin.
BLP - Boundary Likelihood Pinpointing Networks for Accurate Temporal Action Localization
Nov 12, 2018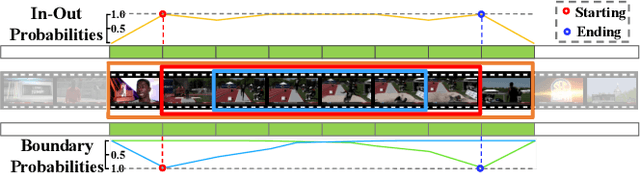

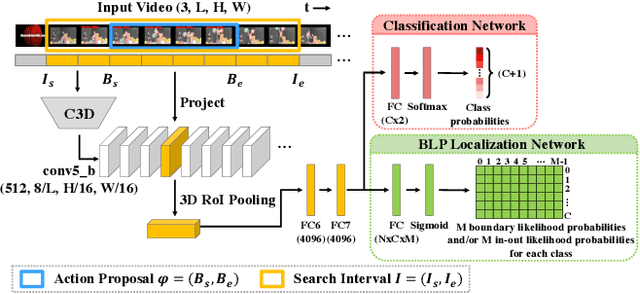

Despite tremendous progress achieved in temporal action detection, state-of-the-art methods still suffer from the sharp performance deterioration when localizing the starting and ending temporal action boundaries. Although most methods apply boundary regression paradigm to tackle this problem, we argue that the direct regression lacks detailed enough information to yield accurate temporal boundaries. In this paper, we propose a novel Boundary Likelihood Pinpointing (BLP) network to alleviate this deficiency of boundary regression and improve the localization accuracy. Given a loosely localized search interval that contains an action instance, BLP casts the problem of localizing temporal boundaries as that of assigning probabilities on each equally divided unit of this interval. These generated probabilities provide useful information regarding the boundary location of the action inside this search interval. Based on these probabilities, we introduce a boundary pinpointing paradigm to pinpoint the accurate boundaries under a simple probabilistic framework. Compared with other C3D feature based detectors, extensive experiments demonstrate that BLP significantly improve the localization performance of recent state-of-the-art detectors, and achieve competitive detection mAP on both THUMOS' 14 and ActivityNet datasets, particularly when the evaluation tIoU is high.
Multi-Mapping Image-to-Image Translation with Central Biasing Normalization
Oct 11, 2018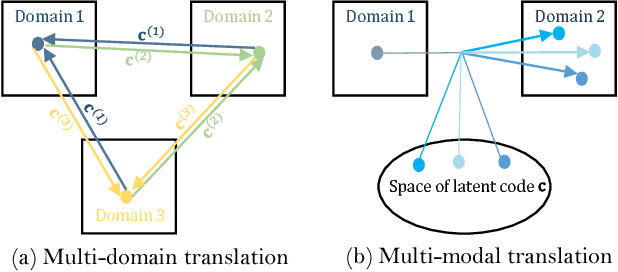
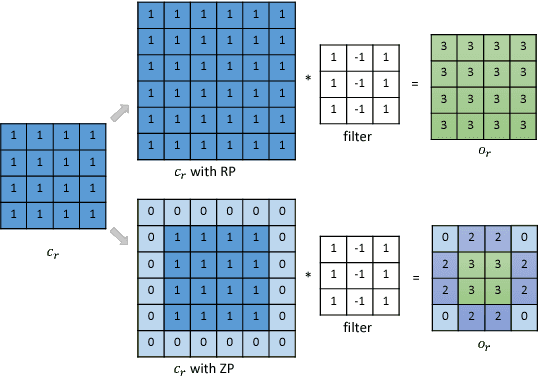
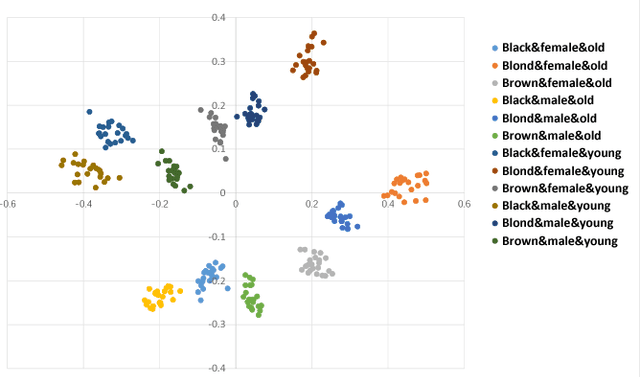

