 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccuracy Does Not Guarantee Human-Likeness in Monocular Depth Estimators
Dec 09, 2025Monocular depth estimation is a fundamental capability for real-world applications such as autonomous driving and robotics. Although deep neural networks (DNNs) have achieved superhuman accuracy on physical-based benchmarks, a key challenge remains: aligning model representations with human perception, a promising strategy for enhancing model robustness and interpretability. Research in object recognition has revealed a complex trade-off between model accuracy and human-like behavior, raising a question whether a similar divergence exist in depth estimation, particularly for natural outdoor scenes where benchmarks rely on sensor-based ground truth rather than human perceptual estimates. In this study, we systematically investigated the relationship between model accuracy and human similarity across 69 monocular depth estimators using the KITTI dataset. To dissect the structure of error patterns on a factor-by-factor basis, we applied affine fitting to decompose prediction errors into interpretable components. Intriguingly, our results reveal while humans and DNNs share certain estimation biases (positive error correlations), we observed distinct trade-off relationships between model accuracy and human similarity. This finding indicates that improving accuracy does not necessarily lead to more human-like behavior, underscoring the necessity of developing multifaceted, human-centric evaluations beyond traditional accuracy.
Attention-based Contextual Multi-View Graph Convolutional Networks for Short-term Population Prediction
Mar 01, 2022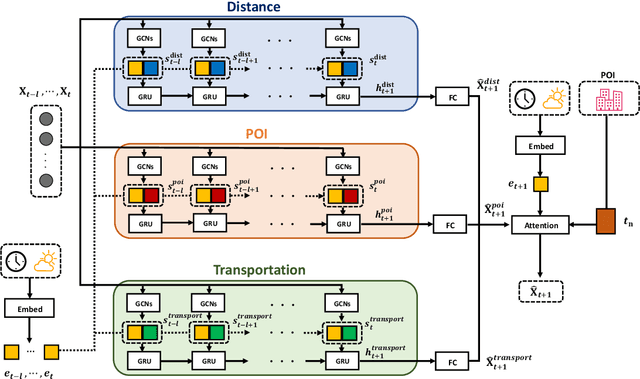
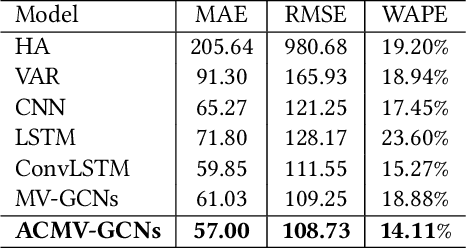
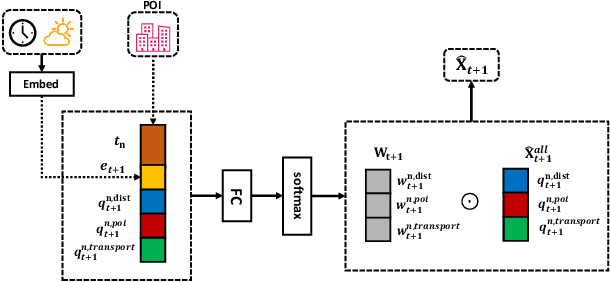
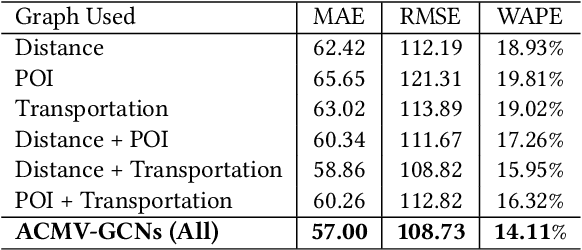
Short-term future population prediction is a crucial problem in urban computing. Accurate future population prediction can provide rich insights for urban planners or developers. However, predicting the future population is a challenging task due to its complex spatiotemporal dependencies. Many existing works have attempted to capture spatial correlations by partitioning a city into grids and using Convolutional Neural Networks (CNN). However, CNN merely captures spatial correlations by using a rectangle filter; it ignores urban environmental information such as distribution of railroads and location of POI. Moreover, the importance of those kinds of information for population prediction differs in each region and is affected by contextual situations such as weather conditions and day of the week. To tackle this problem, we propose a novel deep learning model called Attention-based Contextual Multi-View Graph Convolutional Networks (ACMV-GCNs). We first construct multiple graphs based on urban environmental information, and then ACMV-GCNs captures spatial correlations from various views with graph convolutional networks. Further, we add an attention module to consider the contextual situations when leveraging urban environmental information for future population prediction. Using statistics population count data collected through mobile phones, we demonstrate that our proposed model outperforms baseline methods. In addition, by visualizing weights calculated by an attention module, we show that our model learns an efficient way to utilize urban environment information without any prior knowledge.