 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Raise a Robot -- A Case for Neuro-Symbolic AI in Constrained Task Planning for Humanoid Assistive Robots
Dec 27, 2023



Humanoid robots will be able to assist humans in their daily life, in particular due to their versatile action capabilities. However, while these robots need a certain degree of autonomy to learn and explore, they also should respect various constraints, for access control and beyond. We explore the novel field of incorporating privacy, security, and access control constraints with robot task planning approaches. We report preliminary results on the classical symbolic approach, deep-learned neural networks, and modern ideas using large language models as knowledge base. From analyzing their trade-offs, we conclude that a hybrid approach is necessary, and thereby present a new use case for the emerging field of neuro-symbolic artificial intelligence.
Incremental Learning of Full-Pose Via-Point Movement Primitives on Riemannian Manifolds
Dec 13, 2023



Movement primitives (MPs) are compact representations of robot skills that can be learned from demonstrations and combined into complex behaviors. However, merely equipping robots with a fixed set of innate MPs is insufficient to deploy them in dynamic and unpredictable environments. Instead, the full potential of MPs remains to be attained via adaptable, large-scale MP libraries. In this paper, we propose a set of seven fundamental operations to incrementally learn, improve, and re-organize MP libraries. To showcase their applicability, we provide explicit formulations of the spatial operations for libraries composed of Via-Point Movement Primitives (VMPs). By building on Riemannian manifold theory, our approach enables the incremental learning of all parameters of position and orientation VMPs within a library. Moreover, our approach stores a fixed number of parameters, thus complying with the essential principles of incremental learning. We evaluate our approach to incrementally learn a VMP library from motion capture data provided sequentially.
Transfer Learning in Robotics: An Upcoming Breakthrough? A Review of Promises and Challenges
Nov 29, 2023Transfer learning is a conceptually-enticing paradigm in pursuit of truly intelligent embodied agents. The core concept -- reusing prior knowledge to learn in and from novel situations -- is successfully leveraged by humans to handle novel situations. In recent years, transfer learning has received renewed interest from the community from different perspectives, including imitation learning, domain adaptation, and transfer of experience from simulation to the real world, among others. In this paper, we unify the concept of transfer learning in robotics and provide the first taxonomy of its kind considering the key concepts of robot, task, and environment. Through a review of the promises and challenges in the field, we identify the need of transferring at different abstraction levels, the need of quantifying the transfer gap and the quality of transfer, as well as the dangers of negative transfer. Via this position paper, we hope to channel the effort of the community towards the most significant roadblocks to realize the full potential of transfer learning in robotics.
Reinforcement Learning for Safety Testing: Lessons from A Mobile Robot Case Study
Nov 06, 2023Safety-critical robot systems need thorough testing to expose design flaws and software bugs which could endanger humans. Testing in simulation is becoming increasingly popular, as it can be applied early in the development process and does not endanger any real-world operators. However, not all safety-critical flaws become immediately observable in simulation. Some may only become observable under certain critical conditions. If these conditions are not covered, safety flaws may remain undetected. Creating critical tests is therefore crucial. In recent years, there has been a trend towards using Reinforcement Learning (RL) for this purpose. Guided by domain-specific reward functions, RL algorithms are used to learn critical test strategies. This paper presents a case study in which the collision avoidance behavior of a mobile robot is subjected to RL-based testing. The study confirms prior research which shows that RL can be an effective testing tool. However, the study also highlights certain challenges associated with RL-based testing, namely (i) a possible lack of diversity in test conditions and (ii) the phenomenon of reward hacking where the RL agent behaves in undesired ways due to a misalignment of reward and test specification. The challenges are illustrated with data and examples from the experiments, and possible mitigation strategies are discussed.
Unraveling the Single Tangent Space Fallacy: An Analysis and Clarification for Applying Riemannian Geometry in Robot Learning
Oct 11, 2023In the realm of robotics, numerous downstream robotics tasks leverage machine learning methods for processing, modeling, or synthesizing data. Often, this data comprises variables that inherently carry geometric constraints, such as the unit-norm condition of quaternions representing rigid-body orientations or the positive definiteness of stiffness and manipulability ellipsoids. Handling such geometric constraints effectively requires the incorporation of tools from differential geometry into the formulation of machine learning methods. In this context, Riemannian manifolds emerge as a powerful mathematical framework to handle such geometric constraints. Nevertheless, their recent adoption in robot learning has been largely characterized by a mathematically-flawed simplification, hereinafter referred to as the ``single tangent space fallacy". This approach involves merely projecting the data of interest onto a single tangent (Euclidean) space, over which an off-the-shelf learning algorithm is applied. This paper provides a theoretical elucidation of various misconceptions surrounding this approach and offers experimental evidence of its shortcomings. Finally, it presents valuable insights to promote best practices when employing Riemannian geometry within robot learning applications.
Incremental Learning of Humanoid Robot Behavior from Natural Interaction and Large Language Models
Sep 08, 2023