Image-to-image translation is a class of image processing and vision problems that translates an image to a different style or domain. To improve the capacity and performance of one-to-one translation models, multi-mapping image translation have been attempting to extend them for multiple mappings by injecting latent code. Through the analysis of the existing latent code injection models, we find that latent code can determine the target mapping of a generator by controlling the output statistical properties, especially the mean value. However, we find that in some cases the normalization will reduce the consistency of same mapping or the diversity of different mappings. After mathematical analysis, we find the reason behind that is that the distributions of same mapping become inconsistent after batch normalization, and that the effects of latent code are eliminated after instance normalization. To solve these problems, we propose consistency within diversity design criteria for multi-mapping networks. Based on the design criteria, we propose central biasing normalization (CBN) to replace existing latent code injection. CBN can be easily integrated into existing multi-mapping models, significantly reducing model parameters. Experiments show that the results of our method is more stable and diverse than that of existing models. https://github.com/Xiaoming-Yu/cbn .
SingleGAN: Image-to-Image Translation by a Single-Generator Network using Multiple Generative Adversarial Learning
Oct 11, 2018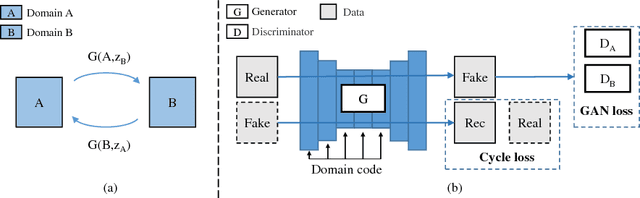
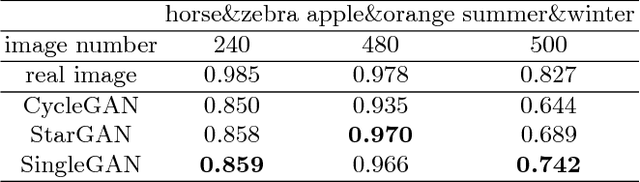
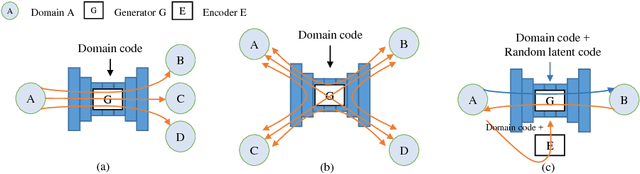
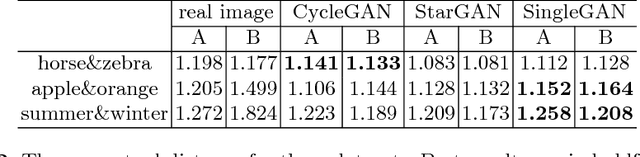
Image translation is a burgeoning field in computer vision where the goal is to learn the mapping between an input image and an output image. However, most recent methods require multiple generators for modeling different domain mappings, which are inefficient and ineffective on some multi-domain image translation tasks. In this paper, we propose a novel method, SingleGAN, to perform multi-domain image-to-image translations with a single generator. We introduce the domain code to explicitly control the different generative tasks and integrate multiple optimization goals to ensure the translation. Experimental results on several unpaired datasets show superior performance of our model in translation between two domains. Besides, we explore variants of SingleGAN for different tasks, including one-to-many domain translation, many-to-many domain translation and one-to-one domain translation with multimodality. The extended experiments show the universality and extensibility of our model.