 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiCITRIS: Causal Representation Learning for Instantaneous Temporal Effects
Jun 13, 2022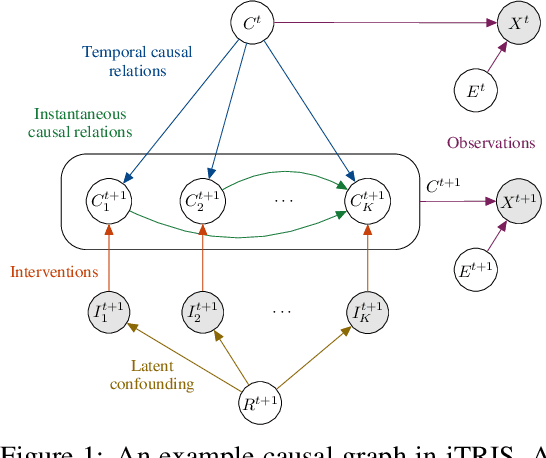

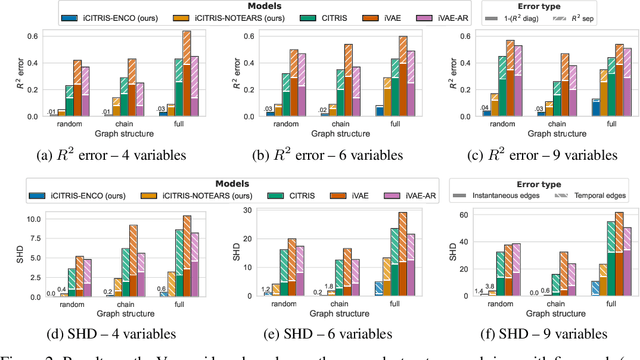

Causal representation learning is the task of identifying the underlying causal variables and their relations from high-dimensional observations, such as images. Recent work has shown that one can reconstruct the causal variables from temporal sequences of observations under the assumption that there are no instantaneous causal relations between them. In practical applications, however, our measurement or frame rate might be slower than many of the causal effects. This effectively creates "instantaneous" effects and invalidates previous identifiability results. To address this issue, we propose iCITRIS, a causal representation learning method that can handle instantaneous effects in temporal sequences when given perfect interventions with known intervention targets. iCITRIS identifies the causal factors from temporal observations, while simultaneously using a differentiable causal discovery method to learn their causal graph. In experiments on three video datasets, iCITRIS accurately identifies the causal factors and their causal graph.
Equivariant Mesh Attention Networks
May 21, 2022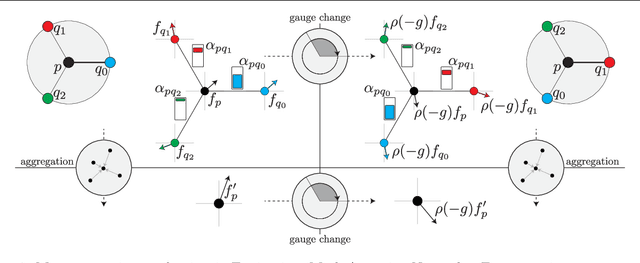

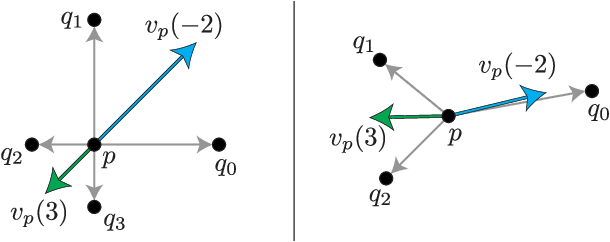

Equivariance to symmetries has proven to be a powerful inductive bias in deep learning research. Recent works on mesh processing have concentrated on various kinds of natural symmetries, including translations, rotations, scaling, node permutations, and gauge transformations. To date, no existing architecture is equivariant to all of these transformations. Moreover, previous implementations have not always applied these symmetry transformations to the test dataset. This inhibits the ability to determine whether the model attains the claimed equivariance properties. In this paper, we present an attention-based architecture for mesh data that is provably equivariant to all transformations mentioned above. We carry out experiments on the FAUST and TOSCA datasets, and apply the mentioned symmetries to the test set only. Our results confirm that our proposed architecture is equivariant, and therefore robust, to these local/global transformations.
