 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextANIMAR: Text-based 3D Animal Fine-Grained Retrieval
Apr 12, 2023



3D object retrieval is an important yet challenging task, which has drawn more and more attention in recent years. While existing approaches have made strides in addressing this issue, they are often limited to restricted settings such as image and sketch queries, which are often unfriendly interactions for common users. In order to overcome these limitations, this paper presents a novel SHREC challenge track focusing on text-based fine-grained retrieval of 3D animal models. Unlike previous SHREC challenge tracks, the proposed task is considerably more challenging, requiring participants to develop innovative approaches to tackle the problem of text-based retrieval. Despite the increased difficulty, we believe that this task has the potential to drive useful applications in practice and facilitate more intuitive interactions with 3D objects. Five groups participated in our competition, submitting a total of 114 runs. While the results obtained in our competition are satisfactory, we note that the challenges presented by this task are far from being fully solved. As such, we provide insights into potential areas for future research and improvements. We believe that we can help push the boundaries of 3D object retrieval and facilitate more user-friendly interactions via vision-language technologies.
SketchANIMAR: Sketch-based 3D Animal Fine-Grained Retrieval
Apr 12, 2023The retrieval of 3D objects has gained significant importance in recent years due to its broad range of applications in computer vision, computer graphics, virtual reality, and augmented reality. However, the retrieval of 3D objects presents significant challenges due to the intricate nature of 3D models, which can vary in shape, size, and texture, and have numerous polygons and vertices. To this end, we introduce a novel SHREC challenge track that focuses on retrieving relevant 3D animal models from a dataset using sketch queries and expedites accessing 3D models through available sketches. Furthermore, a new dataset named ANIMAR was constructed in this study, comprising a collection of 711 unique 3D animal models and 140 corresponding sketch queries. Our contest requires participants to retrieve 3D models based on complex and detailed sketches. We receive satisfactory results from eight teams and 204 runs. Although further improvement is necessary, the proposed task has the potential to incentivize additional research in the domain of 3D object retrieval, potentially yielding benefits for a wide range of applications. We also provide insights into potential areas of future research, such as improving techniques for feature extraction and matching, and creating more diverse datasets to evaluate retrieval performance.
SHREC 2022: pothole and crack detection in the road pavement using images and RGB-D data
May 27, 2022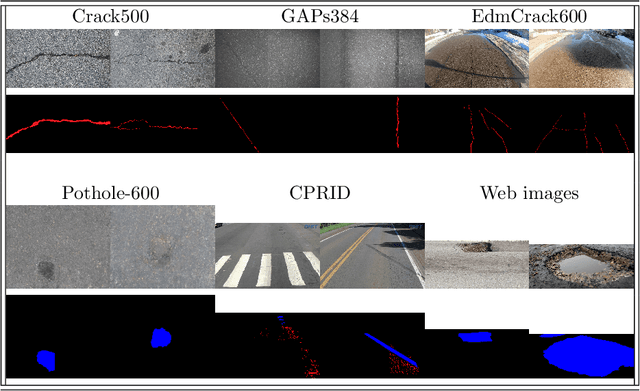
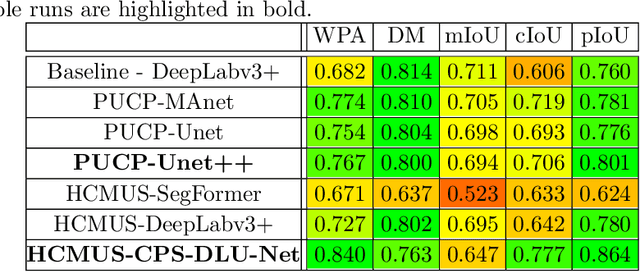

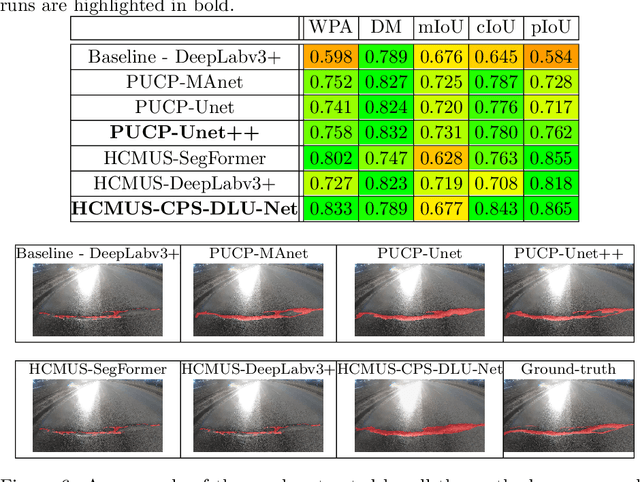
This paper describes the methods submitted for evaluation to the SHREC 2022 track on pothole and crack detection in the road pavement. A total of 7 different runs for the semantic segmentation of the road surface are compared, 6 from the participants plus a baseline method. All methods exploit Deep Learning techniques and their performance is tested using the same environment (i.e.: a single Jupyter notebook). A training set, composed of 3836 semantic segmentation image/mask pairs and 797 RGB-D video clips collected with the latest depth cameras was made available to the participants. The methods are then evaluated on the 496 image/mask pairs in the validation set, on the 504 pairs in the test set and finally on 8 video clips. The analysis of the results is based on quantitative metrics for image segmentation and qualitative analysis of the video clips. The participation and the results show that the scenario is of great interest and that the use of RGB-D data is still challenging in this context.