 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmented 3D Semantic Scene Completion with 2D Segmentation Priors
Nov 26, 2021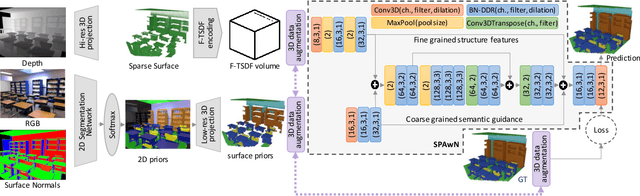
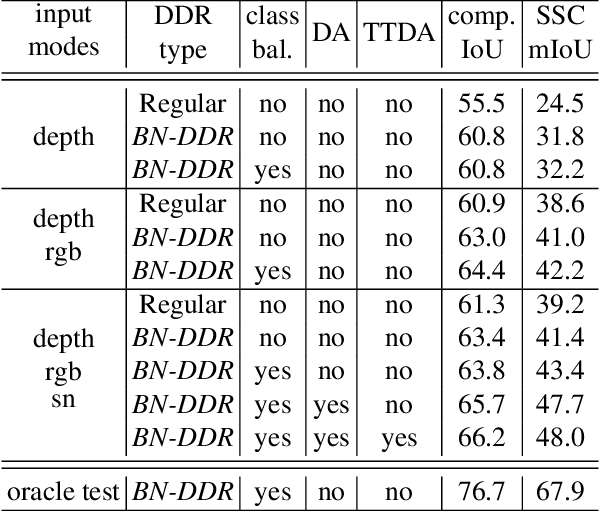
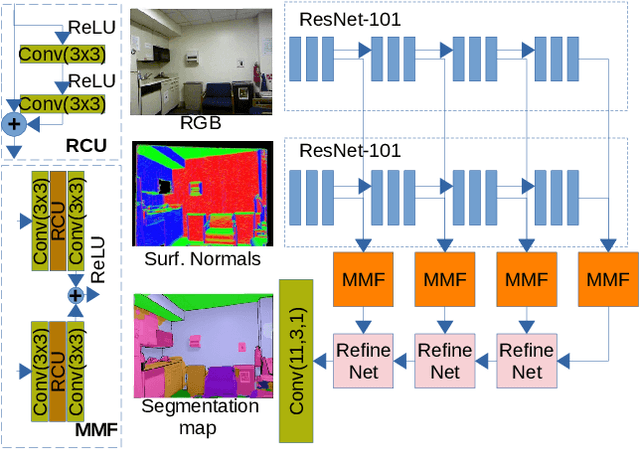
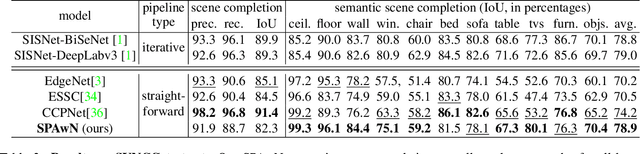
Semantic scene completion (SSC) is a challenging Computer Vision task with many practical applications, from robotics to assistive computing. Its goal is to infer the 3D geometry in a field of view of a scene and the semantic labels of voxels, including occluded regions. In this work, we present SPAwN, a novel lightweight multimodal 3D deep CNN that seamlessly fuses structural data from the depth component of RGB-D images with semantic priors from a bimodal 2D segmentation network. A crucial difficulty in this field is the lack of fully labeled real-world 3D datasets which are large enough to train the current data-hungry deep 3D CNNs. In 2D computer vision tasks, many data augmentation strategies have been proposed to improve the generalization ability of CNNs. However those approaches cannot be directly applied to the RGB-D input and output volume of SSC solutions. In this paper, we introduce the use of a 3D data augmentation strategy that can be applied to multimodal SSC networks. We validate our contributions with a comprehensive and reproducible ablation study. Our solution consistently surpasses previous works with a similar level of complexity.
Research Frontiers in Transfer Learning -- a systematic and bibliometric review
Dec 18, 2019



Humans can learn from very few samples, demonstrating an outstanding generalization ability that learning algorithms are still far from reaching. Currently, the most successful models demand enormous amounts of well-labeled data, which are expensive and difficult to obtain, becoming one of the biggest obstacles to the use of machine learning in practice. This scenario shows the massive potential for Transfer Learning, which aims to harness previously acquired knowledge to the learning of new tasks more effectively and efficiently. In this systematic review, we apply a quantitative method to select the main contributions to the field and make use of bibliographic coupling metrics to identify research frontiers. We further analyze the linguistic variation between the classics of the field and the frontier and map promising research directions.
Domain adaptation for holistic skin detection
Mar 16, 2019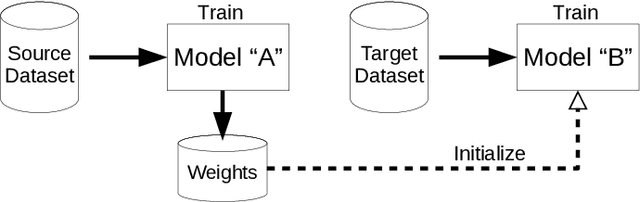
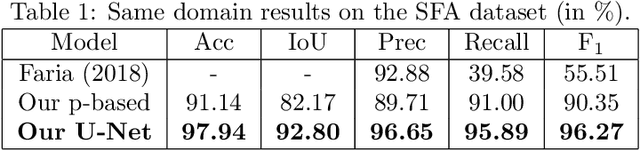
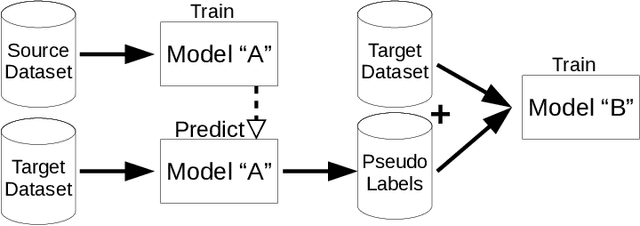
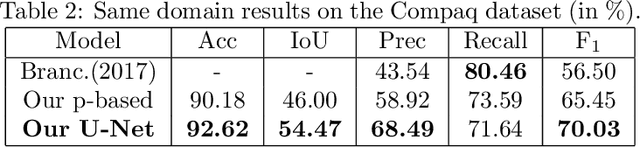
Human skin detection in images is a widely studied topic of Computer Vision for which it is commonly accepted that analysis of pixel color or local patches may suffice. This is because skin regions appear to be relatively uniform and many argue that there is a small chromatic variation among different samples. However, we found that there are strong biases in the datasets commonly used to train or tune skin detection methods. Furthermore, the lack of contextual information may hinder the performance of local approaches. In this paper we present a comprehensive evaluation of holistic and local Convolutional Neural Network (CNN) approaches on in-domain and cross-domain experiments and compare with state-of-the-art pixel-based approaches. We also propose a combination of inductive transfer learning and unsupervised domain adaptation methods, which are evaluated on different domains under several amounts of labelled data availability. We show a clear superiority of CNN over pixel-based approaches even without labelled training samples on the target domain. Furthermore, we provide experimental support for the counter-intuitive superiority of holistic over local approaches for human skin detection.