 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Bottleneck Constrained Latent Bidirectional Embedding for Zero-Shot Learning
Sep 16, 2020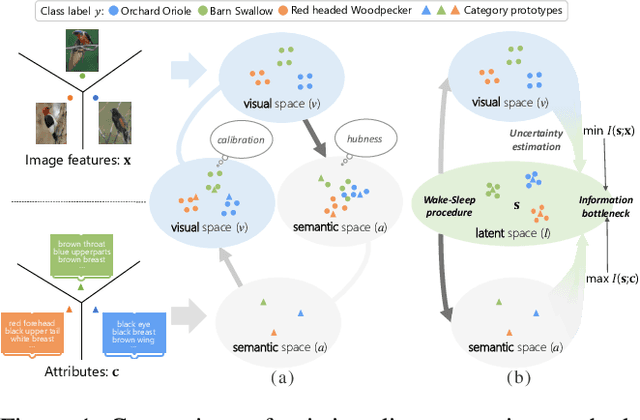
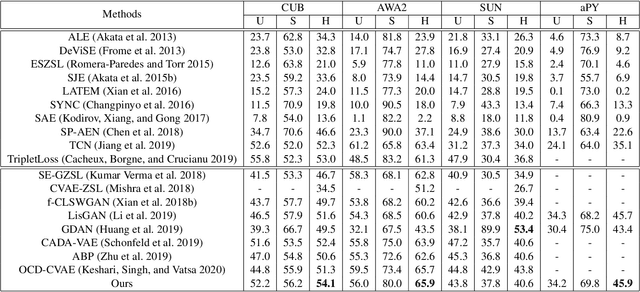
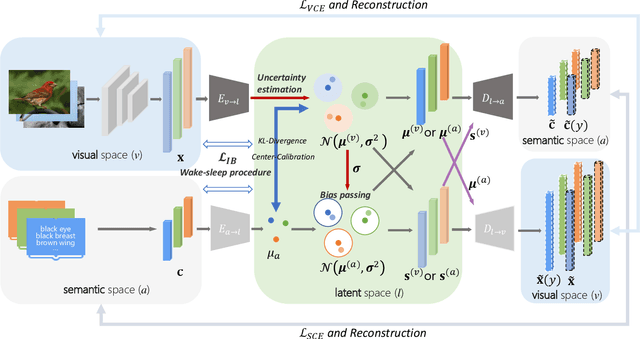
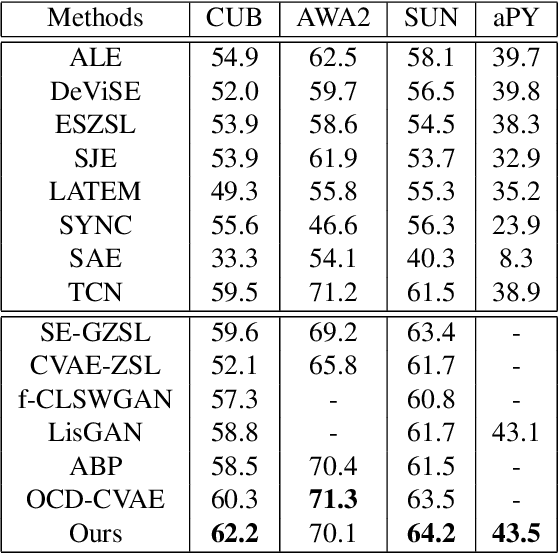
Zero-shot learning (ZSL) aims to recognize novel classes by transferring semantic knowledge from seen classes to unseen classes. Though many ZSL methods rely on a direct mapping between the visual and the semantic space, the calibration deviation and hubness problem limit the generalization capability to unseen classes. Recently emerged generative ZSL methods generate unseen image features to transform ZSL into a supervised classification problem. However, most generative models still suffer from the seen-unseen bias problem as only seen data is used for training. To address these issues, we propose a novel bidirectional embedding based generative model with a tight visual-semantic coupling constraint. We learn a unified latent space that calibrates the embedded parametric distributions of both visual and semantic spaces. Since the embedding from high-dimensional visual features comprise much non-semantic information, the alignment of visual and semantic in latent space would inevitably been deviated. Therefore, we introduce information bottleneck (IB) constraint to ZSL for the first time to preserve essential attribute information during the mapping. Specifically, we utilize the uncertainty estimation and the wake-sleep procedure to alleviate the noises and improve model abstraction capability. We evaluate the learned latent features on four benchmark datasets. Extensive experimental results show that our method outperforms the state-of-the-art methods in different ZSL settings on most benchmark datasets. The code will be available at https://github.com/osierboy/IBZSL.