Weakly supervised causal representation learning
Mar 30, 2022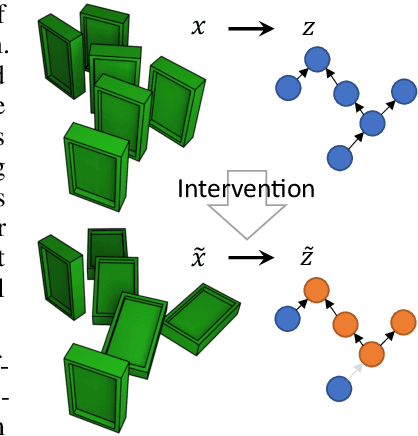

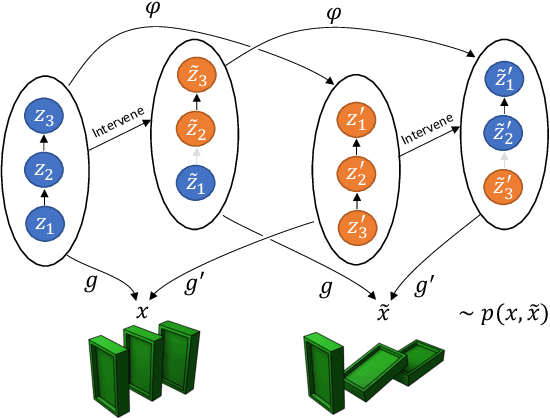
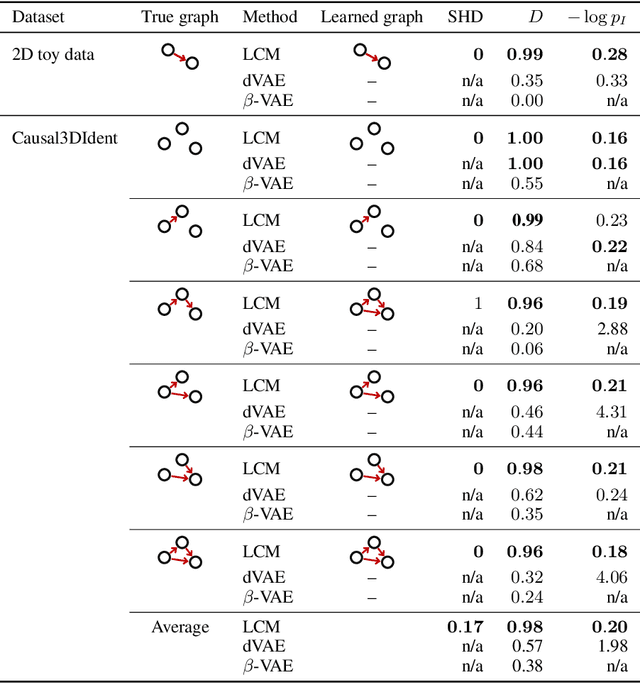
Learning high-level causal representations together with a causal model from unstructured low-level data such as pixels is impossible from observational data alone. We prove under mild assumptions that this representation is identifiable in a weakly supervised setting. This requires a dataset with paired samples before and after random, unknown interventions, but no further labels. Finally, we show that we can infer the representation and causal graph reliably in a simple synthetic domain using a variational autoencoder with a structural causal model as prior.
CITRIS: Causal Identifiability from Temporal Intervened Sequences
Feb 16, 2022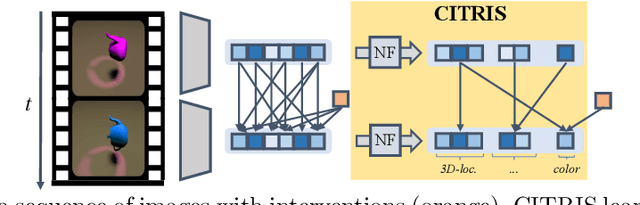
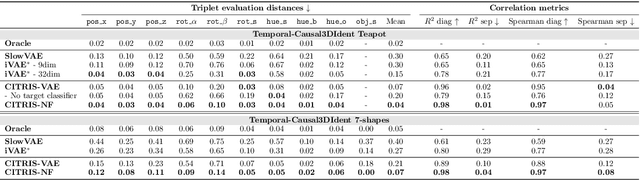
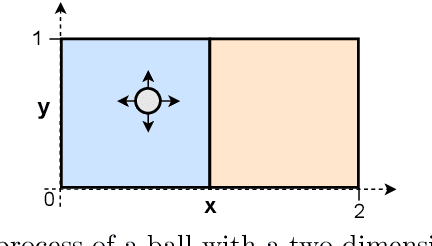

Understanding the latent causal factors of a dynamical system from visual observations is a crucial step towards agents reasoning in complex environments. In this paper, we propose CITRIS, a variational autoencoder framework that learns causal representations from temporal sequences of images in which underlying causal factors have possibly been intervened upon. In contrast to the recent literature, CITRIS exploits temporality and observing intervention targets to identify scalar and multidimensional causal factors, such as 3D rotation angles. Furthermore, by introducing a normalizing flow, CITRIS can be easily extended to leverage and disentangle representations obtained by already pretrained autoencoders. Extending previous results on scalar causal factors, we prove identifiability in a more general setting, in which only some components of a causal factor are affected by interventions. In experiments on 3D rendered image sequences, CITRIS outperforms previous methods on recovering the underlying causal variables. Moreover, using pretrained autoencoders, CITRIS can even generalize to unseen instantiations of causal factors, opening future research areas in sim-to-real generalization for causal representation learning.
