 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-Based Speech Enhancement with Joint Generative and Predictive Decoders
May 18, 2023



Diffusion-based speech enhancement (SE) has been investigated recently, but its decoding is very time-consuming. One solution is to initialize the decoding process with the enhanced feature estimated by a predictive SE system. However, this two-stage method ignores the complementarity between predictive and diffusion SE. In this paper, we propose a unified system that integrates these two SE modules. The system encodes both generative and predictive information, and then applies both generative and predictive decoders, whose outputs are fused. Specifically, the two SE modules are fused in the first and final diffusion steps: the first step fusion initializes the diffusion process with the predictive SE for improving the convergence, and the final step fusion combines the two complementary SE outputs to improve the SE performance. Experiments on the Voice-Bank dataset show that the diffusion score estimation can benefit from the predictive information and speed up the decoding.
Time-domain Speech Enhancement Assisted by Multi-resolution Frequency Encoder and Decoder
Mar 26, 2023



Time-domain speech enhancement (SE) has recently been intensively investigated. Among recent works, DEMUCS introduces multi-resolution STFT loss to enhance performance. However, some resolutions used for STFT contain non-stationary signals, and it is challenging to learn multi-resolution frequency losses simultaneously with only one output. For better use of multi-resolution frequency information, we supplement multiple spectrograms in different frame lengths into the time-domain encoders. They extract stationary frequency information in both narrowband and wideband. We also adopt multiple decoder outputs, each of which computes its corresponding resolution frequency loss. Experimental results show that (1) it is more effective to fuse stationary frequency features than non-stationary features in the encoder, and (2) the multiple outputs consistent with the frequency loss improve performance. Experiments on the Voice-Bank dataset show that the proposed method obtained a 0.14 PESQ improvement.
I Know Your Feelings Before You Do: Predicting Future Affective Reactions in Human-Computer Dialogue
Mar 17, 2023



Current Spoken Dialogue Systems (SDSs) often serve as passive listeners that respond only after receiving user speech. To achieve human-like dialogue, we propose a novel future prediction architecture that allows an SDS to anticipate future affective reactions based on its current behaviors before the user speaks. In this work, we investigate two scenarios: speech and laughter. In speech, we propose to predict the user's future emotion based on its temporal relationship with the system's current emotion and its causal relationship with the system's current Dialogue Act (DA). In laughter, we propose to predict the occurrence and type of the user's laughter using the system's laughter behaviors in the current turn. Preliminary analysis of human-robot dialogue demonstrated synchronicity in the emotions and laughter displayed by the human and robot, as well as DA-emotion causality in their dialogue. This verifies that our architecture can contribute to the development of an anticipatory SDS.
Alzheimer's Dementia Detection through Spontaneous Dialogue with Proactive Robotic Listeners
Nov 15, 2022

As the aging of society continues to accelerate, Alzheimer's Disease (AD) has received more and more attention from not only medical but also other fields, such as computer science, over the past decade. Since speech is considered one of the effective ways to diagnose cognitive decline, AD detection from speech has emerged as a hot topic. Nevertheless, such approaches fail to tackle several key issues: 1) AD is a complex neurocognitive disorder which means it is inappropriate to conduct AD detection using utterance information alone while ignoring dialogue information; 2) Utterances of AD patients contain many disfluencies that affect speech recognition yet are helpful to diagnosis; 3) AD patients tend to speak less, causing dialogue breakdown as the disease progresses. This fact leads to a small number of utterances, which may cause detection bias. Therefore, in this paper, we propose a novel AD detection architecture consisting of two major modules: an ensemble AD detector and a proactive listener. This architecture can be embedded in the dialogue system of conversational robots for healthcare.
