 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning 6DoF Grasping Using Reward-Consistent Demonstration
Mar 23, 2021
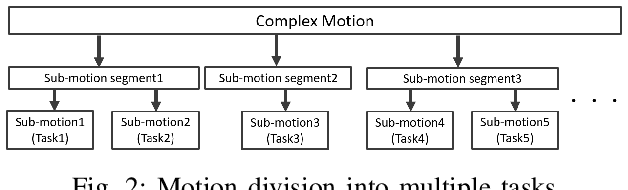
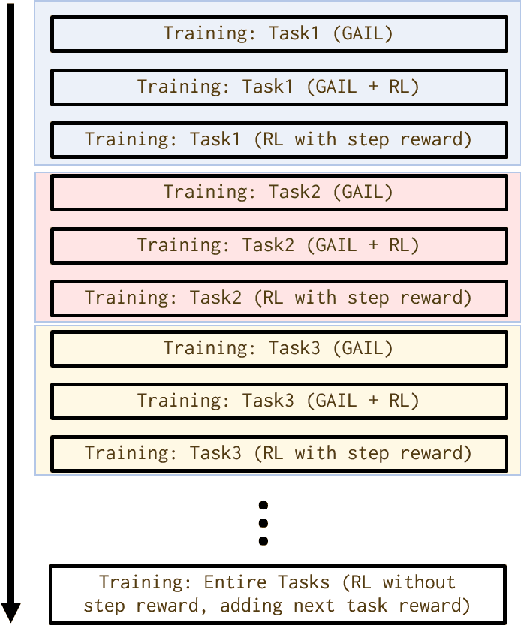

As the number of the robot's degrees of freedom increases, the implementation of robot motion becomes more complex and difficult. In this study, we focus on learning 6DOF-grasping motion and consider dividing the grasping motion into multiple tasks. We propose to combine imitation and reinforcement learning in order to facilitate a more efficient learning of the desired motion. In order to collect demonstration data as teacher data for the imitation learning, we created a virtual reality (VR) interface that allows humans to operate the robot intuitively. Moreover, by dividing the motion into simpler tasks, we simplify the design of reward functions for reinforcement learning and show in our experiments a reduction in the steps required to learn the grasping motion.
Relative Drone-Ground Vehicle Localization using LiDAR and Fisheye Cameras through Direct and Indirect Observations
Nov 17, 2020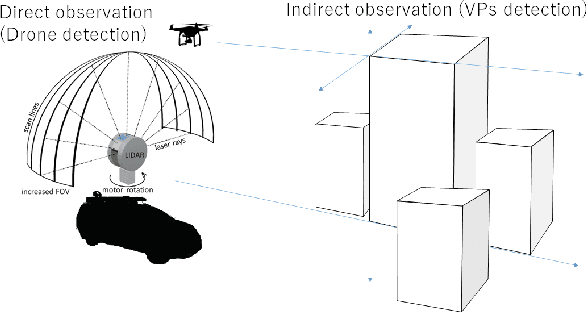
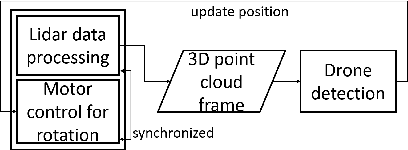
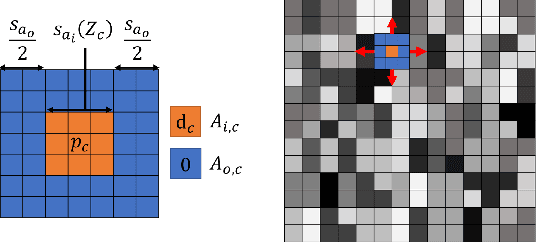
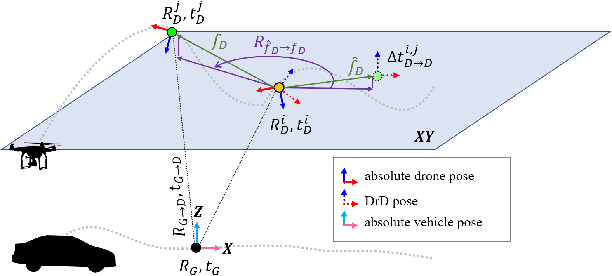
Estimating the pose of an unmanned aerial vehicle (UAV) or drone is a challenging task. It is useful for many applications such as navigation, surveillance, tracking objects on the ground, and 3D reconstruction. In this work, we present a LiDAR-camera-based relative pose estimation method between a drone and a ground vehicle, using a LiDAR sensor and a fisheye camera on the vehicle's roof and another fisheye camera mounted under the drone. The LiDAR sensor directly observes the drone and measures its position, and the two cameras estimate the relative orientation using indirect observation of the surrounding objects. We propose a dynamically adaptive kernel-based method for drone detection and tracking using the LiDAR. We detect vanishing points in both cameras and find their correspondences to estimate the relative orientation. Additionally, we propose a rotation correction technique by relying on the observed motion of the drone through the LiDAR. In our experiments, we were able to achieve very fast initial detection and real-time tracking of the drone. Our method is fully automatic.