Neural Granular Sound Synthesis
Aug 31, 2020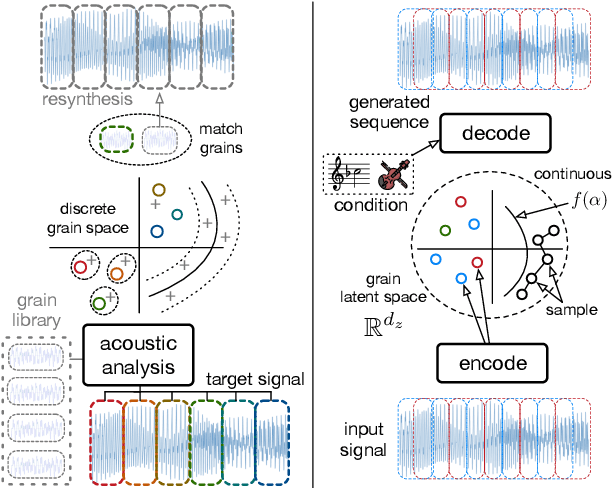
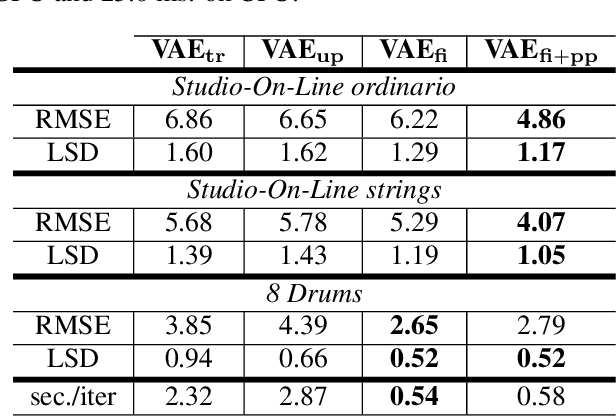
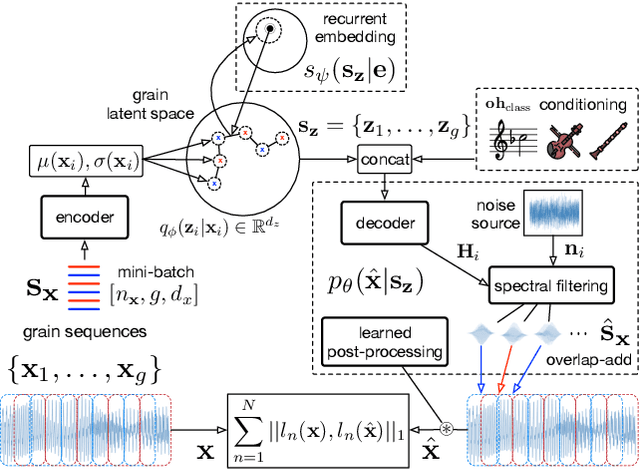
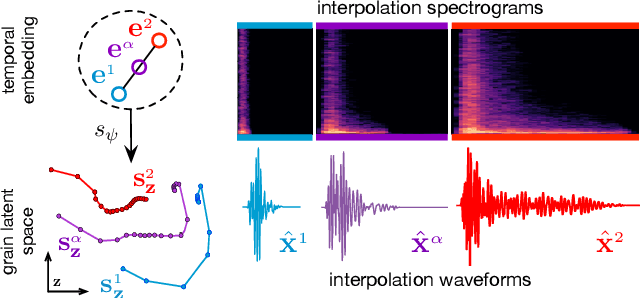
Granular sound synthesis is a popular audio generation technique based on rearranging sequences of small waveform windows. In order to control the synthesis, all grains in a given corpus are analyzed through a set of acoustic descriptors. This provides a representation reflecting some form of local similarities across the grains. However, the quality of this grain space is bound by that of the descriptors. Its traversal is not continuously invertible to signal and does not render any structured temporality. We demonstrate that generative neural networks can implement granular synthesis while alleviating most of its shortcomings. We efficiently replace its audio descriptor basis by a probabilistic latent space learned with a Variational Auto-Encoder. A major advantage of our proposal is that the resulting grain space is invertible, meaning that we can continuously synthesize sound when traversing its dimensions. It also implies that original grains are not stored for synthesis. To learn structured paths inside this latent space, we add a higher-level temporal embedding trained on arranged grain sequences. The model can be applied to many types of libraries, including pitched notes or unpitched drums and environmental noises. We experiment with the common granular synthesis processes and enable new ones.