Non-autoregressive Error Correction for CTC-based ASR with Phone-conditioned Masked LM
Sep 08, 2022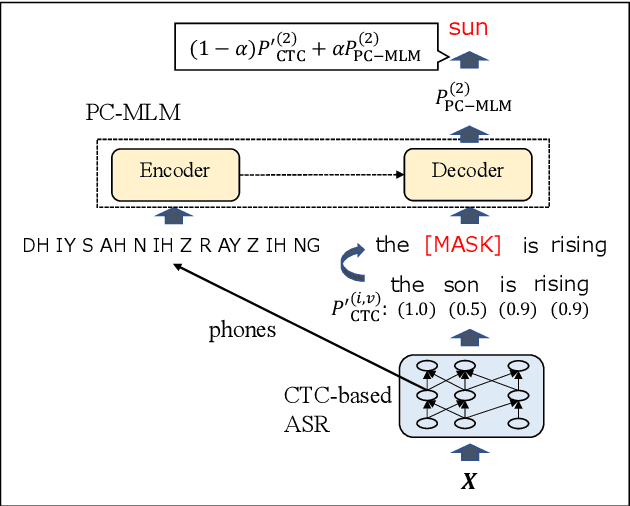
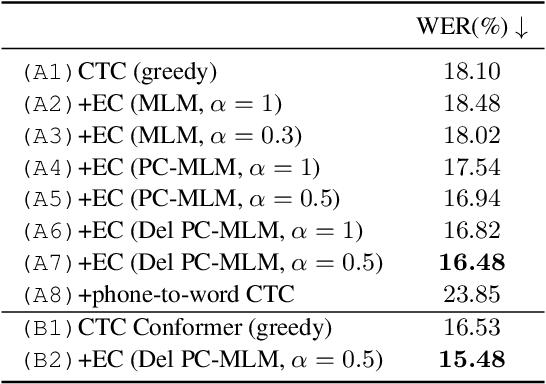
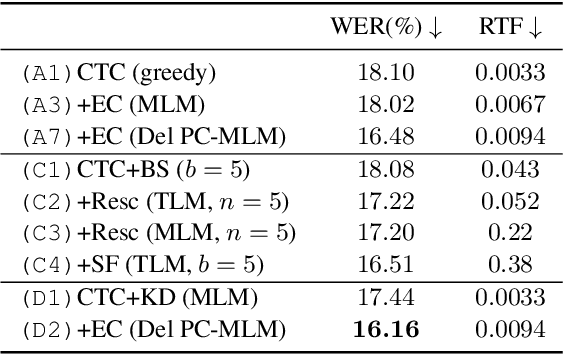
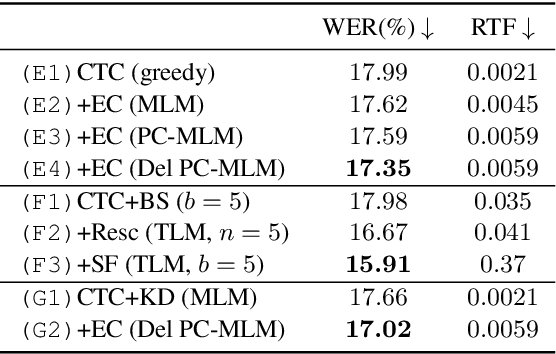
Connectionist temporal classification (CTC) -based models are attractive in automatic speech recognition (ASR) because of their non-autoregressive nature. To take advantage of text-only data, language model (LM) integration approaches such as rescoring and shallow fusion have been widely used for CTC. However, they lose CTC's non-autoregressive nature because of the need for beam search, which slows down the inference speed. In this study, we propose an error correction method with phone-conditioned masked LM (PC-MLM). In the proposed method, less confident word tokens in a greedy decoded output from CTC are masked. PC-MLM then predicts these masked word tokens given unmasked words and phones supplementally predicted from CTC. We further extend it to Deletable PC-MLM in order to address insertion errors. Since both CTC and PC-MLM are non-autoregressive models, the method enables fast LM integration. Experimental evaluations on the Corpus of Spontaneous Japanese (CSJ) and TED-LIUM2 in domain adaptation setting shows that our proposed method outperformed rescoring and shallow fusion in terms of inference speed, and also in terms of recognition accuracy on CSJ.
