 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligibility of Speech in Noise: Investigating Contribution of Magnitude and Phase Spectra
Jun 15, 2026It is well known that intelligibility of speech reduces in the presence of ambient noise. However, studies show that all sounds are not affected uniformly (or equally) and that vowels are more robust to noise than consonants. In this study, intelligibility of various consonants is assessed and analyzed in stationary white noise and non-stationary babble noise conditions. Specifically, this study investigates the individual contribution of magnitude and phase spectra of a given speech signal on human speech recognition of consonants in noisy conditions. In this regard, three experiments are carried out. In experiment 1, clean signal, signal reconstructed with only magnitude spectrum information (magnitude only signal) and signal reconstructed with only phase spectrum information (phase only signal) are assessed for intelligibility. In experiment 2, noise is added to clean speech. From noisy speech, phase only signal and magnitude only signal are reconstructed and intelligibility tests are performed for all these three signals. In experiment 3, noise is added directly to the magnitude only and phase only signals reconstructed from clean speech and their intelligibility is assessed. Results of these experiments show that magnitude spectrum contributes more to intelligibility in clean condition than phase spectrum, while information from phase spectrum is more robust in noisy conditions. It is also observed that, among consonants, nasals are more susceptible to noise whereas fricatives and approximants were observed to be comparatively more robust.
Single frequency filtering based multi-speaker direction of arrival estimation from stereo recordings
Jun 15, 2026Robust direction-of-arrival (DoA) estimation from noisy and reverberant microphone signals remains challenging. Conventional estimators such as generalized cross-correlation (GCC) and its variants operate in the short-time Fourier transform (STFT) domain, where spectral features primarily reflect vocal-tract characteristics. Recent single frequency filtering (SFF)-based estimators instead use a time-frequency representation that provides high spectral resolution of harmonics along with high temporal resolution of excitation-source events, such as epoch-like impulses. Since excitation-source features have been shown to be more robust to noise and reverberation than spectral features, this work proposes an improved SFF-based DoA estimator that correlates the envelopes of SFF outputs across microphone channels using PHAT-weighted GCC. We further provide a comprehensive evaluation of SFF-based and state-of-the-art GCC-based estimators using publicly available real-room recordings under challenging reverberant, multi-speaker, and noise-corrupted conditions. Experimental results show that the proposed method and an existing SFF-based estimator achieve detection and accuracy performance that is superior or comparable to the best GCC-based estimator across all test cases. We also demonstrate that using speech-dominant bins improves GCC-PHAT robustness, motivating future incorporation of such weighting strategies into SFF-based DoA estimation.
Direction of arrival estimation from distant microphone data using single frequency filtering
Jun 15, 2026In distant microphones, broadband (BB) methods for direction-of-arrival (DoA) estimation are more suitable than narrowband (NB) methods. Due to the aggregation of their optimization function across all frequency bands, BB estimators are robust to spatial aliasing, a known problem in processing distant microphone data. In NB methods, DoA estimation is performed by utilizing \textit{local} information in each frequency band and hence the estimation is affected by spatial aliasing. However, unlike BB methods, NB methods exploit frequency sparsity to estimate the DoAs of \textit{multiple speakers} in a \textit{single time frame}. In this article, a method to improve the robustness of a NB DoA estimator to spatial aliasing is developed. The proposed method is based on cross-correlation of speech-present time-frequency regions obtained by single frequency filtering (SFF) of the microphone signals. The SFF spectrum is chosen because SFF components have regions of high signal-to-noise ratio both in time and frequency and because speech and non-speech discrimination is robust to degradations in the SFF domain. The proposed NB estimator is compared to four state-of-the-art estimators (one NB and three BB) using detection and accuracy metrics on simulated and real-world data in different reverberation and noise conditions. The results show that in all the environments, the SFF-based NB approach outperforms the state-of-the-art NB approach. Furthermore, the performance of the SFF-based approach is better than some of the BB estimators.