Learning Agile Locomotion via Adversarial Training
Aug 03, 2020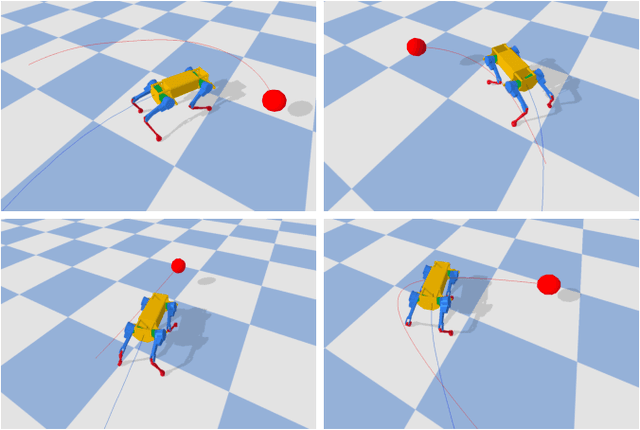
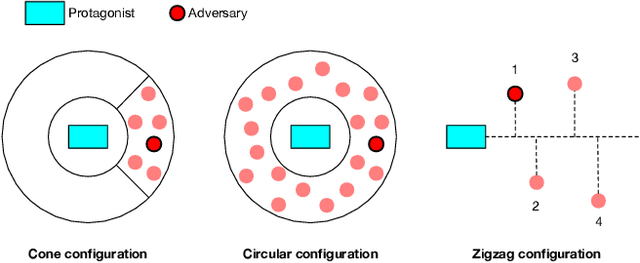

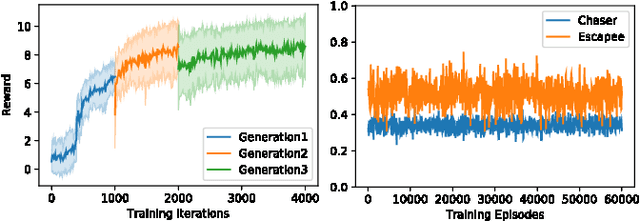
Developing controllers for agile locomotion is a long-standing challenge for legged robots. Reinforcement learning (RL) and Evolution Strategy (ES) hold the promise of automating the design process of such controllers. However, dedicated and careful human effort is required to design training environments to promote agility. In this paper, we present a multi-agent learning system, in which a quadruped robot (protagonist) learns to chase another robot (adversary) while the latter learns to escape. We find that this adversarial training process not only encourages agile behaviors but also effectively alleviates the laborious environment design effort. In contrast to prior works that used only one adversary, we find that training an ensemble of adversaries, each of which specializes in a different escaping strategy, is essential for the protagonist to master agility. Through extensive experiments, we show that the locomotion controller learned with adversarial training significantly outperforms carefully designed baselines.