Natural-language dialog is key for intuitive human-robot interaction. It can be used not only to express humans' intents, but also to communicate instructions for improvement if a robot does not understand a command correctly. Of great importance is to endow robots with the ability to learn from such interaction experience in an incremental way to allow them to improve their behaviors or avoid mistakes in the future. In this paper, we propose a system to achieve incremental learning of complex behavior from natural interaction, and demonstrate its implementation on a humanoid robot. Building on recent advances, we present a system that deploys Large Language Models (LLMs) for high-level orchestration of the robot's behavior, based on the idea of enabling the LLM to generate Python statements in an interactive console to invoke both robot perception and action. The interaction loop is closed by feeding back human instructions, environment observations, and execution results to the LLM, thus informing the generation of the next statement. Specifically, we introduce incremental prompt learning, which enables the system to interactively learn from its mistakes. For that purpose, the LLM can call another LLM responsible for code-level improvements of the current interaction based on human feedback. The improved interaction is then saved in the robot's memory, and thus retrieved on similar requests. We integrate the system in the robot cognitive architecture of the humanoid robot ARMAR-6 and evaluate our methods both quantitatively (in simulation) and qualitatively (in simulation and real-world) by demonstrating generalized incrementally-learned knowledge.
Uncertainty-aware Risk Assessment of Robotic Systems via Importance Sampling
Aug 27, 2023



In this paper, we introduce a probabilistic approach to risk assessment of robot systems by focusing on the impact of uncertainties. While various approaches to identifying systematic hazards (e.g., bugs, design flaws, etc.) can be found in current literature, little attention has been devoted to evaluating risks in robot systems in a probabilistic manner. Existing methods rely on discrete notions for dangerous events and assume that the consequences of these can be described by simple logical operations. In this work, we consider measurement uncertainties as one main contributor to the evolvement of risks. Specifically, we study the impact of temporal and spatial uncertainties on the occurrence probability of dangerous failures, thereby deriving an approach for an uncertainty-aware risk assessment. Secondly, we introduce a method to improve the statistical significance of our results: While the rare occurrence of hazardous events makes it challenging to draw conclusions with reliable accuracy, we show that importance sampling -- a technique that successively generates samples in regions with sparse probability densities -- allows for overcoming this issue. We demonstrate the validity of our novel uncertainty-aware risk assessment method in three simulation scenarios from the domain of human-robot collaboration. Finally, we show how the results can be used to evaluate arbitrary safety limits of robot systems.
On the Design of Region-Avoiding Metrics for Collision-Safe Motion Generation on Riemannian Manifolds
Jul 28, 2023The generation of energy-efficient and dynamic-aware robot motions that satisfy constraints such as joint limits, self-collisions, and collisions with the environment remains a challenge. In this context, Riemannian geometry offers promising solutions by identifying robot motions with geodesics on the so-called configuration space manifold. While this manifold naturally considers the intrinsic robot dynamics, constraints such as joint limits, self-collisions, and collisions with the environment remain overlooked. In this paper, we propose a modification of the Riemannian metric of the configuration space manifold allowing for the generation of robot motions as geodesics that efficiently avoid given regions. We introduce a class of Riemannian metrics based on barrier functions that guarantee strict region avoidance by systematically generating accelerations away from no-go regions in joint and task space. We evaluate the proposed Riemannian metric to generate energy-efficient, dynamic-aware, and collision-free motions of a humanoid robot as geodesics and sequences thereof.
Interactive and Incremental Learning of Spatial Object Relations from Human Demonstrations
May 16, 2023Humans use semantic concepts such as spatial relations between objects to describe scenes and communicate tasks such as "Put the tea to the right of the cup" or "Move the plate between the fork and the spoon." Just as children, assistive robots must be able to learn the sub-symbolic meaning of such concepts from human demonstrations and instructions. We address the problem of incrementally learning geometric models of spatial relations from few demonstrations collected online during interaction with a human. Such models enable a robot to manipulate objects in order to fulfill desired spatial relations specified by verbal instructions. At the start, we assume the robot has no geometric model of spatial relations. Given a task as above, the robot requests the user to demonstrate the task once in order to create a model from a single demonstration, leveraging cylindrical probability distribution as generative representation of spatial relations. We show how this model can be updated incrementally with each new demonstration without access to past examples in a sample-efficient way using incremental maximum likelihood estimation, and demonstrate the approach on a real humanoid robot.
Virtual Reality via Object Poses and Active Learning: Realizing Telepresence Robots with Aerial Manipulation Capabilities
Oct 18, 2022