SPRING-INX: A Multilingual Indian Language Speech Corpus by SPRING Lab, IIT Madras
Oct 24, 2023


India is home to a multitude of languages of which 22 languages are recognised by the Indian Constitution as official. Building speech based applications for the Indian population is a difficult problem owing to limited data and the number of languages and accents to accommodate. To encourage the language technology community to build speech based applications in Indian languages, we are open sourcing SPRING-INX data which has about 2000 hours of legally sourced and manually transcribed speech data for ASR system building in Assamese, Bengali, Gujarati, Hindi, Kannada, Malayalam, Marathi, Odia, Punjabi and Tamil. This endeavor is by SPRING Lab , Indian Institute of Technology Madras and is a part of National Language Translation Mission (NLTM), funded by the Indian Ministry of Electronics and Information Technology (MeitY), Government of India. We describe the data collection and data cleaning process along with the data statistics in this paper.
Bayesian multilingual topic model for zero-shot cross-lingual topic identification
Jul 02, 2020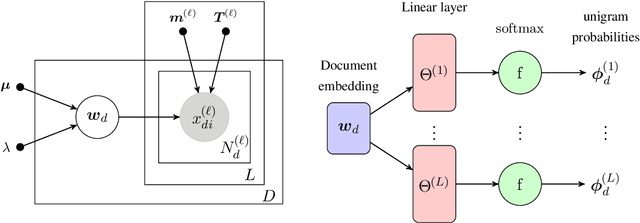


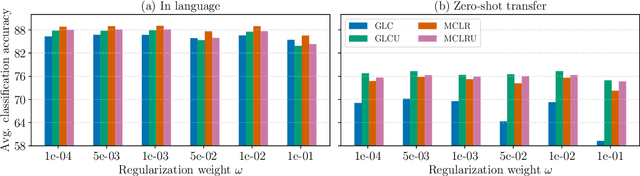
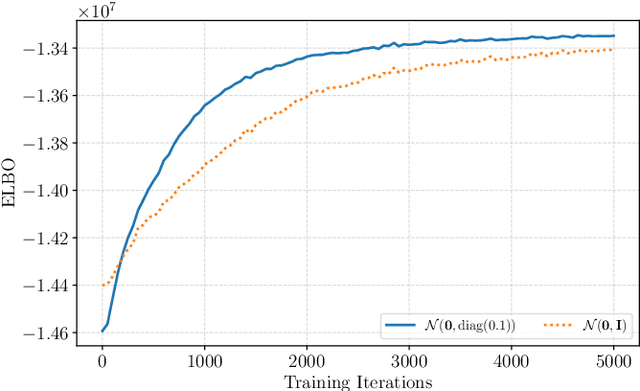
This paper presents a Bayesian multilingual topic model for learning language-independent document embeddings. Our model learns to represent the documents in the form of Gaussian distributions, thereby encoding the uncertainty in its covariance. We propagate the learned uncertainties through linear classifiers for zero-shot cross-lingual topic identification. Our experiments on 5 language Europarl and Reuters (MLDoc) corpora show that the proposed model outperforms multi-lingual word embedding and BiLSTM sentence encoder based systems with significant margins in the majority of the transfer directions. Moreover, our system trained under a single day on a single GPU with much lower amounts of data performs competitively as compared to the state-of-the-art universal BiLSTM sentence encoder trained on 93 languages. Our experimental analysis shows that the amount of parallel data improves the overall performance of embeddings. Nonetheless, exploiting the uncertainties is always beneficial.
Learning document embeddings along with their uncertainties
Aug 29, 2019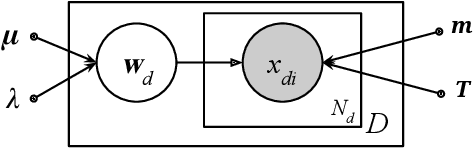
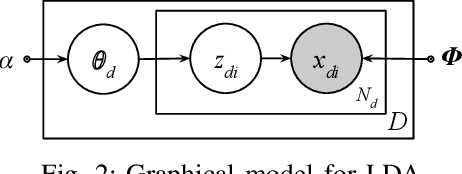
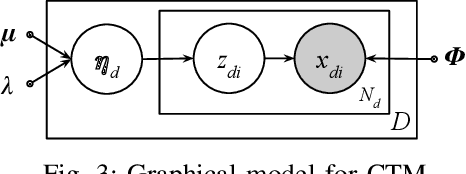
Majority of the text modelling techniques yield only point estimates of document embeddings and lack in capturing the uncertainty of the estimates. These uncertainties give a notion of how well the embeddings represent a document. We present Bayesian subspace multinomial model (Bayesian SMM), a generative log-linear model that learns to represent documents in the form of Gaussian distributions, thereby encoding the uncertainty in its covariance. Additionally, in the proposed Bayesian SMM, we address a commonly encountered problem of intractability that appears during variational inference in mixed-logit models. We also present a generative Gaussian linear classifier for topic identification that exploits the uncertainty in document embeddings. Our intrinsic evaluation using perplexity measure shows that the proposed Bayesian SMM fits the data better as compared to variational auto-encoder based document model. Our topic identification experiments on speech (Fisher) and text (20Newsgroups) corpora show that the proposed Bayesian SMM is robust to over-fitting on unseen test data. The topic ID results show that the proposed model is significantly better than variational auto-encoder based methods and achieve similar results when compared to fully supervised discriminative models.