Point Cloud Based Reinforcement Learning for Sim-to-Real and Partial Observability in Visual Navigation
Jul 27, 2020
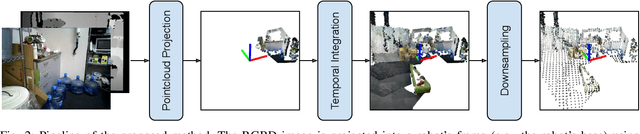
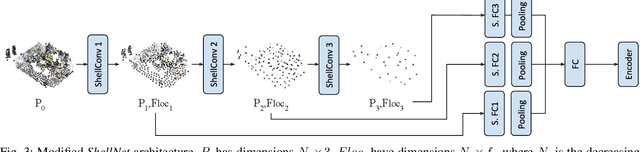
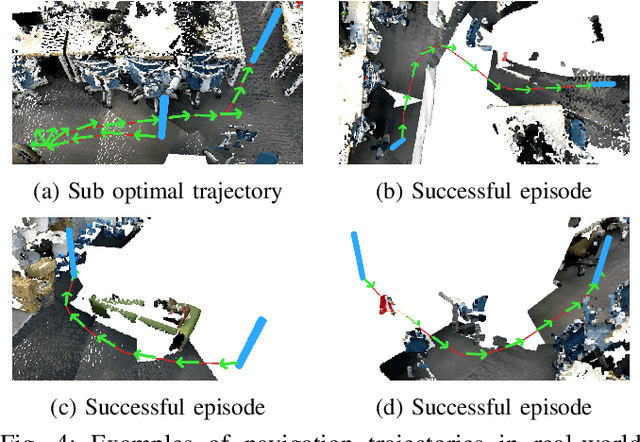
Reinforcement Learning (RL), among other learning-based methods, represents powerful tools to solve complex robotic tasks (e.g., actuation, manipulation, navigation, etc.), with the need for real-world data to train these systems as one of its most important limitations. The use of simulators is one way to address this issue, yet knowledge acquired in simulations does not work directly in the real-world, which is known as the sim-to-real transfer problem. While previous works focus on the nature of the images used as observations (e.g., textures and lighting), which has proven useful for a sim-to-sim transfer, they neglect other concerns regarding said observations, such as precise geometrical meanings, failing at robot-to-robot, and thus in sim-to-real transfers. We propose a method that learns on an observation space constructed by point clouds and environment randomization, generalizing among robots and simulators to achieve sim-to-real, while also addressing partial observability. We demonstrate the benefits of our methodology on the point goal navigation task, in which our method proves to be highly unaffected to unseen scenarios produced by robot-to-robot transfer, outperforms image-based baselines in robot-randomized experiments, and presents high performances in sim-to-sim conditions. Finally, we perform several experiments to validate the sim-to-real transfer to a physical domestic robot platform, confirming the out-of-the-box performance of our system.