Discontinuous and Smooth Depth Completion with Binary Anisotropic Diffusion Tensor
Jun 25, 2020


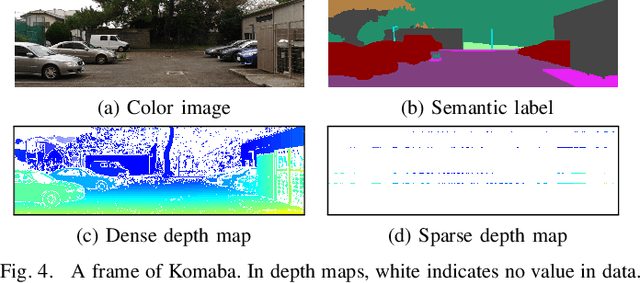
We propose an unsupervised real-time dense depth completion from a sparse depth map guided by a single image. Our method generates a smooth depth map while preserving discontinuity between different objects. Our key idea is a Binary Anisotropic Diffusion Tensor (B-ADT) which can completely eliminate smoothness constraint at intended positions and directions by applying it to variational regularization. We also propose an Image-guided Nearest Neighbor Search (IGNNS) to derive a piecewise constant depth map which is used for B-ADT derivation and in the data term of the variational energy. Our experiments show that our method can outperform previous unsupervised and semi-supervised depth completion methods in terms of accuracy. Moreover, since our resulting depth map preserves the discontinuity between objects, the result can be converted to a visually plausible point cloud. This is remarkable since previous methods generate unnatural surface-like artifacts between discontinuous objects.
A Hand Motion-guided Articulation and Segmentation Estimation
May 07, 2020
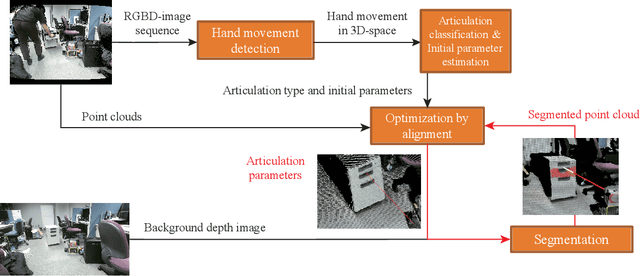


In this paper, we present a method for simultaneous articulation model estimation and segmentation of an articulated object in RGB-D images using human hand motion. Our method uses the hand motion in the processes of the initial articulation model estimation, ICP-based model parameter optimization, and region selection of the target object. The hand motion gives an initial guess of the articulation model: prismatic or revolute joint. The method estimates the joint parameters by aligning the RGB-D images with the constraint of the hand motion. Finally, the target regions are selected from the cluster regions which move symmetrically along with the articulation model. Our experimental results show the robustness of the proposed method for the various objects.