Statistical Parametric Speech Synthesis Using Bottleneck Representation From Sequence Auto-encoder
Jun 19, 2016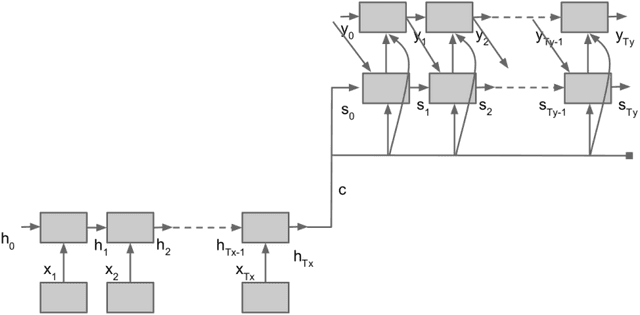
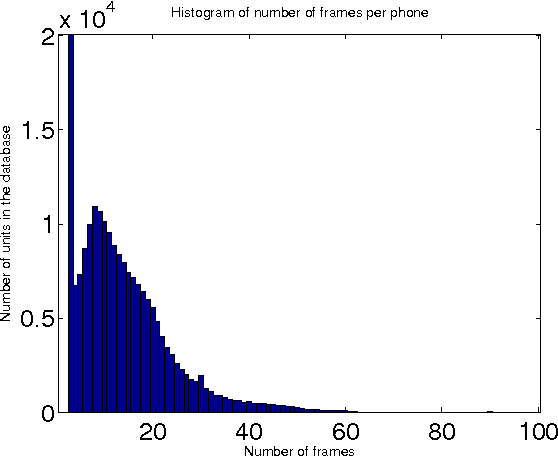
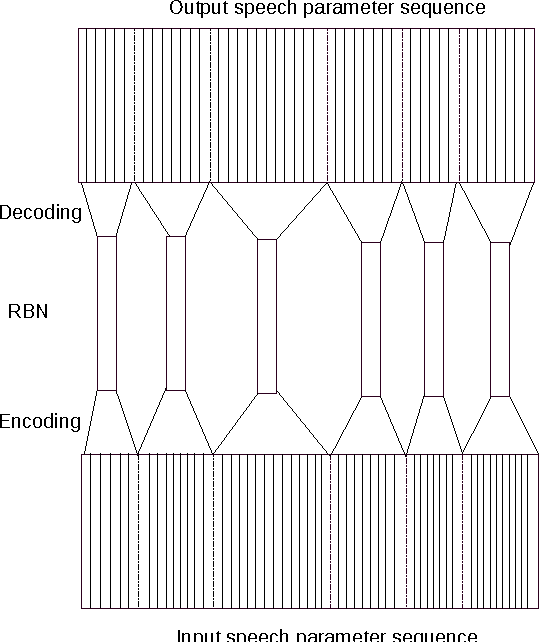
In this paper, we describe a statistical parametric speech synthesis approach with unit-level acoustic representation. In conventional deep neural network based speech synthesis, the input text features are repeated for the entire duration of phoneme for mapping text and speech parameters. This mapping is learnt at the frame-level which is the de-facto acoustic representation. However much of this computational requirement can be drastically reduced if every unit can be represented with a fixed-dimensional representation. Using recurrent neural network based auto-encoder, we show that it is indeed possible to map units of varying duration to a single vector. We then use this acoustic representation at unit-level to synthesize speech using deep neural network based statistical parametric speech synthesis technique. Results show that the proposed approach is able to synthesize at the same quality as the conventional frame based approach at a highly reduced computational cost.