 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMAT: Medial Axis Transform for Natural Images
Aug 02, 2017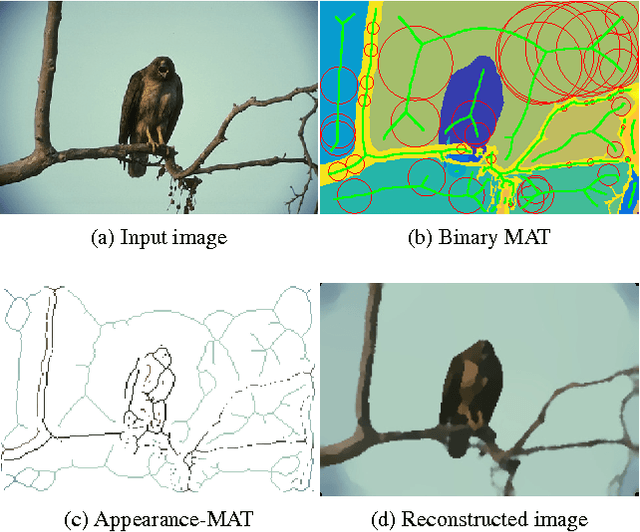
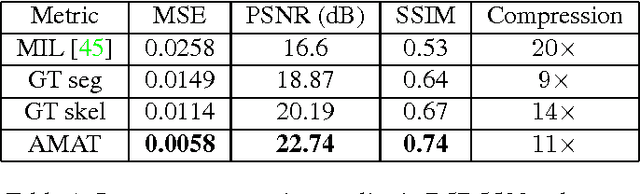

We introduce Appearance-MAT (AMAT), a generalization of the medial axis transform for natural images, that is framed as a weighted geometric set cover problem. We make the following contributions: i) we extend previous medial point detection methods for color images, by associating each medial point with a local scale; ii) inspired by the invertibility property of the binary MAT, we also associate each medial point with a local encoding that allows us to invert the AMAT, reconstructing the input image; iii) we describe a clustering scheme that takes advantage of the additional scale and appearance information to group individual points into medial branches, providing a shape decomposition of the underlying image regions. In our experiments, we show state-of-the-art performance in medial point detection on Berkeley Medial AXes (BMAX500), a new dataset of medial axes based on the BSDS500 database, and good generalization on the SK506 and WH-SYMMAX datasets. We also measure the quality of reconstructed images from BMAX500, obtained by inverting their computed AMAT. Our approach delivers significantly better reconstruction quality with respect to three baselines, using just 10% of the image pixels. Our code and annotations are available at https://github.com/tsogkas/amat .
A Framework for Symmetric Part Detection in Cluttered Scenes
Feb 05, 2015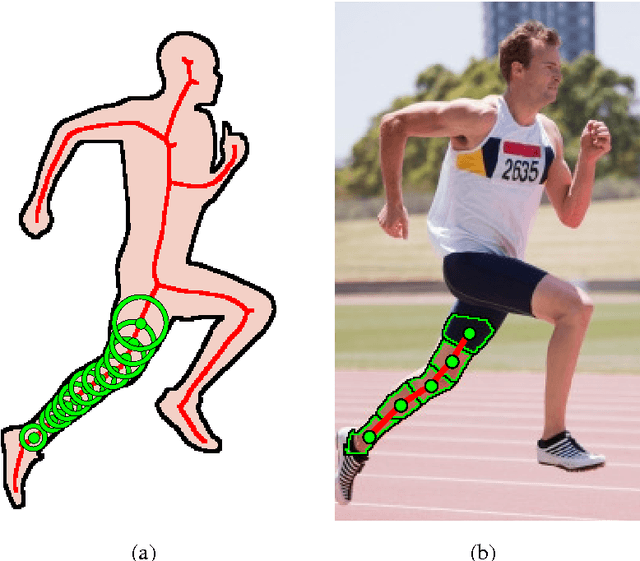