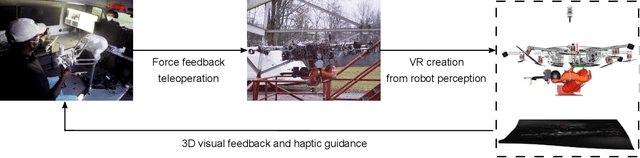
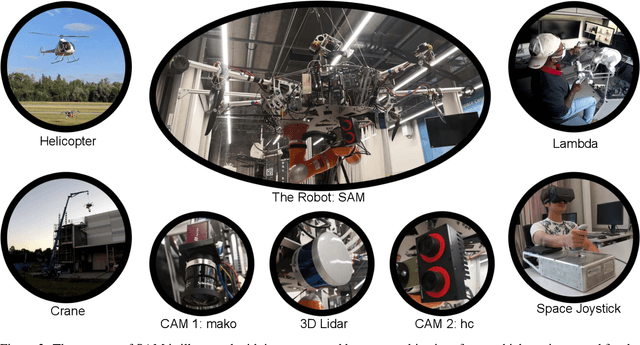
This article presents a novel telepresence system for advancing aerial manipulation in dynamic and unstructured environments. The proposed system not only features a haptic device, but also a virtual reality (VR) interface that provides real-time 3D displays of the robot's workspace as well as a haptic guidance to its remotely located operator. To realize this, multiple sensors namely a LiDAR, cameras and IMUs are utilized. For processing of the acquired sensory data, pose estimation pipelines are devised for industrial objects of both known and unknown geometries. We further propose an active learning pipeline in order to increase the sample efficiency of a pipeline component that relies on Deep Neural Networks (DNNs) based object detection. All these algorithms jointly address various challenges encountered during the execution of perception tasks in industrial scenarios. In the experiments, exhaustive ablation studies are provided to validate the proposed pipelines. Methodologically, these results commonly suggest how an awareness of the algorithms' own failures and uncertainty ("introspection") can be used tackle the encountered problems. Moreover, outdoor experiments are conducted to evaluate the effectiveness of the overall system in enhancing aerial manipulation capabilities. In particular, with flight campaigns over days and nights, from spring to winter, and with different users and locations, we demonstrate over 70 robust executions of pick-and-place, force application and peg-in-hole tasks with the DLR cable-Suspended Aerial Manipulator (SAM). As a result, we show the viability of the proposed system in future industrial applications.