Vector-Quantized Timbre Representation
Jul 13, 2020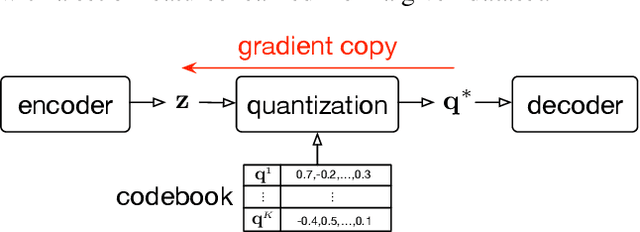
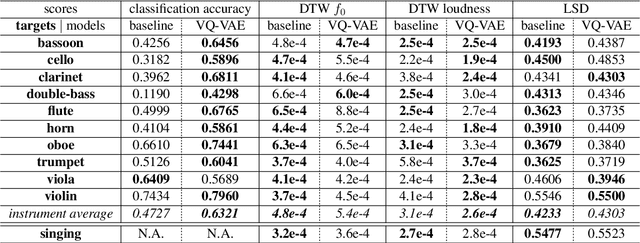

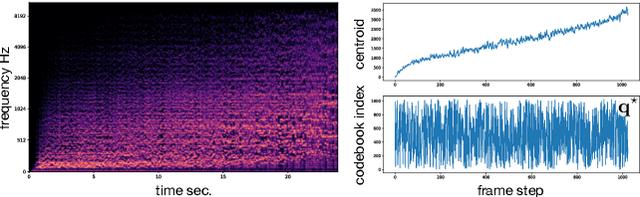
Timbre is a set of perceptual attributes that identifies different types of sound sources. Although its definition is usually elusive, it can be seen from a signal processing viewpoint as all the spectral features that are perceived independently from pitch and loudness. Some works have studied high-level timbre synthesis by analyzing the feature relationships of different instruments, but acoustic properties remain entangled and generation bound to individual sounds. This paper targets a more flexible synthesis of an individual timbre by learning an approximate decomposition of its spectral properties with a set of generative features. We introduce an auto-encoder with a discrete latent space that is disentangled from loudness in order to learn a quantized representation of a given timbre distribution. Timbre transfer can be performed by encoding any variable-length input signals into the quantized latent features that are decoded according to the learned timbre. We detail results for translating audio between orchestral instruments and singing voice, as well as transfers from vocal imitations to instruments as an intuitive modality to drive sound synthesis. Furthermore, we can map the discrete latent space to acoustic descriptors and directly perform descriptor-based synthesis.
SplitFusion: Simultaneous Tracking and Mapping for Non-Rigid Scenes
Jul 04, 2020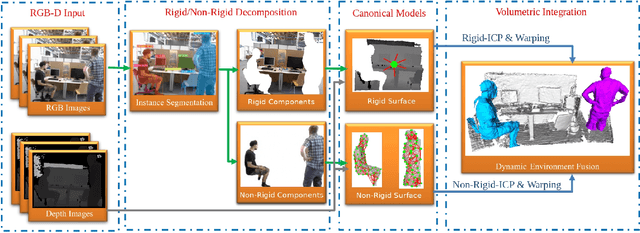



We present SplitFusion, a novel dense RGB-D SLAM framework that simultaneously performs tracking and dense reconstruction for both rigid and non-rigid components of the scene. SplitFusion first adopts deep learning based semantic instant segmentation technique to split the scene into rigid or non-rigid surfaces. The split surfaces are independently tracked via rigid or non-rigid ICP and reconstructed through incremental depth map fusion. Experimental results show that the proposed approach can provide not only accurate environment maps but also well-reconstructed non-rigid targets, e.g. the moving humans.