Real-Time Variational Fisheye Stereo without Rectification and Undistortion
Sep 17, 2019
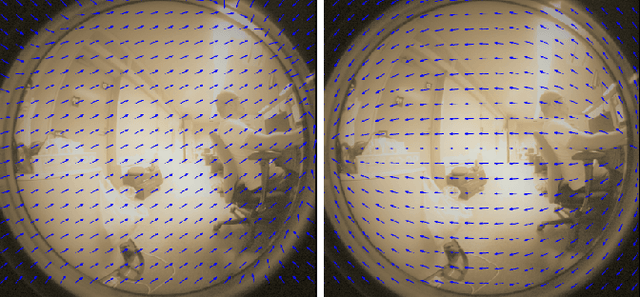
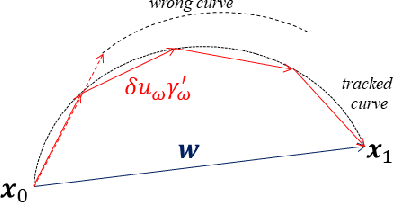
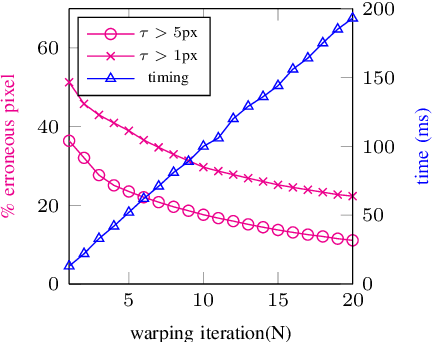
Dense 3D maps from wide-angle cameras is beneficial to robotics applications such as navigation and autonomous driving. In this work, we propose a real-time dense 3D mapping method for fisheye cameras without explicit rectification and undistortion. We extend the conventional variational stereo method by constraining the correspondence search along the epipolar curve using a trajectory field induced by camera motion. We also propose a fast way of generating the trajectory field without increasing the processing time compared to conventional rectified methods. With our implementation, we were able to achieve real-time processing using modern GPUs. Our results show the advantages of our non-rectified dense mapping approach compared to rectified variational methods and non-rectified discrete stereo matching methods.
Occlusion Handling using Semantic Segmentation and Visibility-Based Rendering for Mixed Reality
Jul 30, 2017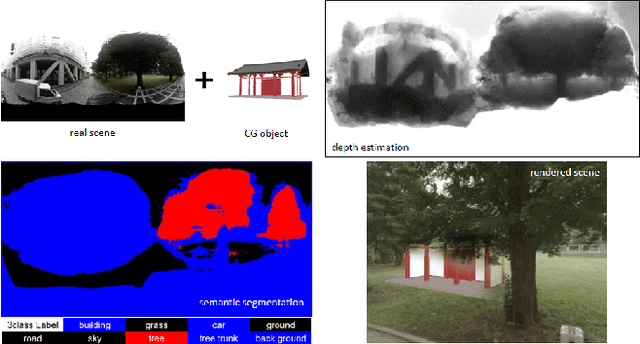
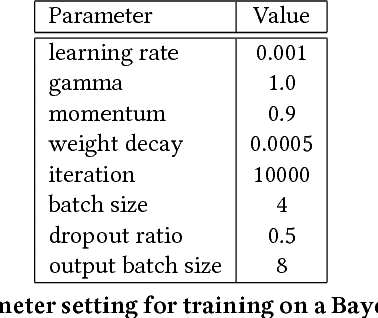

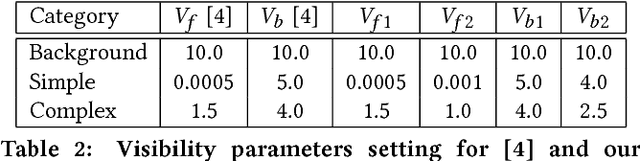
Real-time occlusion handling is a major problem in outdoor mixed reality system because it requires great computational cost mainly due to the complexity of the scene. Using only segmentation, it is difficult to accurately render a virtual object occluded by complex objects such as trees, bushes etc. In this paper, we propose a novel occlusion handling method for real-time, outdoor, and omni-directional mixed reality system using only the information from a monocular image sequence. We first present a semantic segmentation scheme for predicting the amount of visibility for different type of objects in the scene. We also simultaneously calculate a foreground probability map using depth estimation derived from optical flow. Finally, we combine the segmentation result and the probability map to render the computer generated object and the real scene using a visibility-based rendering method. Our results show great improvement in handling occlusions compared to existing blending based methods.