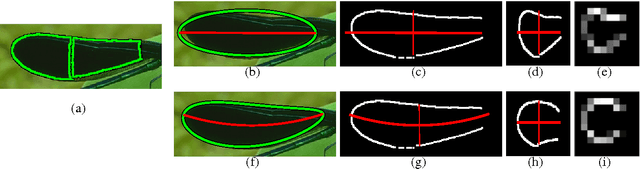
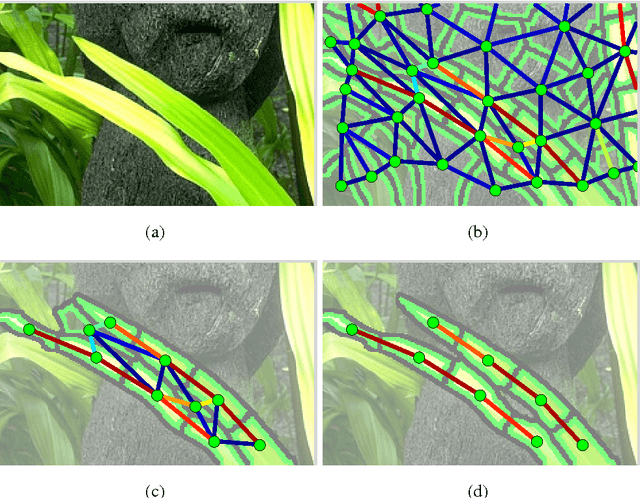
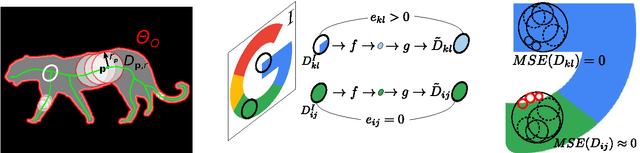
The role of symmetry in computer vision has waxed and waned in importance during the evolution of the field from its earliest days. At first figuring prominently in support of bottom-up indexing, it fell out of favor as shape gave way to appearance and recognition gave way to detection. With a strong prior in the form of a target object, the role of the weaker priors offered by perceptual grouping was greatly diminished. However, as the field returns to the problem of recognition from a large database, the bottom-up recovery of the parts that make up the objects in a cluttered scene is critical for their recognition. The medial axis community has long exploited the ubiquitous regularity of symmetry as a basis for the decomposition of a closed contour into medial parts. However, today's recognition systems are faced with cluttered scenes, and the assumption that a closed contour exists, i.e. that figure-ground segmentation has been solved, renders much of the medial axis community's work inapplicable. In this article, we review a computational framework, previously reported in Lee et al. (2013), Levinshtein et al. (2009, 2013), that bridges the representation power of the medial axis and the need to recover and group an object's parts in a cluttered scene. Our framework is rooted in the idea that a maximally inscribed disc, the building block of a medial axis, can be modeled as a compact superpixel in the image. We evaluate the method on images of cluttered scenes.
Video In Sentences Out
Aug 09, 2014
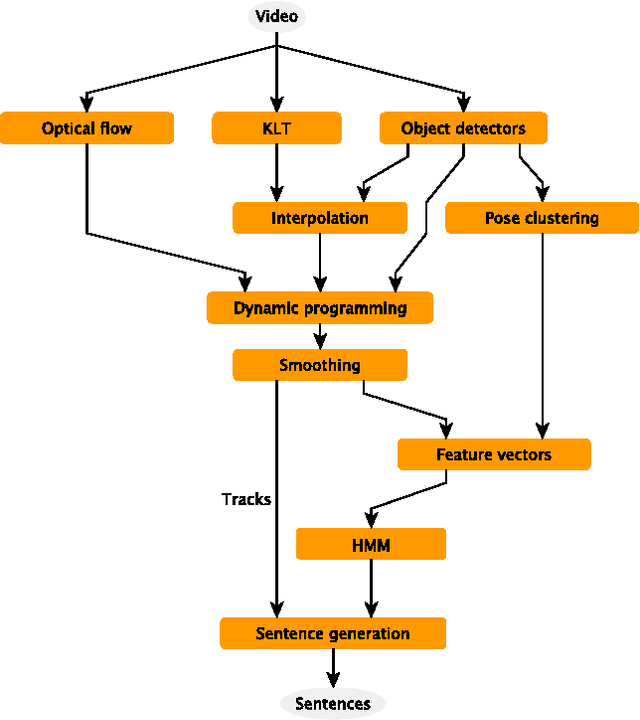


We present a system that produces sentential descriptions of video: who did what to whom, and where and how they did it. Action class is rendered as a verb, participant objects as noun phrases, properties of those objects as adjectival modifiers in those noun phrases, spatial relations between those participants as prepositional phrases, and characteristics of the event as prepositional-phrase adjuncts and adverbial modifiers. Extracting the information needed to render these linguistic entities requires an approach to event recognition that recovers object tracks, the trackto-role assignments, and changing body posture.
Large-Scale Automatic Labeling of Video Events with Verbs Based on Event-Participant Interaction
Apr 16, 2012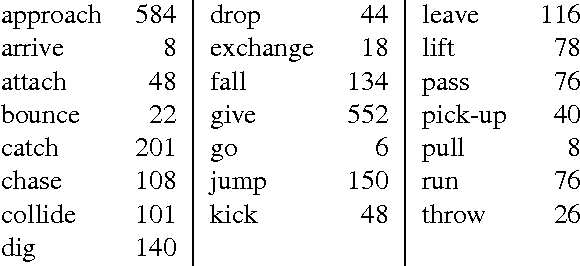



We present an approach to labeling short video clips with English verbs as event descriptions. A key distinguishing aspect of this work is that it labels videos with verbs that describe the spatiotemporal interaction between event participants, humans and objects interacting with each other, abstracting away all object-class information and fine-grained image characteristics, and relying solely on the coarse-grained motion of the event participants. We apply our approach to a large set of 22 distinct verb classes and a corpus of 2,584 videos, yielding two surprising outcomes. First, a classification accuracy of greater than 70% on a 1-out-of-22 labeling task and greater than 85% on a variety of 1-out-of-10 subsets of this labeling task is independent of the choice of which of two different time-series classifiers we employ. Second, we achieve this level of accuracy using a highly impoverished intermediate representation consisting solely of the bounding boxes of one or two event participants as a function of time. This indicates that successful event recognition depends more on the choice of appropriate features that characterize the linguistic invariants of the event classes than on the particular classifier algorithms.