Hyperbolic Neural Networks++
Jun 15, 2020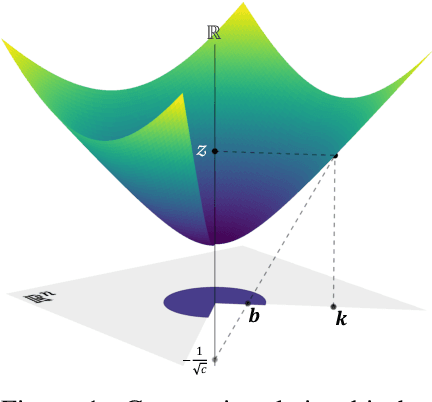
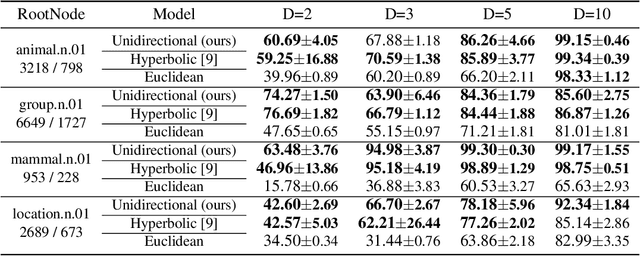
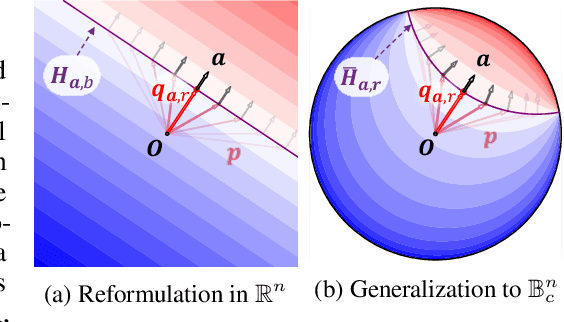

Hyperbolic spaces, which have the capacity to embed tree structures without distortion owing to their exponential volume growth, have recently been applied to machine learning to better capture the hierarchical nature of data. In this study, we reconsider a way to generalize the fundamental components of neural networks in a single hyperbolic geometry model, and propose novel methodologies to construct a multinomial logistic regression, fully-connected layers, convolutional layers, and attention mechanisms under a unified mathematical interpretation, without increasing the parameters. A series of experiments show the parameter efficiency of our methods compared to a conventional hyperbolic component, and stability and outperformance over their Euclidean counterparts.
Unsupervised Brain Abnormality Detection Using High Fidelity Image Reconstruction Networks
Jun 02, 2020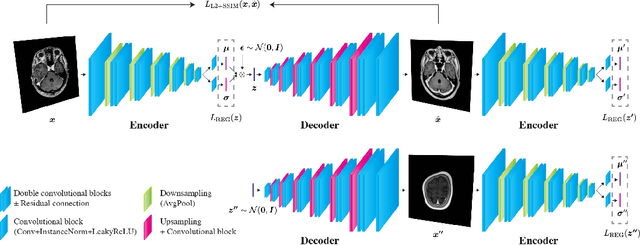

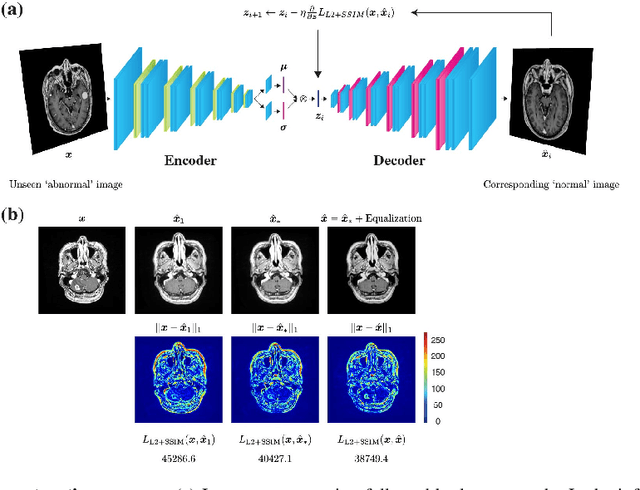
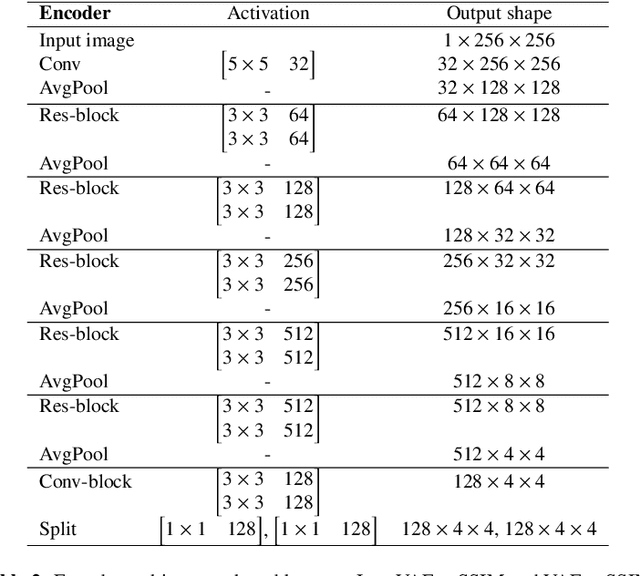
Recent advances in deep learning have facilitated near-expert medical image analysis. Supervised learning is the mainstay of current approaches, though its success requires the use of large, fully labeled datasets. However, in real-world medical practice, previously unseen disease phenotypes are encountered that have not been defined a priori in finite-size datasets. Unsupervised learning, a hypothesis-free learning framework, may play a complementary role to supervised learning. Here, we demonstrate a novel framework for voxel-wise abnormality detection in brain magnetic resonance imaging (MRI), which exploits an image reconstruction network based on an introspective variational autoencoder trained with a structural similarity constraint. The proposed network learns a latent representation for "normal" anatomical variation using a series of images that do not