Distilling the Knowledge of BERT for CTC-based ASR
Sep 05, 2022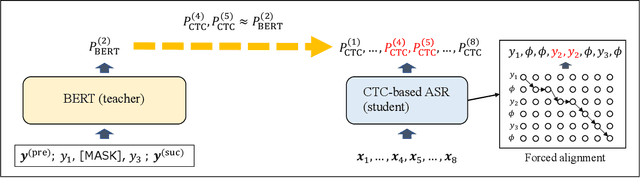
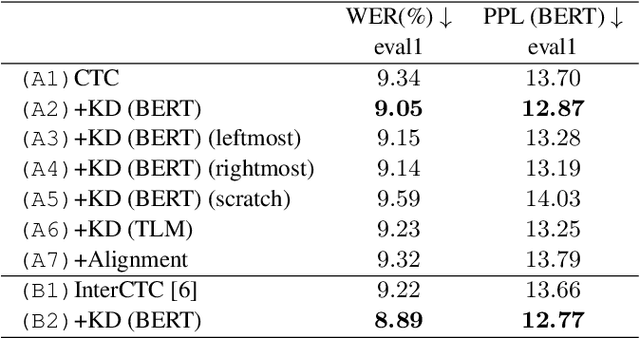
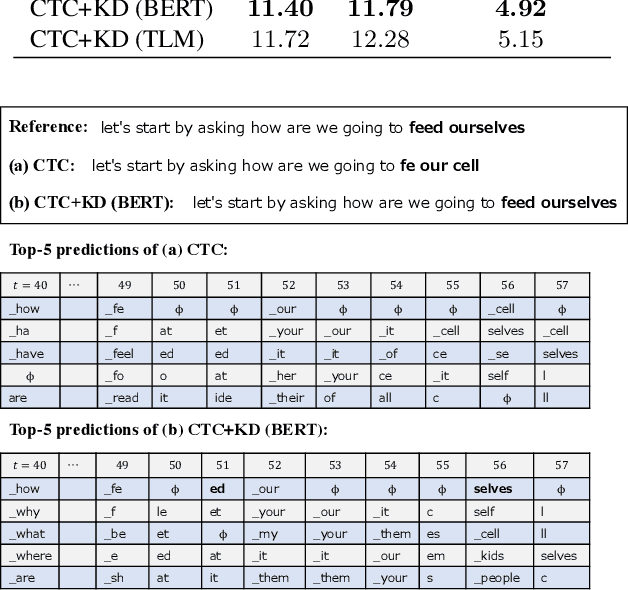
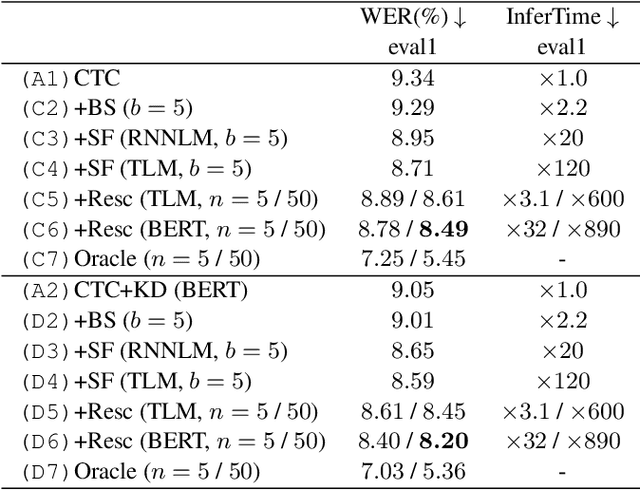
Connectionist temporal classification (CTC) -based models are attractive because of their fast inference in automatic speech recognition (ASR). Language model (LM) integration approaches such as shallow fusion and rescoring can improve the recognition accuracy of CTC-based ASR by taking advantage of the knowledge in text corpora. However, they significantly slow down the inference of CTC. In this study, we propose to distill the knowledge of BERT for CTC-based ASR, extending our previous study for attention-based ASR. CTC-based ASR learns the knowledge of BERT during training and does not use BERT during testing, which maintains the fast inference of CTC. Different from attention-based models, CTC-based models make frame-level predictions, so they need to be aligned with token-level predictions of BERT for distillation. We propose to obtain alignments by calculating the most plausible CTC paths. Experimental evaluations on the Corpus of Spontaneous Japanese (CSJ) and TED-LIUM2 show that our method improves the performance of CTC-based ASR without the cost of inference speed.