Implicit Neural Video Compression
Dec 21, 2021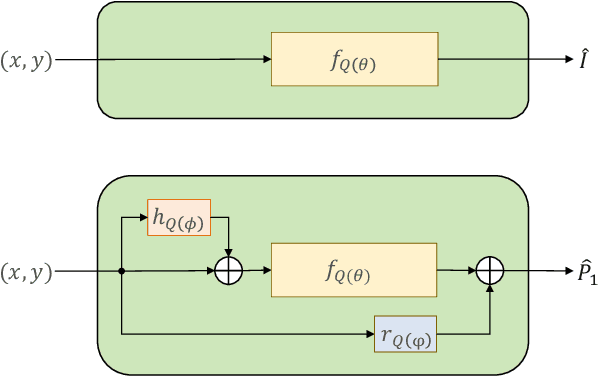
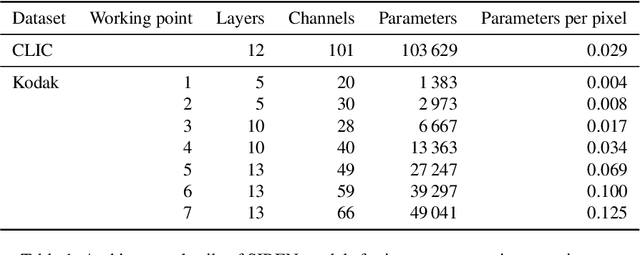

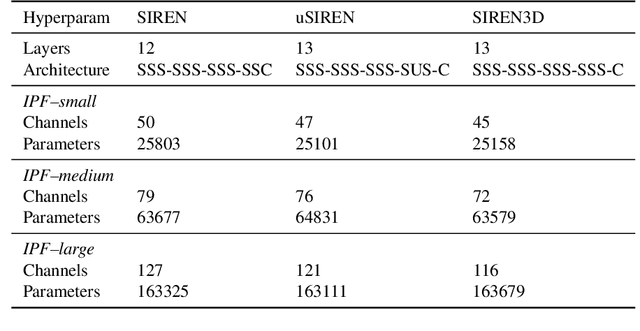
We propose a method to compress full-resolution video sequences with implicit neural representations. Each frame is represented as a neural network that maps coordinate positions to pixel values. We use a separate implicit network to modulate the coordinate inputs, which enables efficient motion compensation between frames. Together with a small residual network, this allows us to efficiently compress P-frames relative to the previous frame. We further lower the bitrate by storing the network weights with learned integer quantization. Our method, which we call implicit pixel flow (IPF), offers several simplifications over established neural video codecs: it does not require the receiver to have access to a pretrained neural network, does not use expensive interpolation-based warping operations, and does not require a separate training dataset. We demonstrate the feasibility of neural implicit compression on image and video data.