include annotated abnormalities. After training, the network can map unseen query images to positions in the latent space, and latent variables sampled from those positions can be mapped back to the image space to yield normal-looking replicas of the input images. Finally, the network considers abnormality scores, which are designed to reflect differences at several image feature levels, in order to locate image regions that may contain abnormalities. The proposed method is evaluated on a comprehensively annotated dataset spanning clinically significant structural abnormalities of the brain parenchyma in a population having undergone radiotherapy for brain metastasis, demonstrating that it is particularly effective for contrast-enhanced lesions, i.e., metastatic brain tumors and extracranial metastatic tumors.
Learning to Optimize Non-Rigid Tracking
Mar 27, 2020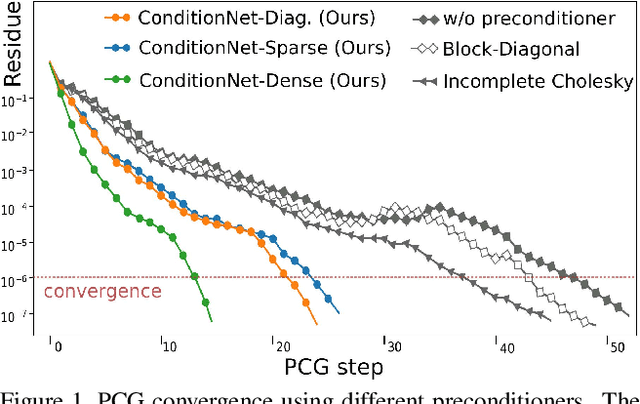
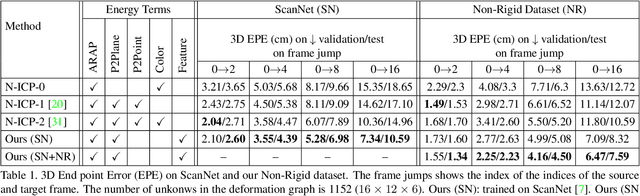
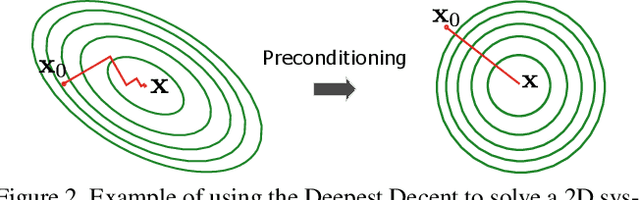
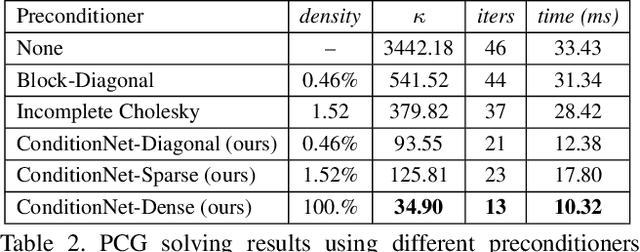
One of the widespread solutions for non-rigid tracking has a nested-loop structure: with Gauss-Newton to minimize a tracking objective in the outer loop, and Preconditioned Conjugate Gradient (PCG) to solve a sparse linear system in the inner loop. In this paper, we employ learnable optimizations to improve tracking robustness and speed up solver convergence. First, we upgrade the tracking objective by integrating an alignment data term on deep features which are learned end-to-end through CNN. The new tracking objective can capture the global deformation which helps Gauss-Newton to jump over local minimum, leading to robust tracking on large non-rigid motions. Second, we bridge the gap between the preconditioning technique and learning method by introducing a ConditionNet which is trained to generate a preconditioner such that PCG can converge within a small number of steps. Experimental results indicate that the proposed learning method converges faster than the original PCG by a large margin.