End-to-end Speech-to-Punctuated-Text Recognition
Jul 07, 2022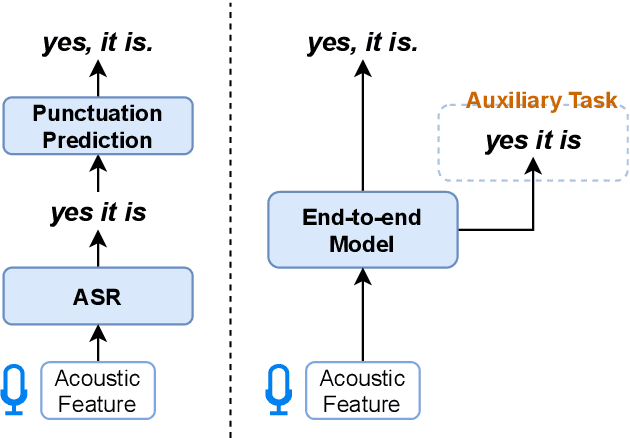
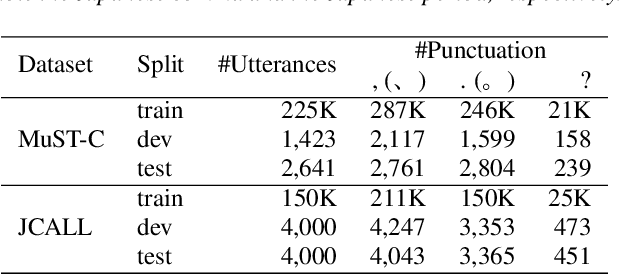

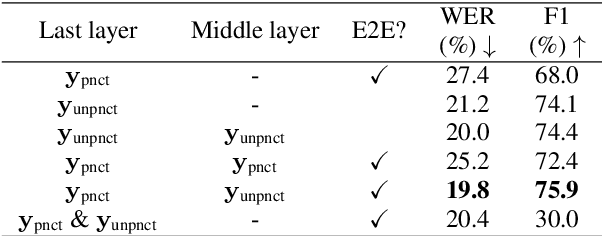
Conventional automatic speech recognition systems do not produce punctuation marks which are important for the readability of the speech recognition results. They are also needed for subsequent natural language processing tasks such as machine translation. There have been a lot of works on punctuation prediction models that insert punctuation marks into speech recognition results as post-processing. However, these studies do not utilize acoustic information for punctuation prediction and are directly affected by speech recognition errors. In this study, we propose an end-to-end model that takes speech as input and outputs punctuated texts. This model is expected to predict punctuation robustly against speech recognition errors while using acoustic information. We also propose to incorporate an auxiliary loss to train the model using the output of the intermediate layer and unpunctuated texts. Through experiments, we compare the performance of the proposed model to that of a cascaded system. The proposed model achieves higher punctuation prediction accuracy than the cascaded system without sacrificing the speech recognition error rate. It is also demonstrated that the multi-task learning using the intermediate output against the unpunctuated text is effective. Moreover, the proposed model has only about 1/7th of the parameters compared to the cascaded system.