Efficient Neural Causal Discovery without Acyclicity Constraints
Jul 22, 2021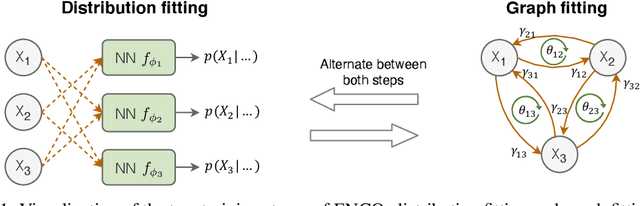
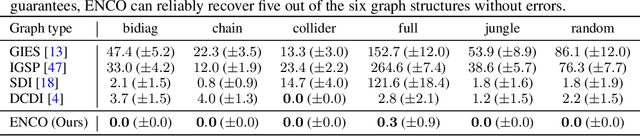
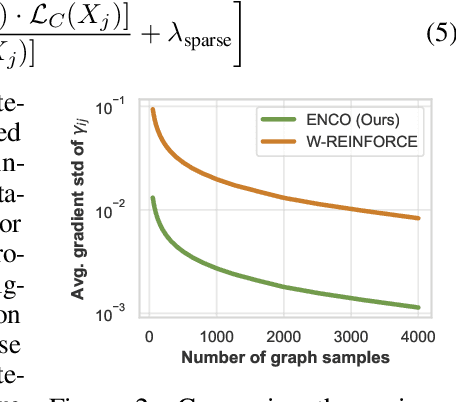

Learning the structure of a causal graphical model using both observational and interventional data is a fundamental problem in many scientific fields. A promising direction is continuous optimization for score-based methods, which efficiently learn the causal graph in a data-driven manner. However, to date, those methods require constrained optimization to enforce acyclicity or lack convergence guarantees. In this paper, we present ENCO, an efficient structure learning method for directed, acyclic causal graphs leveraging observational and interventional data. ENCO formulates the graph search as an optimization of independent edge likelihoods, with the edge orientation being modeled as a separate parameter. Consequently, we can provide convergence guarantees of ENCO under mild conditions without constraining the score function with respect to acyclicity. In experiments, we show that ENCO can efficiently recover graphs with hundreds of nodes, an order of magnitude larger than what was previously possible, while handling deterministic variables and latent confounders.
Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges
May 02, 2021
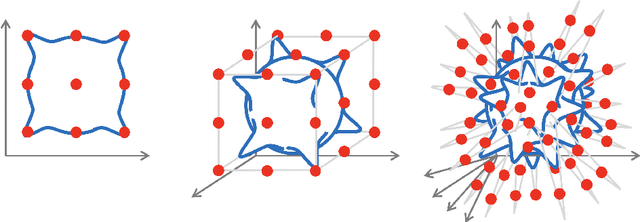
The last decade has witnessed an experimental revolution in data science and machine learning, epitomised by deep learning methods. Indeed, many high-dimensional learning tasks previously thought to be beyond reach -- such as computer vision, playing Go, or protein folding -- are in fact feasible with appropriate computational scale. Remarkably, the essence of deep learning is built from two simple algorithmic principles: first, the notion of representation or feature learning, whereby adapted, often hierarchical, features capture the appropriate notion of regularity for each task, and second, learning by local gradient-descent type methods, typically implemented as backpropagation. While learning generic functions in high dimensions is a cursed estimation problem, most tasks of interest are not generic, and come with essential pre-defined regularities arising from the underlying low-dimensionality and structure of the physical world. This text is concerned with exposing these regularities through unified geometric principles that can be applied throughout a wide spectrum of applications. Such a 'geometric unification' endeavour, in the spirit of Felix Klein's Erlangen Program, serves a dual purpose: on one hand, it provides a common mathematical framework to study the most successful neural network architectures, such as CNNs, RNNs, GNNs, and Transformers. On the other hand, it gives a constructive procedure to incorporate prior physical knowledge into neural architectures and provide principled way to build future architectures yet to be invented.
