 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval-aligned Tabular Foundation Models Enable Robust Clinical Risk Prediction in Electronic Health Records Under Real-world Constraints
Apr 02, 2026Clinical prediction from structured electronic health records (EHRs) is challenging due to high dimensionality, heterogeneity, class imbalance, and distribution shift. While tabular in-context learning (TICL) and retrieval-augmented methods perform well on generic benchmarks, their behavior in clinical settings remains unclear. We present a multi-cohort EHR benchmark comparing classical, deep tabular, and TICL models across varying data scale, feature dimensionality, outcome rarity, and cross-cohort generalization. PFN-based TICL models are sample-efficient in low-data regimes but degrade under naive distance-based retrieval as heterogeneity and imbalance increase. We propose AWARE, a task-aligned retrieval framework using supervised embedding learning and lightweight adapters. AWARE improves AUPRC by up to 12.2% under extreme imbalance, with gains increasing with data complexity. Our results identify retrieval quality and retrieval-inference alignment as key bottlenecks for deploying tabular in-context learning in clinical prediction.
Explainable AI for Infection Prevention and Control: Modeling CPE Acquisition and Patient Outcomes in an Irish Hospital with Transformers
Sep 18, 2025Carbapenemase-Producing Enterobacteriace poses a critical concern for infection prevention and control in hospitals. However, predictive modeling of previously highlighted CPE-associated risks such as readmission, mortality, and extended length of stay (LOS) remains underexplored, particularly with modern deep learning approaches. This study introduces an eXplainable AI modeling framework to investigate CPE impact on patient outcomes from Electronic Medical Records data of an Irish hospital. We analyzed an inpatient dataset from an Irish acute hospital, incorporating diagnostic codes, ward transitions, patient demographics, infection-related variables and contact network features. Several Transformer-based architectures were benchmarked alongside traditional machine learning models. Clinical outcomes were predicted, and XAI techniques were applied to interpret model decisions. Our framework successfully demonstrated the utility of Transformer-based models, with TabTransformer consistently outperforming baselines across multiple clinical prediction tasks, especially for CPE acquisition (AUROC and sensitivity). We found infection-related features, including historical hospital exposure, admission context, and network centrality measures, to be highly influential in predicting patient outcomes and CPE acquisition risk. Explainability analyses revealed that features like "Area of Residence", "Admission Ward" and prior admissions are key risk factors. Network variables like "Ward PageRank" also ranked highly, reflecting the potential value of structural exposure information. This study presents a robust and explainable AI framework for analyzing complex EMR data to identify key risk factors and predict CPE-related outcomes. Our findings underscore the superior performance of the Transformer models and highlight the importance of diverse clinical and network features.
SHREC 2022: pothole and crack detection in the road pavement using images and RGB-D data
May 27, 2022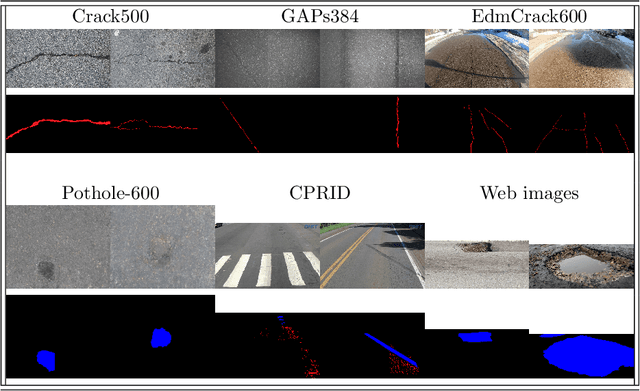
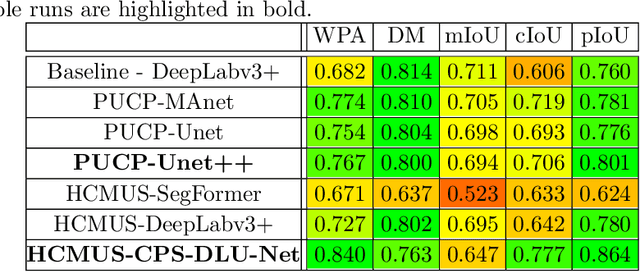

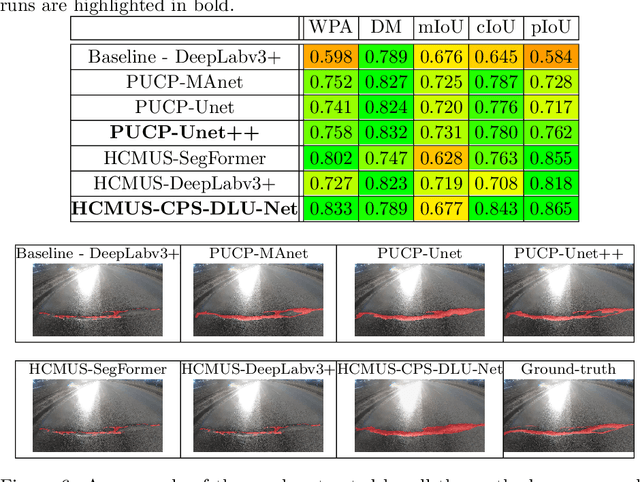
This paper describes the methods submitted for evaluation to the SHREC 2022 track on pothole and crack detection in the road pavement. A total of 7 different runs for the semantic segmentation of the road surface are compared, 6 from the participants plus a baseline method. All methods exploit Deep Learning techniques and their performance is tested using the same environment (i.e.: a single Jupyter notebook). A training set, composed of 3836 semantic segmentation image/mask pairs and 797 RGB-D video clips collected with the latest depth cameras was made available to the participants. The methods are then evaluated on the 496 image/mask pairs in the validation set, on the 504 pairs in the test set and finally on 8 video clips. The analysis of the results is based on quantitative metrics for image segmentation and qualitative analysis of the video clips. The participation and the results show that the scenario is of great interest and that the use of RGB-D data is still challenging in this context.