ASR Rescoring and Confidence Estimation with ELECTRA
Oct 05, 2021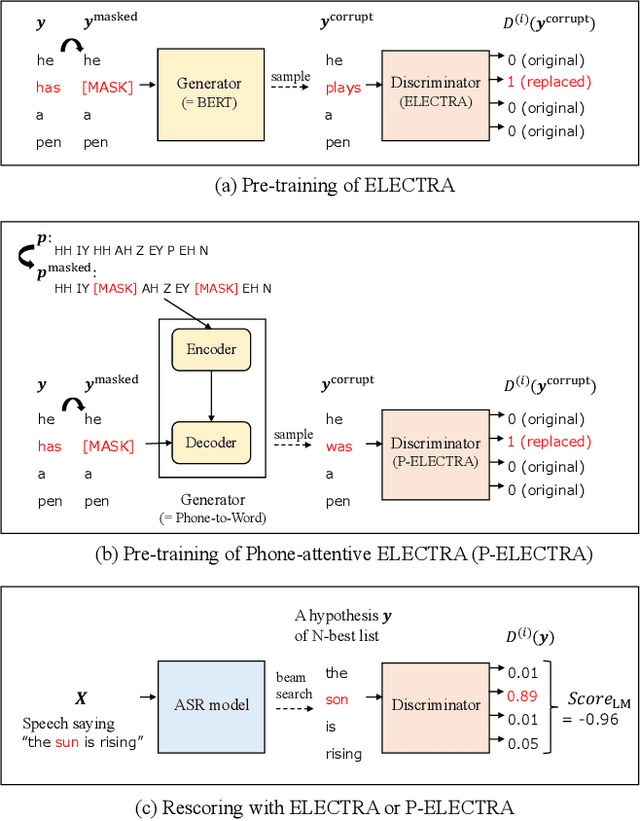

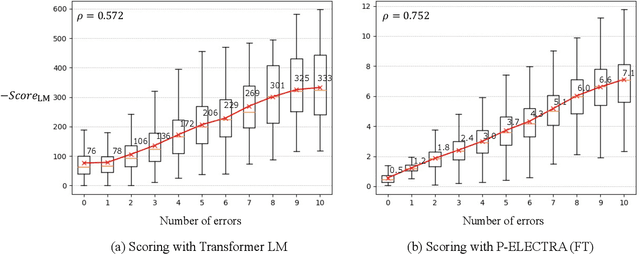
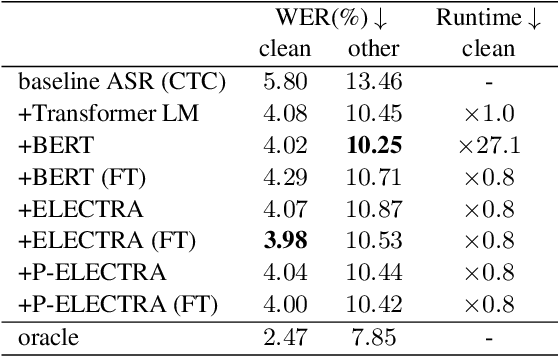
In automatic speech recognition (ASR) rescoring, the hypothesis with the fewest errors should be selected from the n-best list using a language model (LM). However, LMs are usually trained to maximize the likelihood of correct word sequences, not to detect ASR errors. We propose an ASR rescoring method for directly detecting errors with ELECTRA, which is originally a pre-training method for NLP tasks. ELECTRA is pre-trained to predict whether each word is replaced by BERT or not, which can simulate ASR error detection on large text corpora. To make this pre-training closer to ASR error detection, we further propose an extended version of ELECTRA called phone-attentive ELECTRA (P-ELECTRA). In the pre-training of P-ELECTRA, each word is replaced by a phone-to-word conversion model, which leverages phone information to generate acoustically similar words. Since our rescoring method is optimized for detecting errors, it can also be used for word-level confidence estimation. Experimental evaluations on the Librispeech and TED-LIUM2 corpora show that our rescoring method with ELECTRA is competitive with conventional rescoring methods with faster inference. ELECTRA also performs better in confidence estimation than BERT because it can learn to detect inappropriate words not only in fine-tuning but also in pre-training.
