 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining inherent knowledge of vision-language models with unsupervised domain adaptation through self-knowledge distillation
Dec 11, 2023



Unsupervised domain adaptation (UDA) tries to overcome the tedious work of labeling data by leveraging a labeled source dataset and transferring its knowledge to a similar but different target dataset. On the other hand, current vision-language models exhibit astonishing zero-shot prediction capabilities. In this work, we combine knowledge gained through UDA with the inherent knowledge of vision-language models. In a first step, we generate the zero-shot predictions of the source and target dataset using the vision-language model. Since zero-shot predictions usually exhibit a large entropy, meaning that the class probabilities are rather evenly distributed, we first adjust the distribution to accentuate the winning probabilities. This is done using both source and target data to keep the relative confidence between source and target data. We then employ a conventional DA method, to gain the knowledge from the source dataset, in combination with self-knowledge distillation, to maintain the inherent knowledge of the vision-language model. We further combine our method with a gradual source domain expansion strategy (GSDE) and show that this strategy can also benefit by including zero-shot predictions. We conduct experiments and ablation studies on three benchmarks (OfficeHome, VisDA, and DomainNet) and outperform state-of-the-art methods. We further show in ablation studies the contributions of different parts of our algorithm.
Gradual Source Domain Expansion for Unsupervised Domain Adaptation
Nov 16, 2023Unsupervised domain adaptation (UDA) tries to overcome the need for a large labeled dataset by transferring knowledge from a source dataset, with lots of labeled data, to a target dataset, that has no labeled data. Since there are no labels in the target domain, early misalignment might propagate into the later stages and lead to an error build-up. In order to overcome this problem, we propose a gradual source domain expansion (GSDE) algorithm. GSDE trains the UDA task several times from scratch, each time reinitializing the network weights, but each time expands the source dataset with target data. In particular, the highest-scoring target data of the previous run are employed as pseudo-source samples with their respective pseudo-label. Using this strategy, the pseudo-source samples induce knowledge extracted from the previous run directly from the start of the new training. This helps align the two domains better, especially in the early training epochs. In this study, we first introduce a strong baseline network and apply our GSDE strategy to it. We conduct experiments and ablation studies on three benchmarks (Office-31, OfficeHome, and DomainNet) and outperform state-of-the-art methods. We further show that the proposed GSDE strategy can improve the accuracy of a variety of different state-of-the-art UDA approaches.
A General Upper Bound for Unsupervised Domain Adaptation
Oct 04, 2019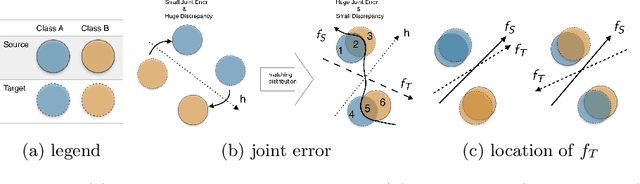
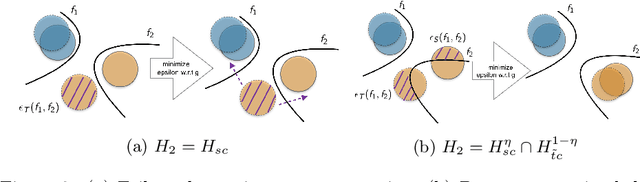

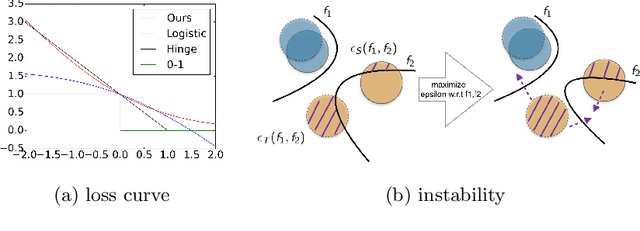
In this work, we present a novel upper bound of target error to address the problem for unsupervised domain adaptation. Recent studies reveal that a deep neural network can learn transferable features which generalize well to novel tasks. Furthermore, a theory proposed by Ben-David et al. (2010) provides a upper bound for target error when transferring the knowledge, which can be summarized as minimizing the source error and distance between marginal distributions simultaneously. However, common methods based on the theory usually ignore the joint error such that samples from different classes might be mixed together when matching marginal distribution. And in such case, no matter how we minimize the marginal discrepancy, the target error is not bounded due to an increasing joint error. To address this problem, we propose a general upper bound taking joint error into account, such that the undesirable case can be properly penalized. In addition, we utilize constrained hypothesis space to further formalize a tighter bound as well as a novel cross margin discrepancy to measure the dissimilarity between hypotheses which alleviates instability during adversarial learning. Extensive empirical evidence shows that our proposal outperforms related approaches in image classification error rates on standard domain adaptation benchmarks.