Parallelized Rate-Distortion Optimized Quantization Using Deep Learning
Dec 11, 2020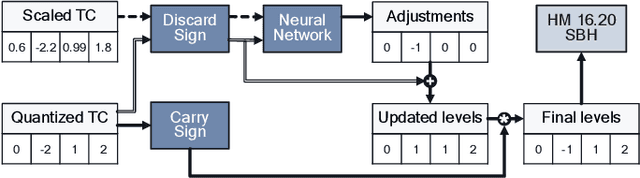
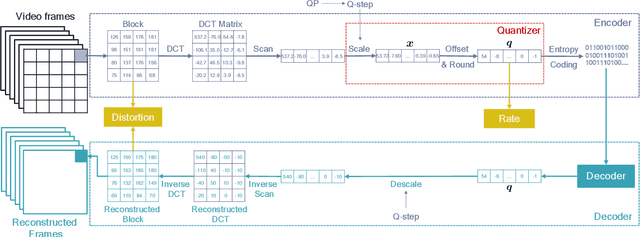
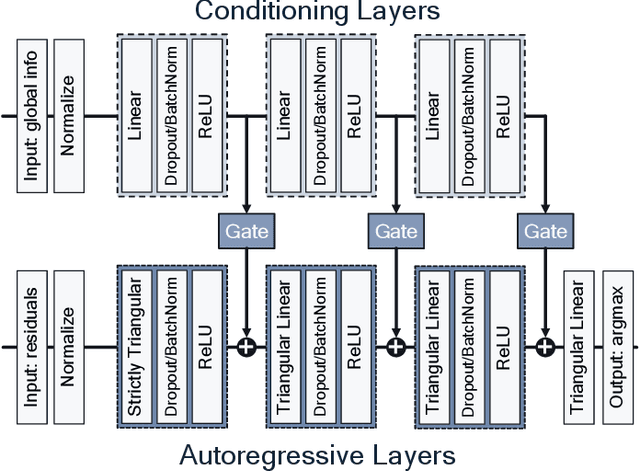
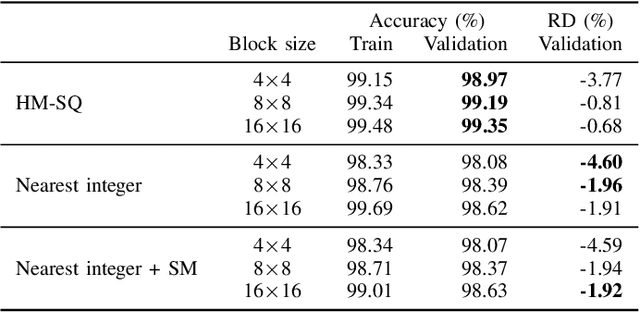
Rate-Distortion Optimized Quantization (RDOQ) has played an important role in the coding performance of recent video compression standards such as H.264/AVC, H.265/HEVC, VP9 and AV1. This scheme yields significant reductions in bit-rate at the expense of relatively small increases in distortion. Typically, RDOQ algorithms are prohibitively expensive to implement on real-time hardware encoders due to their sequential nature and their need to frequently obtain entropy coding costs. This work addresses this limitation using a neural network-based approach, which learns to trade-off rate and distortion during offline supervised training. As these networks are based solely on standard arithmetic operations that can be executed on existing neural network hardware, no additional area-on-chip needs to be reserved for dedicated RDOQ circuitry. We train two classes of neural networks, a fully-convolutional network and an auto-regressive network, and evaluate each as a post-quantization step designed to refine cheap quantization schemes such as scalar quantization (SQ). Both network architectures are designed to have a low computational overhead. After training they are integrated into the HM 16.20 implementation of HEVC, and their video coding performance is evaluated on a subset of the H.266/VVC SDR common test sequences. Comparisons are made to RDOQ and SQ implementations in HM 16.20. Our method achieves 1.64% BD-rate savings on luminosity compared to the HM SQ anchor, and on average reaches 45% of the performance of the iterative HM RDOQ algorithm.
Natural Graph Networks
Jul 16, 2020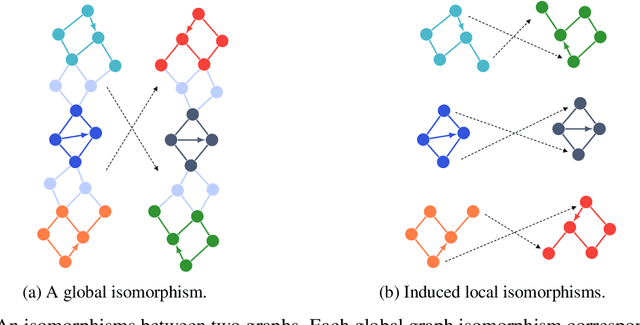
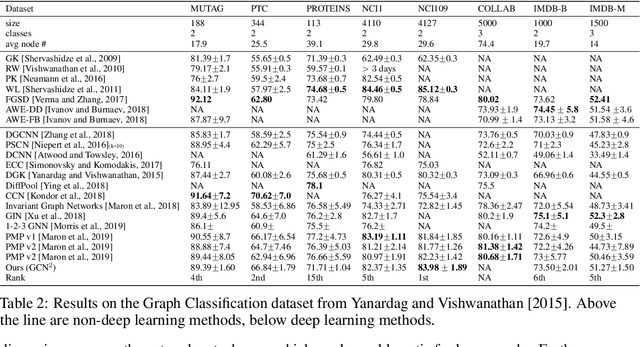