Non-autoregressive End-to-end Speech Translation with Parallel Autoregressive Rescoring
Sep 09, 2021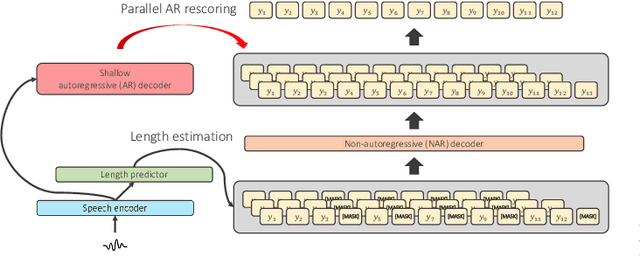
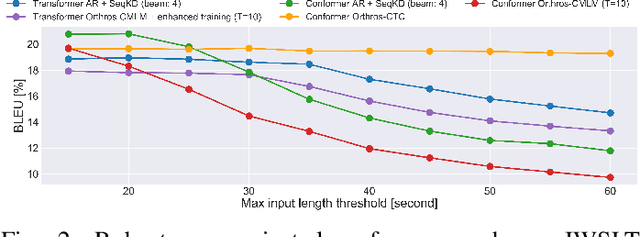
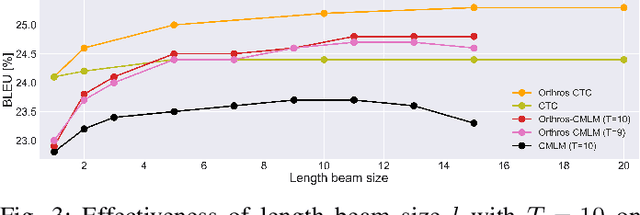
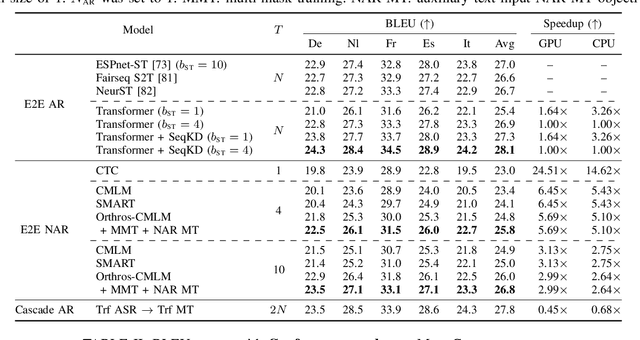
This article describes an efficient end-to-end speech translation (E2E-ST) framework based on non-autoregressive (NAR) models. End-to-end speech translation models have several advantages over traditional cascade systems such as inference latency reduction. However, conventional AR decoding methods are not fast enough because each token is generated incrementally. NAR models, however, can accelerate the decoding speed by generating multiple tokens in parallel on the basis of the token-wise conditional independence assumption. We propose a unified NAR E2E-ST framework called Orthros, which has an NAR decoder and an auxiliary shallow AR decoder on top of the shared encoder. The auxiliary shallow AR decoder selects the best hypothesis by rescoring multiple candidates generated from the NAR decoder in parallel (parallel AR rescoring). We adopt conditional masked language model (CMLM) and a connectionist temporal classification (CTC)-based model as NAR decoders for Orthros, referred to as Orthros-CMLM and Orthros-CTC, respectively. We also propose two training methods to enhance the CMLM decoder. Experimental evaluations on three benchmark datasets with six language directions demonstrated that Orthros achieved large improvements in translation quality with a very small overhead compared with the baseline NAR model. Moreover, the Conformer encoder architecture enabled large quality improvements, especially for CTC-based models. Orthros-CTC with the Conformer encoder increased decoding speed by 3.63x on CPU with translation quality comparable to that of an AR model.
