 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHANCLIP: A Family of Hyperbolic Angular Negation Vision Language Models
Jun 22, 2026Vision-Language Models (VLMs) are typically pre-trained on large-scale image-text datasets to capture semantic correspondences between visual content and natural language. However, they remain surprisingly brittle to negation: models often rely on shallow word co-occurrence and are easily distracted by misleading or irrelevant textual cues, even when their overall retrieval or classification performance is strong. Moreover, directly finetuning on negation data can interfere with previously acquired knowledge, causing noticeable degradation on standard vision-language benchmarks. To tackle these issues, this work introduces HANCLIP (Hyperbolic + Angular + Negation), a family of VLMs that explicitly restructures the embedding space to encode "what an image is not" alongside "what it is." HANCLIP is trained on a compact set of 20,000 image-text quadruplets and combines a hyperbolic formulation, which models hierarchical semantic relations and asymmetries, with an angular triplet objective that drives systematic separation between negated descriptions and their corresponding positives. This geometry-aware design strengthens negation sensitivity while preserving the global structure of pretrained representations, rather than overwriting them. Extensive experiments across multiple vision-language tasks show that HANCLIP delivers consistent gains on the negation-focused NegBench benchmark, while maintaining competitive or improved performance on standard classification and image-text retrieval benchmarks. The framework is model-agnostic and can be plugged into CLIP, LongCLIP, SmartCLIP, and HiMo-CLIP without large-scale retraining, demonstrating that a carefully designed geometric objective can substantially extend the reasoning capabilities of existing VLMs using only modest additional data.
Detecting Rumours with Latency Guarantees using Massive Streaming Data
May 13, 2022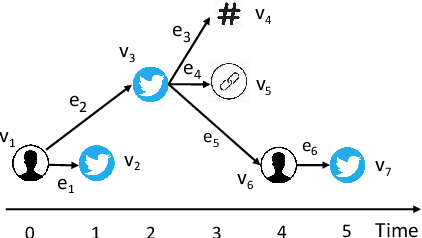

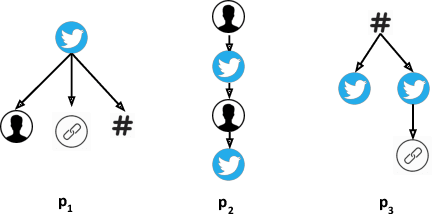
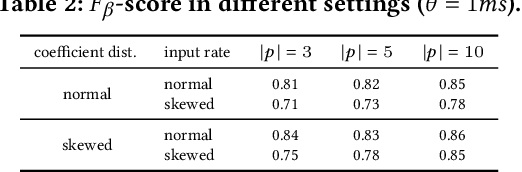
Today's social networks continuously generate massive streams of data, which provide a valuable starting point for the detection of rumours as soon as they start to propagate. However, rumour detection faces tight latency bounds, which cannot be met by contemporary algorithms, given the sheer volume of high-velocity streaming data emitted by social networks. Hence, in this paper, we argue for best-effort rumour detection that detects most rumours quickly rather than all rumours with a high delay. To this end, we combine techniques for efficient, graph-based matching of rumour patterns with effective load shedding that discards some of the input data while minimising the loss in accuracy. Experiments with large-scale real-world datasets illustrate the robustness of our approach in terms of runtime performance and detection accuracy under diverse streaming conditions.