Blur, Noise, and Compression Robust Generative Adversarial Networks
Mar 17, 2020
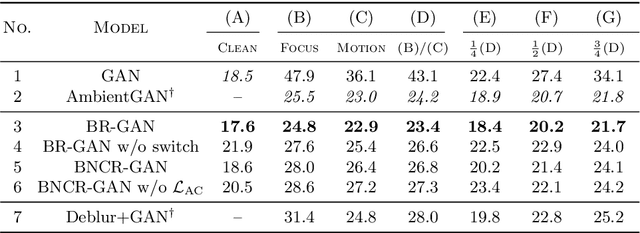
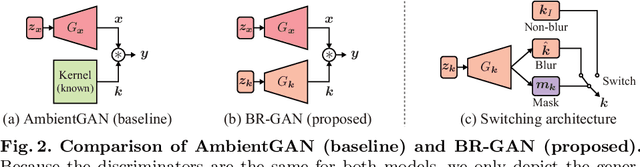
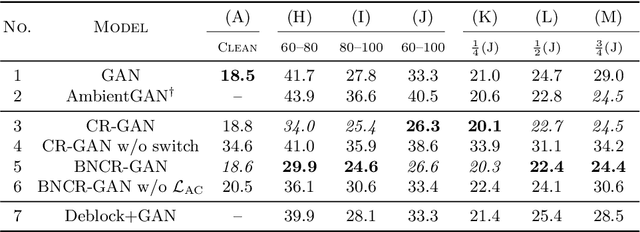
Recently, generative adversarial networks (GANs), which learn data distributions through adversarial training, have gained special attention owing to their high image reproduction ability. However, one limitation of standard GANs is that they recreate training images faithfully despite image degradation characteristics such as blur, noise, and compression. To remedy this, we address the problem of blur, noise, and compression robust image generation. Our objective is to learn a non-degraded image generator directly from degraded images without prior knowledge of image degradation. The recently proposed noise robust GAN (NR-GAN) already provides a solution to the problem of noise degradation. Therefore, we first focus on blur and compression degradations. We propose blur robust GAN (BR-GAN) and compression robust GAN (CR-GAN), which learn a kernel generator and quality factor generator, respectively, with non-degraded image generators. Owing to the irreversible blur and compression characteristics, adjusting their strengths is non-trivial. Therefore, we incorporate switching architectures that can adapt the strengths in a data-driven manner. Based on BR-GAN, NR-GAN, and CR-GAN, we further propose blur, noise, and compression robust GAN (BNCR-GAN), which unifies these three models into a single model with additionally introduced adaptive consistency losses that suppress the uncertainty caused by the combination. We provide benchmark scores through large-scale comparative studies on CIFAR-10 and a generality analysis on FFHQ dataset.