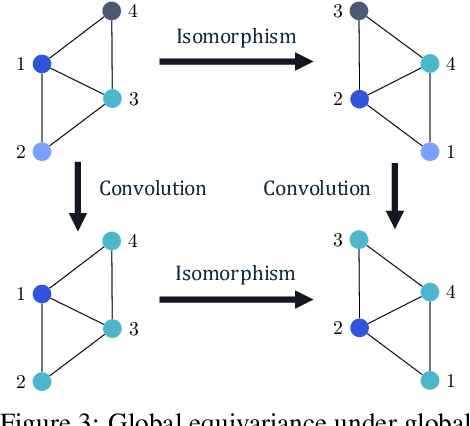
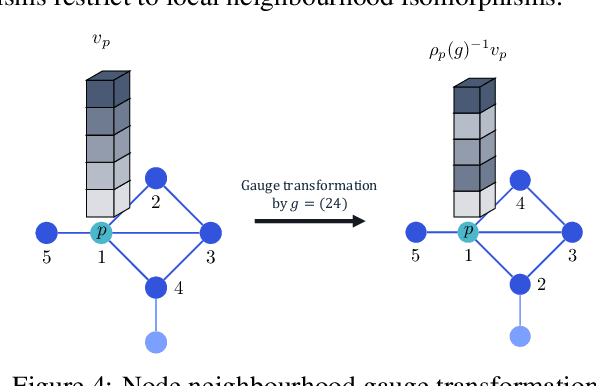
Conventional neural message passing algorithms are invariant under permutation of the messages and hence forget how the information flows through the network. Studying the local symmetries of graphs, we propose a more general algorithm that uses different kernels on different edges, making the network equivariant to local and global graph isomorphisms and hence more expressive. Using elementary category theory, we formalize many distinct equivariant neural networks as natural networks, and show that their kernels are 'just' a natural transformation between two functors. We give one practical instantiation of a natural network on graphs which uses a equivariant message network parameterization, yielding good performance on several benchmarks.
Adversarial Distortion for Learned Video Compression
Apr 22, 2020

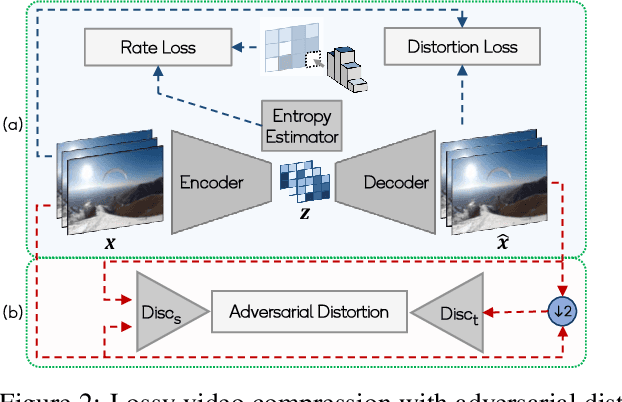
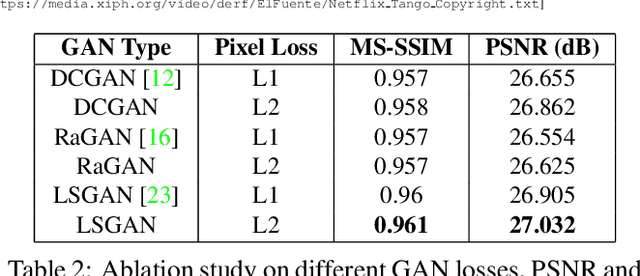
In this paper, we present a novel adversarial lossy video compression model. At extremely low bit-rates, standard video coding schemes suffer from unpleasant reconstruction artifacts such as blocking, ringing etc. Existing learned neural approaches to video compression have achieved reasonable success on reducing the bit-rate for efficient transmission and reduce the impact of artifacts to an extent. However, they still tend to produce blurred results under extreme compression. In this paper, we present a deep adversarial learned video compression model that minimizes an auxiliary adversarial distortion objective. We find this adversarial objective to correlate better with human perceptual quality judgement relative to traditional quality metrics such as MS-SSIM and PSNR. Our experiments using a state-of-the-art learned video compression system demonstrate a reduction of perceptual artifacts and reconstruction of detail lost especially under extremely high compression.