VAD-free Streaming Hybrid CTC/Attention ASR for Unsegmented Recording
Jul 15, 2021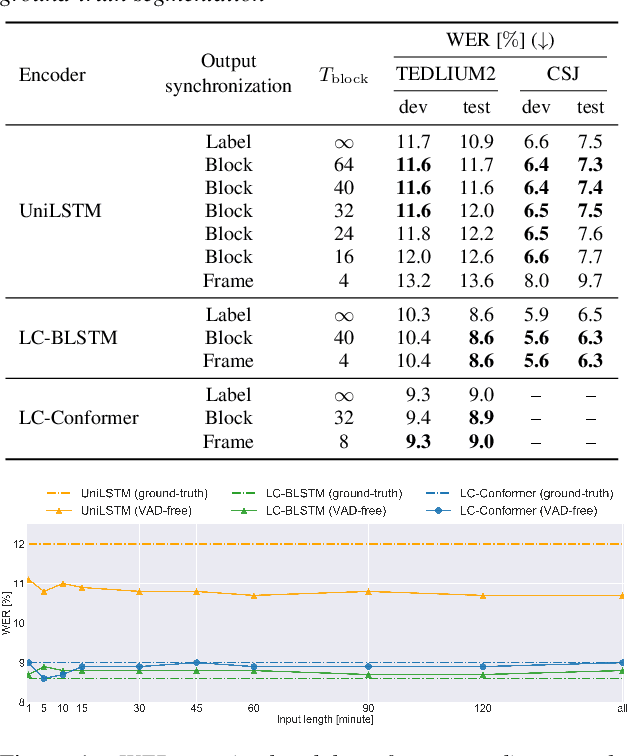
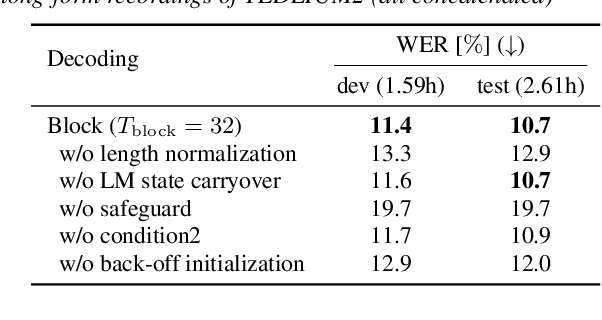
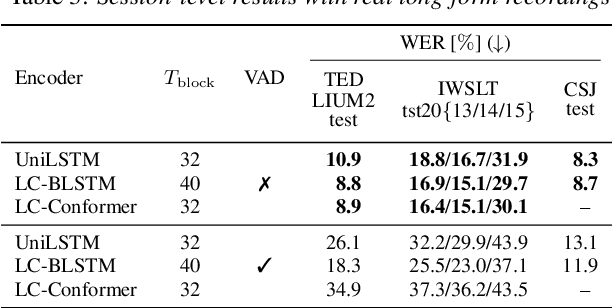
In this work, we propose novel decoding algorithms to enable streaming automatic speech recognition (ASR) on unsegmented long-form recordings without voice activity detection (VAD), based on monotonic chunkwise attention (MoChA) with an auxiliary connectionist temporal classification (CTC) objective. We propose a block-synchronous beam search decoding to take advantage of efficient batched output-synchronous and low-latency input-synchronous searches. We also propose a VAD-free inference algorithm that leverages CTC probabilities to determine a suitable timing to reset the model states to tackle the vulnerability to long-form data. Experimental evaluations demonstrate that the block-synchronous decoding achieves comparable accuracy to the label-synchronous one. Moreover, the VAD-free inference can recognize long-form speech robustly for up to a few hours.